HermesFlow: Seamlessly Closing the Gap in Multimodal Understanding and Generation
作者: Ling Yang, Xinchen Zhang, Ye Tian, Chenming Shang, Minghao Xu, Wentao Zhang, Bin Cui
分类: cs.CV
发布日期: 2025-02-17 (更新: 2025-09-25)
备注: NeurIPS 2025. Code: https://github.com/Gen-Verse/HermesFlow
🔗 代码/项目: GITHUB
💡 一句话要点
HermesFlow:弥合多模态理解与生成能力差距的通用框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大语言模型 图像理解 文本生成 偏好学习 对齐框架 自博弈 Pair-DPO
📋 核心要点
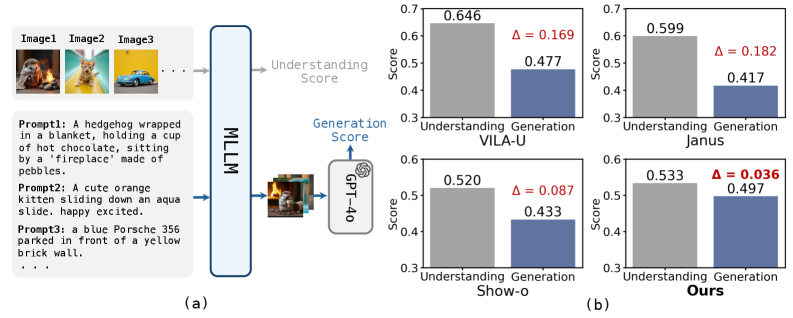
- 现有MLLMs的理解能力普遍强于生成能力,导致多模态任务中性能瓶颈。
- HermesFlow通过同源偏好数据和Pair-DPO优化,对齐理解和生成能力。
- 实验表明,HermesFlow显著缩小了理解和生成之间的差距,优于现有方法。
📝 摘要(中文)
自回归范式在多模态大语言模型(MLLMs)中取得了显著进展,诸如Show-o、Transfusion和Emu3等模型在统一图像理解和生成方面表现出色。然而,我们首次揭示了一个普遍现象:MLLMs的理解能力通常强于其生成能力,两者之间存在显著差距。基于此,我们提出了HermesFlow,一个简单而通用的框架,旨在无缝弥合MLLMs中理解和生成之间的差距。具体而言,我们以同源数据作为输入,精心策划理解和生成的同源偏好数据。通过Pair-DPO和自博弈迭代优化,HermesFlow利用同源偏好数据有效地对齐多模态理解和生成。大量实验表明,我们的方法明显优于现有方法,尤其是在缩小多模态理解和生成之间的差距方面。这些发现突显了HermesFlow作为下一代多模态基础模型的通用对齐框架的潜力。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLMs)中理解能力和生成能力不匹配的问题。现有MLLMs在理解图像内容方面表现良好,但在生成与图像内容相关的文本时,性能往往不如理解能力。这种差距限制了MLLMs在需要理解和生成相结合的任务中的表现。
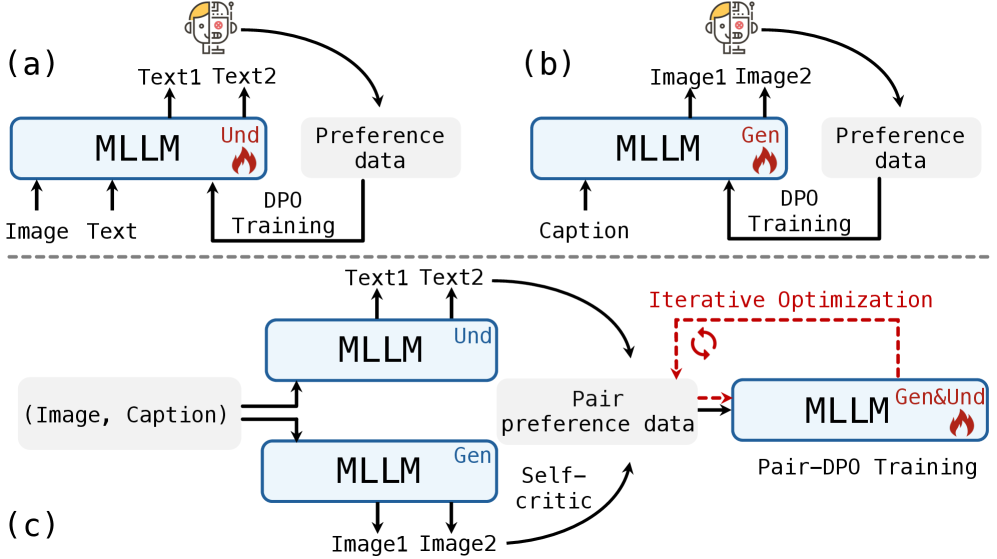
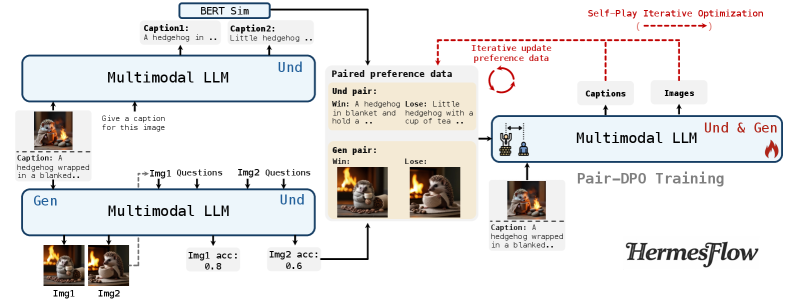
核心思路:论文的核心思路是利用同源数据,即同一场景或对象的不同模态表示(例如,图像和文本描述),来对齐MLLMs的理解和生成能力。通过构建理解和生成的偏好数据集,并使用Pair-DPO(Pairwise Direct Preference Optimization)进行优化,使得模型在理解和生成任务中都能更好地利用多模态信息。
技术框架:HermesFlow框架主要包含以下几个阶段:1) 数据收集:收集同源的多模态数据,包括图像和对应的文本描述。2) 偏好数据生成:利用MLLM生成理解和生成任务的候选输出,并根据人工或自动评估方法对这些输出进行排序,构建偏好数据集。3) 模型训练:使用Pair-DPO算法,基于偏好数据集对MLLM进行微调,使得模型更倾向于生成高质量的输出。4) 自博弈迭代优化:通过模型自身生成数据并进行优化,进一步提升模型的性能。
关键创新:该论文的关键创新在于提出了一个通用的对齐框架HermesFlow,能够有效地弥合MLLMs中理解和生成能力之间的差距。与现有方法相比,HermesFlow更加注重利用同源数据来学习理解和生成之间的对应关系,并通过Pair-DPO算法直接优化模型的偏好,避免了传统方法中复杂的奖励函数设计。
