Intuitive physics understanding emerges from self-supervised pretraining on natural videos
作者: Quentin Garrido, Nicolas Ballas, Mahmoud Assran, Adrien Bardes, Laurent Najman, Michael Rabbat, Emmanuel Dupoux, Yann LeCun
分类: cs.CV, cs.AI
发布日期: 2025-02-17
备注: 24 pages,14 figures, 5 tables
💡 一句话要点
利用自然视频自监督预训练,模型涌现直观物理理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 直观物理 自监督学习 视频预测 表征学习 预测编码
📋 核心要点
- 现有方法在理解直观物理方面存在不足,尤其是在通用模型中,难以有效学习和推理物理世界的规则。
- 该论文提出通过在自然视频上进行自监督预训练,让模型学习预测掩码区域,从而涌现对直观物理的理解。
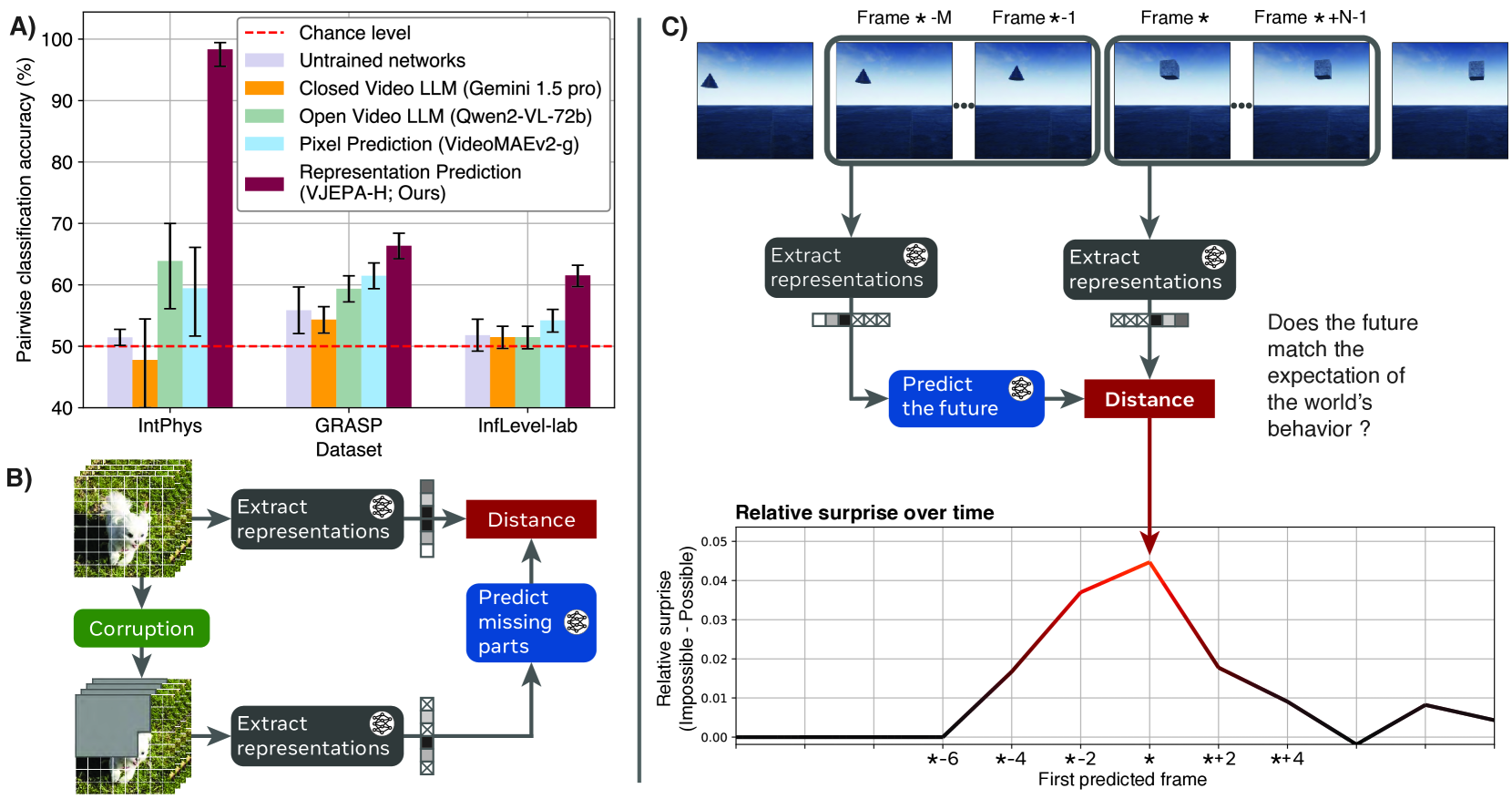
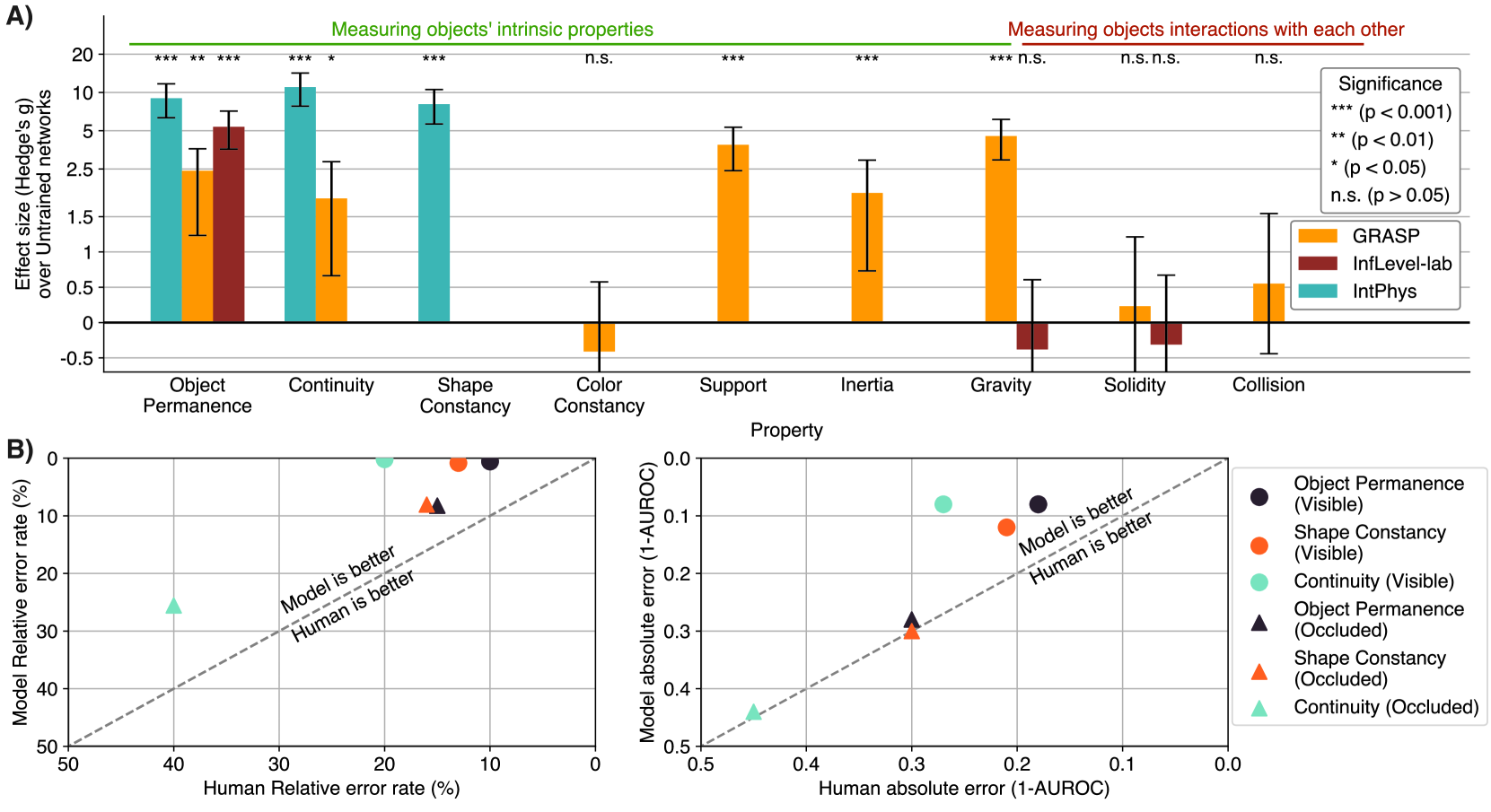
- 实验表明,在学习到的表征空间中进行视频预测的模型,能够理解物体永存性和形状一致性等物理属性,性能优于像素空间预测和多模态LLM。
📝 摘要(中文)
