Defining and Evaluating Visual Language Models' Basic Spatial Abilities: A Perspective from Psychometrics
作者: Wenrui Xu, Dalin Lyu, Weihang Wang, Jie Feng, Chen Gao, Yong Li
分类: cs.CV, cs.CL
发布日期: 2025-02-17 (更新: 2025-02-20)
期刊: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics. Volume 1: Long Papers (2025) 11571-11590
DOI: 10.18653/v1/2025.acl-long.567
💡 一句话要点
构建心理测量框架,评估视觉语言模型的基本空间能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 空间智能 心理测量学 具身智能 空间能力评估
📋 核心要点
- 现有VLM在空间智能方面存在不足,缺乏系统性的评估框架来诊断其空间能力。
- 论文提出一个基于心理测量的框架,定义了五种基本空间能力,并设计实验进行评估。
- 实验表明VLM在空间能力上与人类存在差距,并揭示了模型架构和训练策略的局限性。
📝 摘要(中文)
本文从心理测量的角度出发,定义了视觉语言模型(VLM)的五种基本空间能力(BSA):空间感知、空间关系、空间定向、心理旋转和空间可视化。通过九个经过验证的心理测量实验,对13个主流VLM进行了基准测试,结果表明VLM与人类之间存在显著差距(平均分24.95 vs. 68.38)。研究发现:1) VLM反映了人类的空间能力层级结构(2D定向能力最强,3D旋转能力最弱),且BSA之间相互独立(Pearson's r<0.4);2) 较小的模型(如Qwen2-VL-7B)优于较大的模型,其中Qwen表现最佳(30.82),InternVL2表现最差(19.6);3) 思维链(CoT)和少量样本学习等干预措施的提升有限,表明存在架构约束。研究识别了VLM在几何编码方面的不足以及缺乏动态模拟能力等障碍。通过将心理测量的BSA与VLM能力联系起来,本文为空间智能评估提供了一个诊断工具包,为具身AI开发提供了方法论基础,并为实现类人空间智能提供了一个认知科学指导的路线图。
🔬 方法详解
问题定义:现有视觉语言模型(VLM)在处理空间信息时表现出明显的局限性,缺乏对基本空间能力的有效评估和诊断。现有方法难以系统性地分析VLM在空间感知、关系理解、方向判断、心理旋转和空间可视化等方面的能力,阻碍了具身智能和空间人工智能的发展。
核心思路:论文借鉴心理测量学理论,将人类认知中的基本空间能力(BSA)概念引入VLM评估。通过定义五种关键的BSA,并设计相应的心理测量实验,旨在量化VLM在不同空间能力上的表现,从而诊断其优势和不足。这种方法能够更细粒度地理解VLM的空间智能水平,并为未来的模型改进提供指导。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 定义五种基本空间能力(BSA):空间感知、空间关系、空间定向、心理旋转和空间可视化。2) 设计九个心理测量实验,每个实验针对特定的BSA进行评估。3) 选择13个主流VLM进行基准测试,包括不同尺寸和架构的模型。4) 采用心理测量学的评分标准和统计方法,量化VLM在每个实验中的表现。5) 分析实验结果,比较不同VLM之间的性能差异,并与人类表现进行对比。6) 探索思维链(CoT)和少量样本学习等干预措施对VLM空间能力的影响。
关键创新:该研究的关键创新在于:1) 将心理测量学理论应用于VLM评估,提出了一个系统性的空间能力评估框架。2) 定义了五种基本空间能力(BSA),为VLM的空间智能研究提供了一个清晰的概念体系。3) 通过大量的实验,揭示了VLM在不同BSA上的性能差异,并发现了模型架构和训练策略的局限性。4) 该研究为具身智能和空间人工智能的发展提供了一个诊断工具包和方法论基础。
