PRISM: Self-Pruning Intrinsic Selection Method for Training-Free Multimodal Data Selection
作者: Jinhe Bi, Aniri, Yifan Wang, Danqi Yan, Wenke Huang, Zengjie Jin, Xiaowen Ma, Sikuan Yan, Artur Hecker, Mang Ye, Xun Xiao, Hinrich Schuetze, Volker Tresp, Yunpu Ma
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-02-17 (更新: 2026-01-13)
🔗 代码/项目: GITHUB
💡 一句话要点
PRISM:一种免训练的多模态数据自剪枝选择方法,解决视觉特征分布各向异性问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉指令调优 数据选择 自剪枝 特征各向异性
📋 核心要点
- 现有视觉指令数据选择方法计算成本高昂,难以有效应对MLLM训练中数据冗余带来的效率瓶颈。
- PRISM通过隐式重中心化建模内在视觉语义,消除全局背景特征的干扰,从而避免全局语义漂移。
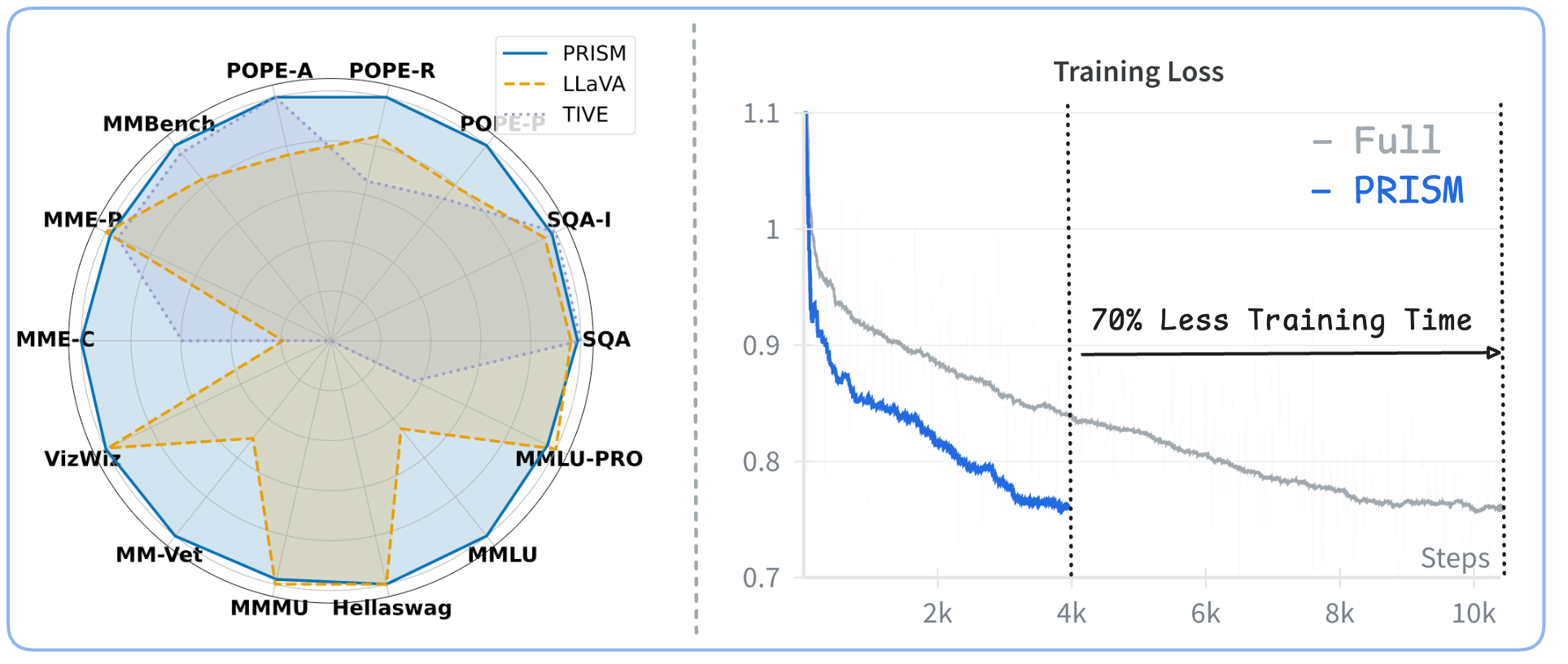
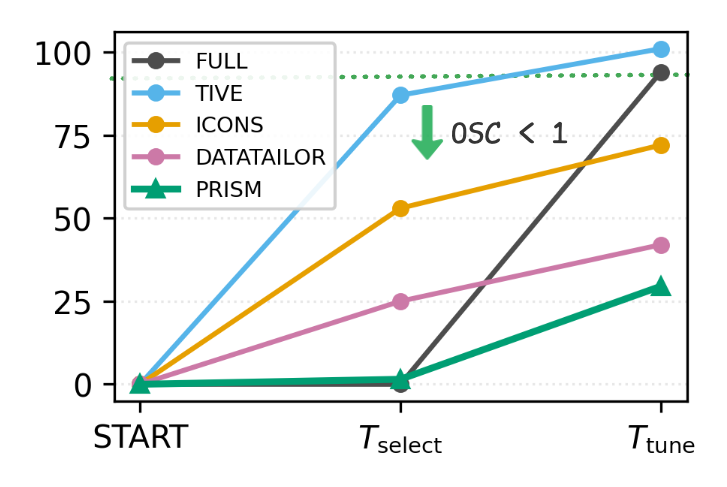
- PRISM在数据选择和模型调优上显著提速,端到端时间缩短至传统流程的30%,并在多个基准测试中超越了全数据集微调的模型。
📝 摘要(中文)
视觉指令调优旨在使预训练的多模态大型语言模型(MLLM)能够遵循人类指令,应用于实际场景。然而,数据集的快速增长带来了显著的冗余,增加了计算成本。现有的指令数据选择方法主要依赖于计算密集型的技术,如基于代理的推理或基于训练的指标,这与提高效率的初衷相悖。为了解决这个问题,我们首先发现了一个关键但先前被忽视的因素:视觉特征分布中固有的各向异性。我们发现这种各向异性会导致“全局语义漂移”,忽略这种现象是限制当前数据选择方法效率的关键因素。基于此,我们设计了PRISM,这是第一个用于高效视觉指令选择的免训练框架。PRISM通过隐式重中心化建模内在视觉语义,从而消除全局背景特征的干扰。实验表明,PRISM将数据选择和模型调优的端到端时间缩短到传统流程的30%。更重要的是,它在提高效率的同时增强了性能,在八个多模态和三个语言理解基准测试中超越了在完整数据集上微调的模型,最终实现了相对于基线101.7%的相对改进。
🔬 方法详解
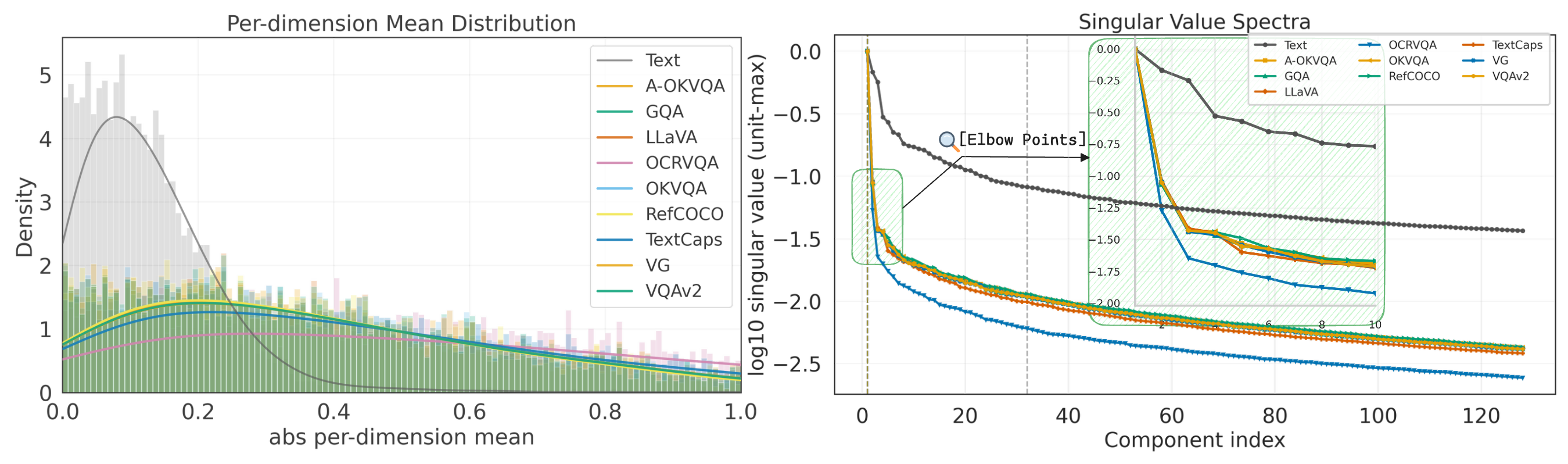
问题定义:论文旨在解决视觉指令调优中,由于数据集冗余导致的计算成本高昂问题。现有数据选择方法依赖于计算密集型的代理推理或基于训练的指标,使得数据选择过程本身成为效率瓶颈。这些方法忽略了视觉特征分布的各向异性,导致全局语义漂移,影响了数据选择的准确性和效率。