关键设计:HermesFlow的关键设计包括:1) 同源偏好数据的构建方式,确保数据能够反映理解和生成之间的对应关系。2) Pair-DPO算法的使用,能够直接优化模型的偏好,避免了传统强化学习方法中的奖励函数设计问题。3) 自博弈迭代优化策略,能够进一步提升模型的性能。具体的参数设置和网络结构细节取决于所使用的MLLM基础模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,HermesFlow在多个多模态任务上取得了显著的性能提升。例如,在图像描述生成任务中,HermesFlow生成的描述更加准确和流畅,与人工标注的描述更加接近。与现有方法相比,HermesFlow在多个指标上都取得了明显的优势,证明了其有效性。
🎯 应用场景
HermesFlow具有广泛的应用前景,例如图像描述生成、视觉问答、多模态对话系统等。该研究可以提升这些应用中模型生成内容的质量和相关性,使其更符合用户的需求。未来,HermesFlow可以应用于更复杂的场景,例如机器人导航、智能助手等,实现更智能的多模态交互。
📄 摘要(原文)
The remarkable success of the autoregressive paradigm has made significant advancement in Multimodal Large Language Models (MLLMs), with powerful models like Show-o, Transfusion and Emu3 achieving notable progress in unified image understanding and generation. For the first time, we uncover a common phenomenon: the understanding capabilities of MLLMs are typically stronger than their generative capabilities, with a significant gap between the two. Building on this insight, we propose HermesFlow, a simple yet general framework designed to seamlessly bridge the gap between understanding and generation in MLLMs. Specifically, we take the homologous data as input to curate homologous preference data of both understanding and generation. Through Pair-DPO and self-play iterative optimization, HermesFlow effectively aligns multimodal understanding and generation using homologous preference data. Extensive experiments demonstrate the significant superiority of our approach over prior methods, particularly in narrowing the gap between multimodal understanding and generation. These findings highlight the potential of HermesFlow as a general alignment framework for next-generation multimodal foundation models. Code: https://github.com/Gen-Verse/HermesFlow