video-SALMONN-o1: Reasoning-enhanced Audio-visual Large Language Model
作者: Guangzhi Sun, Yudong Yang, Jimin Zhuang, Changli Tang, Yixuan Li, Wei Li, Zejun MA, Chao Zhang
分类: cs.CV
发布日期: 2025-02-17
💡 一句话要点
提出video-SALMONN-o1,首个面向通用视频理解的推理增强型音视频大语言模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频理解 大语言模型 推理增强 音视频融合 过程直接偏好优化 多模态学习 RivaBench 合成视频检测
📋 核心要点
- 现有大语言模型推理能力的提升主要集中在数学问题和视觉图形输入,忽略了通用视频理解中的更广泛应用。
- 论文提出video-SALMONN-o1,通过构建推理密集型数据集和设计过程直接偏好优化(pDPO)方法来增强模型的推理能力。
- 实验结果表明,video-SALMONN-o1在多个视频推理基准上优于基线模型,并在RivaBench上取得了显著的性能提升。
📝 摘要(中文)
本文提出了video-SALMONN-o1,这是首个开源的、推理增强的音视频大语言模型,专为通用视频理解任务设计。为了提升其推理能力,我们构建了一个推理密集型数据集,其中包含具有逐步解决方案的、具有挑战性的音视频问题。此外,我们提出了过程直接偏好优化(pDPO),它利用对比步骤选择来实现针对多模态输入的有效步骤级奖励建模。我们还引入了RivaBench,这是首个推理密集型视频理解基准,包含超过4000个高质量、专家策划的问答对,涵盖单口喜剧、学术报告和合成视频检测等场景。在不同的视频推理基准测试中,video-SALMONN-o1比LLaVA-OneVision基线提高了3-8%的准确率。此外,pDPO在RivaBench上比监督微调模型提高了6-8%。增强的推理能力使video-SALMONN-o1具备了零样本合成视频检测能力。
🔬 方法详解
问题定义:现有的大语言模型在推理能力上的提升主要集中在数学问题和视觉图形输入,缺乏对通用视频理解任务的有效支持。现有的方法难以处理需要复杂推理步骤的音视频数据,并且缺乏专门为此类任务设计的训练数据和优化方法。
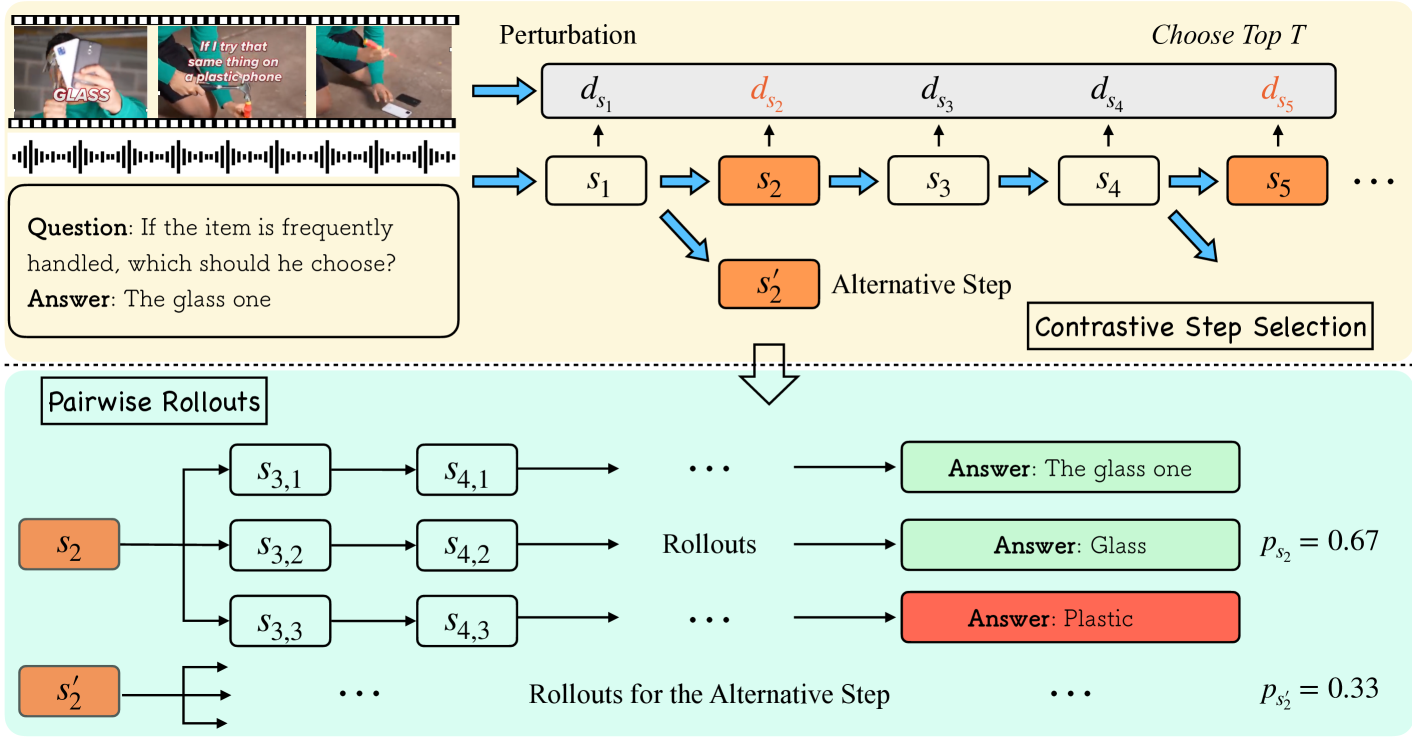
核心思路:论文的核心思路是通过构建一个推理密集型的数据集,并设计一种新的训练方法(pDPO),来提升大语言模型在音视频理解任务中的推理能力。通过逐步的解决方案和对比步骤选择,模型能够学习到更有效的推理策略。
技术框架:video-SALMONN-o1的整体框架基于大语言模型,并结合了音视频特征提取模块。首先,音视频数据经过特征提取器得到相应的特征表示。然后,这些特征被输入到大语言模型中进行推理和预测。关键在于,训练过程中使用了推理密集型数据集和pDPO优化方法。
关键创新:论文的关键创新在于提出了过程直接偏好优化(pDPO),这是一种针对多模态输入的步骤级奖励建模方法。与传统的监督微调相比,pDPO能够更有效地利用对比步骤选择的信息,从而提升模型的推理能力。此外,RivaBench基准的提出也为该领域的研究提供了新的评估标准。
关键设计:pDPO方法通过对比不同的推理步骤,并根据其对最终结果的贡献程度来调整模型的参数。具体的损失函数设计未知,但其核心思想是最大化正确推理步骤的概率,同时最小化错误推理步骤的概率。数据集RivaBench包含超过4000个高质量的问答对,涵盖了多种视频场景,为模型的训练和评估提供了丰富的数据。
🖼️ 关键图片


📊 实验亮点