关键设计:在实验设计方面,论文参考了心理学中经典的心理测量实验,并针对VLM的特点进行了调整。例如,在心理旋转实验中,使用了3D物体图像,并要求VLM判断旋转后的物体是否与原始物体相同。在空间关系实验中,使用了包含多个物体的图像,并要求VLM描述物体之间的空间关系。在模型训练方面,论文探索了思维链(CoT)和少量样本学习等方法,以提高VLM的空间能力。此外,论文还分析了不同模型架构对空间能力的影响,例如Transformer架构和卷积神经网络架构。
🖼️ 关键图片

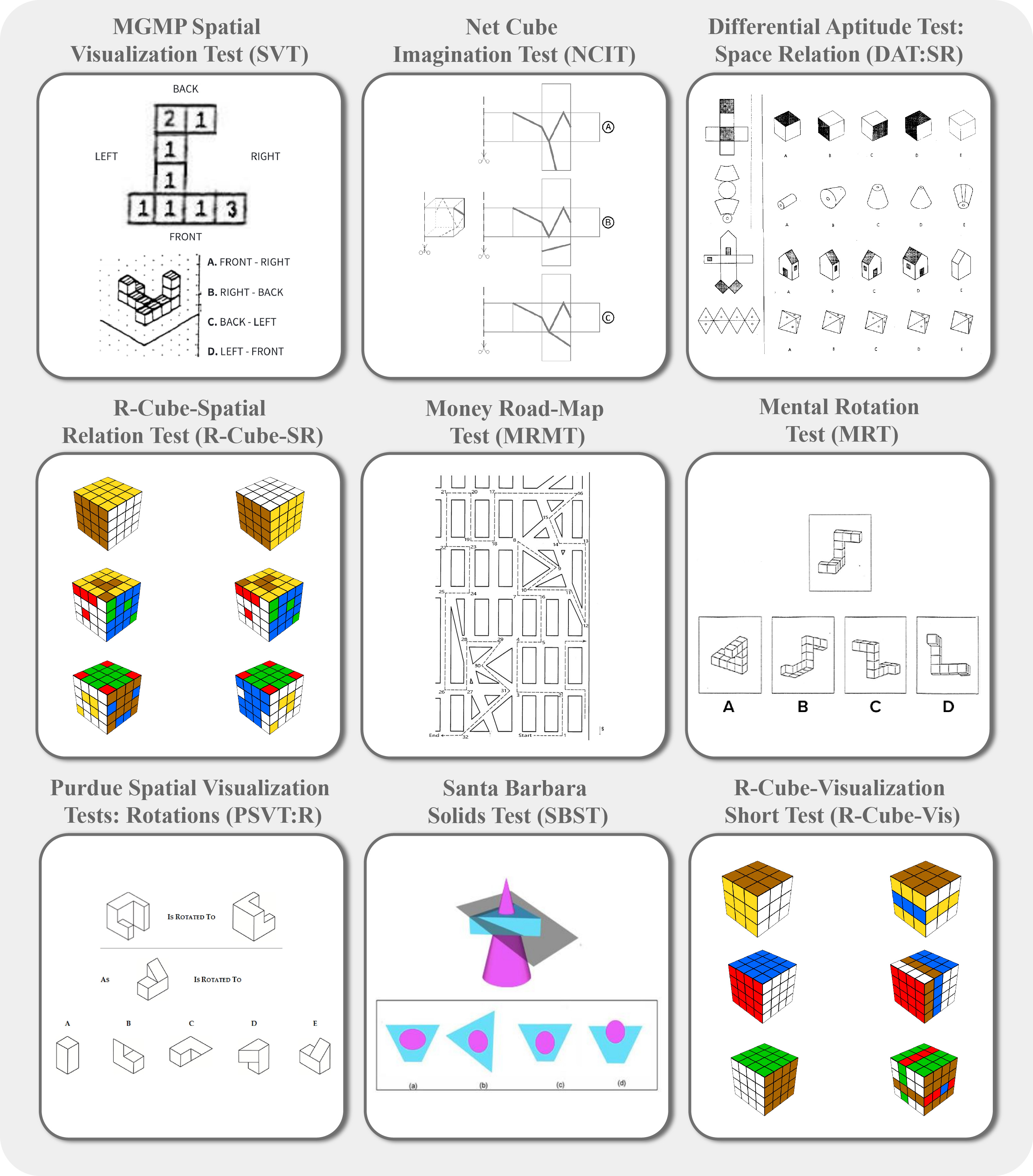

📊 实验亮点
实验结果表明,VLM在空间能力方面与人类存在显著差距(平均分24.95 vs. 68.38)。较小的模型如Qwen2-VL-7B (30.82) 优于较大的模型,如InternVL2 (19.6)。思维链(CoT)和少量样本学习等干预措施对VLM空间能力的提升有限,表明存在架构约束。这些结果揭示了VLM在空间智能方面的局限性,并为未来的模型改进提供了方向。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、增强现实等领域。通过提升VLM的空间智能,可以使机器人更好地理解周围环境,实现更精确的定位和导航。在自动驾驶领域,可以提高车辆对交通场景的理解和预测能力,从而提高驾驶安全性。在增强现实领域,可以实现更自然的虚拟物体与现实世界的融合。
📄 摘要(原文)
The Theory of Multiple Intelligences underscores the hierarchical nature of cognitive capabilities. To advance Spatial Artificial Intelligence, we pioneer a psychometric framework defining five Basic Spatial Abilities (BSAs) in Visual Language Models (VLMs): Spatial Perception, Spatial Relation, Spatial Orientation, Mental Rotation, and Spatial Visualization. Benchmarking 13 mainstream VLMs through nine validated psychometric experiments reveals significant gaps versus humans (average score 24.95 vs. 68.38), with three key findings: 1) VLMs mirror human hierarchies (strongest in 2D orientation, weakest in 3D rotation) with independent BSAs (Pearson's r<0.4); 2) Smaller models such as Qwen2-VL-7B surpass larger counterparts, with Qwen leading (30.82) and InternVL2 lagging (19.6); 3) Interventions like chain-of-thought (0.100 accuracy gain) and 5-shot training (0.259 improvement) show limits from architectural constraints. Identified barriers include weak geometry encoding and missing dynamic simulation. By linking psychometric BSAs to VLM capabilities, we provide a diagnostic toolkit for spatial intelligence evaluation, methodological foundations for embodied AI development, and a cognitive science-informed roadmap for achieving human-like spatial intelligence.