核心思路:PRISM的核心思路是通过建模内在视觉语义,消除全局背景特征的干扰,从而避免全局语义漂移。具体来说,它通过隐式重中心化来校正视觉特征分布,使其更加集中于关键语义信息,从而提高数据选择的效率和准确性。这种方法无需训练,避免了额外的计算开销。
技术框架:PRISM框架主要包含以下步骤:1) 提取视觉特征;2) 通过隐式重中心化校正视觉特征分布,建模内在视觉语义;3) 基于校正后的特征选择最具代表性的数据子集。整个流程无需训练,可以直接应用于原始数据集。
关键创新:PRISM最重要的创新在于提出了基于视觉特征分布各向异性的数据选择方法,并设计了免训练的隐式重中心化策略。与现有方法相比,PRISM无需代理模型或训练过程,从而显著降低了计算成本,同时提高了数据选择的准确性。
关键设计:PRISM的关键设计在于隐式重中心化策略。具体实现细节未知,但核心思想是通过某种变换,将视觉特征分布的中心移动到更具代表性的位置,从而消除全局背景特征的干扰。论文中没有明确给出具体的参数设置或损失函数,但强调了该方法的免训练特性。
🖼️ 关键图片
📊 实验亮点
PRISM在数据选择和模型调优的端到端时间上,相比传统流程缩短至30%。同时,在八个多模态和三个语言理解基准测试中,PRISM超越了在完整数据集上微调的模型,实现了相对于基线101.7%的相对改进。这些结果表明PRISM在效率和性能上都具有显著优势。
🎯 应用场景
PRISM可应用于各种多模态学习场景,尤其是在视觉指令调优领域,能够有效降低数据冗余带来的计算成本,提高模型训练效率。该方法具有广泛的应用前景,可以加速MLLM在机器人、自动驾驶、智能助手等领域的部署。
📄 摘要(原文)
Visual instruction tuning adapts pre-trained Multimodal Large Language Models (MLLMs) to follow human instructions for real-world applications. However, the rapid growth of these datasets introduces significant redundancy, leading to increased computational costs. Existing methods for selecting instruction data aim to prune this redundancy, but predominantly rely on computationally demanding techniques such as proxy-based inference or training-based metrics. Consequently, the substantial computational costs incurred by these selection processes often exacerbate the very efficiency bottlenecks they are intended to resolve, posing a significant challenge to the scalable and effective tuning of MLLMs. To address this challenge, we first identify a critical, yet previously overlooked, factor: the anisotropy inherent in visual feature distributions. We find that this anisotropy induces a \textit{Global Semantic Drift}, and overlooking this phenomenon is a key factor limiting the efficiency of current data selection methods. Motivated by this insight, we devise \textbf{PRISM}, the first training-free framework for efficient visual instruction selection. PRISM surgically removes the corrupting influence of global background features by modeling the intrinsic visual semantics via implicit re-centering. Empirically, PRISM reduces the end-to-end time for data selection and model tuning to just 30\% of conventional pipelines. More remarkably, it achieves this efficiency while simultaneously enhancing performance, surpassing models fine-tuned on the full dataset across eight multimodal and three language understanding benchmarks, culminating in a 101.7\% relative improvement over the baseline. The code is available for access via \href{https://github.com/bibisbar/PRISM}{this repository}.