video-SALMONN-o1在不同的视频推理基准测试中,比LLaVA-OneVision基线提高了3-8%的准确率。更重要的是,pDPO在RivaBench上比监督微调模型提高了6-8%。此外,增强的推理能力使video-SALMONN-o1具备了零样本合成视频检测能力,无需额外训练即可识别合成视频。
🎯 应用场景
该研究成果可应用于多种视频理解场景,如智能视频监控、视频内容分析、教育视频理解、娱乐视频分析等。通过提升模型对视频内容的推理能力,可以实现更精准的视频内容识别、事件检测和行为分析,具有重要的实际应用价值和商业潜力。
📄 摘要(原文)
While recent advancements in reasoning optimization have significantly enhanced the capabilities of large language models (LLMs), existing efforts to improve reasoning have been limited to solving mathematical problems and focusing on visual graphical inputs, neglecting broader applications in general video understanding.This paper proposes video-SALMONN-o1, the first open-source reasoning-enhanced audio-visual LLM designed for general video understanding tasks. To enhance its reasoning abilities, we develop a reasoning-intensive dataset featuring challenging audio-visual questions with step-by-step solutions. We also propose process direct preference optimization (pDPO), which leverages contrastive step selection to achieve efficient step-level reward modelling tailored for multimodal inputs. Additionally, we introduce RivaBench, the first reasoning-intensive video understanding benchmark, featuring over 4,000 high-quality, expert-curated question-answer pairs across scenarios such as standup comedy, academic presentations, and synthetic video detection. video-SALMONN-o1 achieves 3-8% accuracy improvements over the LLaVA-OneVision baseline across different video reasoning benchmarks. Besides, pDPO achieves 6-8% improvements compared to the supervised fine-tuning model on RivaBench. Enhanced reasoning enables video-SALMONN-o1 zero-shot synthetic video detection capabilities.