本文研究了通用深度神经网络模型在自然视频上进行掩码区域预测的自监督预训练后,涌现的直观物理理解能力。利用违反期望框架,我们发现,在学习到的表征空间中进行视频预测的模型,展现出对各种直观物理属性的理解,例如物体永存性和形状一致性。相比之下,在像素空间中进行视频预测以及通过文本进行推理的多模态大型语言模型,其性能接近于随机水平。这些架构的比较表明,联合学习抽象表征空间并预测感官输入的缺失部分(类似于预测编码),足以获得对直观物理的理解,即使是仅在一周的独特视频上训练的模型也能达到高于随机水平的性能。这挑战了核心知识——一套帮助理解世界的先天系统——需要硬连接才能发展对直观物理的理解的观点。
🔬 方法详解
问题定义:论文旨在研究通用深度神经网络模型是否可以通过自监督学习,从自然视频中学习到直观物理知识。现有方法,如直接在像素空间进行预测,或者依赖文本推理的多模态模型,在理解直观物理方面表现不佳,无法有效捕捉视频中的物理规律。
核心思路:论文的核心思路是利用预测编码的思想,通过让模型预测视频中被掩盖的部分,迫使模型学习视频中潜在的物理规则和物体属性。这种自监督学习方式旨在让模型在学习表征空间的同时,理解直观物理,而无需显式的物理知识标注。
技术框架:整体框架包括一个视频编码器,用于将视频帧编码到学习到的表征空间;一个预测模块,用于预测被掩盖的视频区域在该表征空间中的表示;以及一个解码器,用于将预测的表征解码回像素空间(可选,主要用于可视化和评估)。训练过程中,模型通过最小化预测误差来学习。
关键创新:该论文的关键创新在于证明了通过简单的自监督视频预测任务,模型可以涌现出对直观物理的理解。与以往需要特定物理引擎或人工标注数据的方法不同,该方法仅依赖于自然视频,更具通用性和可扩展性。此外,论文还对比了不同架构(像素空间预测、多模态LLM)的表现,突出了学习抽象表征空间的重要性。
关键设计:论文中,视频编码器和解码器可以使用各种卷积神经网络或Transformer架构。预测模块可以是简单的线性层或更复杂的循环神经网络。损失函数通常采用均方误差或交叉熵损失,用于衡量预测结果与真实值之间的差异。掩码策略可以采用随机掩码或基于语义分割的掩码。
🖼️ 关键图片
📊 实验亮点
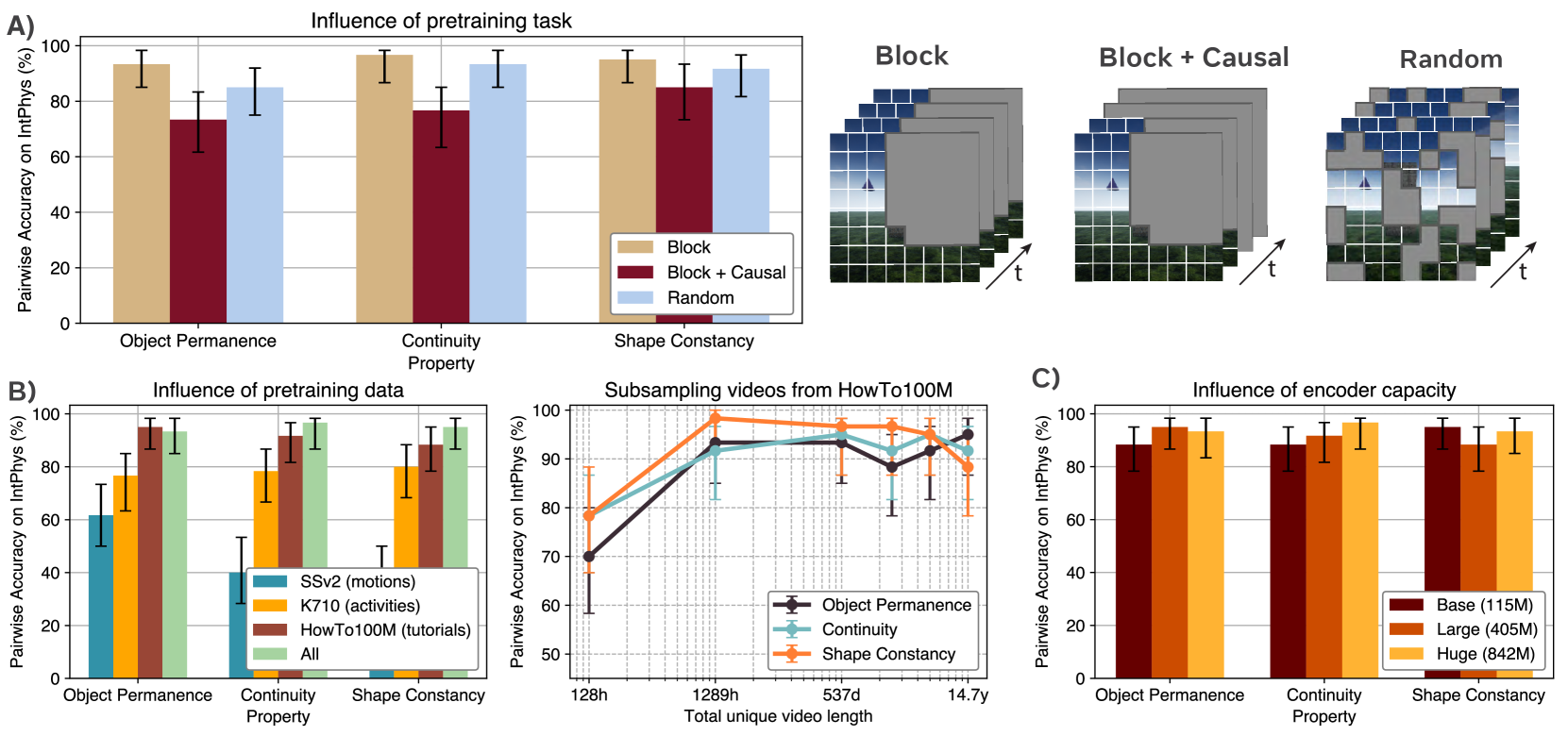
实验结果表明,在学习到的表征空间中进行视频预测的模型,在物体永存性和形状一致性测试中表现显著优于随机水平,并且优于在像素空间中进行预测的模型以及多模态大型语言模型。即使仅使用一周的独特视频进行训练,模型也能达到高于随机水平的性能,这表明自监督学习在获取直观物理理解方面的有效性。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、视频游戏等领域,使智能体能够更好地理解和预测物理世界的行为。通过学习直观物理,智能体可以更有效地与环境交互,并做出更合理的决策。此外,该研究也为开发更通用、更智能的AI系统提供了新的思路。
📄 摘要(原文)
We investigate the emergence of intuitive physics understanding in general-purpose deep neural network models trained to predict masked regions in natural videos. Leveraging the violation-of-expectation framework, we find that video prediction models trained to predict outcomes in a learned representation space demonstrate an understanding of various intuitive physics properties, such as object permanence and shape consistency. In contrast, video prediction in pixel space and multimodal large language models, which reason through text, achieve performance closer to chance. Our comparisons of these architectures reveal that jointly learning an abstract representation space while predicting missing parts of sensory input, akin to predictive coding, is sufficient to acquire an understanding of intuitive physics, and that even models trained on one week of unique video achieve above chance performance. This challenges the idea that core knowledge -- a set of innate systems to help understand the world -- needs to be hardwired to develop an understanding of intuitive physics.