Exploring the Potential of Encoder-free Architectures in 3D LMMs
作者: Yiwen Tang, Zoey Guo, Zhuhao Wang, Ray Zhang, Qizhi Chen, Junli Liu, Delin Qu, Zhigang Wang, Dong Wang, Bin Zhao, Xuelong Li
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-02-13 (更新: 2025-12-08)
🔗 代码/项目: GITHUB
💡 一句话要点
提出ENEL:首个无编码器的3D大语言模型,提升3D场景理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D大语言模型 无编码器架构 点云处理 多模态学习 语义编码 几何聚合 指令调优
📋 核心要点
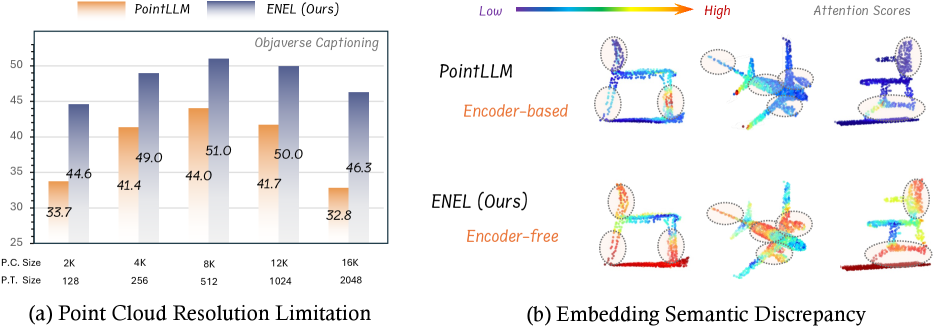
- 现有3D LMMs依赖编码器,面临点云分辨率适应性和特征语义不足的挑战。
- 提出ENEL,一种无编码器的3D LMM,通过LLM嵌入的语义编码和分层几何聚合实现。
- ENEL 7B模型在分类、描述和VQA任务上与PointLLM-PiSA-13B 13B模型性能相当,验证了无编码器架构的潜力。
📝 摘要(中文)
本文首次全面研究了无编码器架构在缓解基于编码器的3D大语言模型(LMMs)挑战方面的潜力。这些长期存在的挑战包括推理过程中无法适应不同的点云分辨率,以及来自编码器的点特征无法满足大语言模型(LLMs)的语义需求。我们确定了3D LMMs移除预训练编码器并使LLM承担3D编码器角色的关键方面:1) 在预训练阶段,我们提出了LLM嵌入的语义编码策略,探索了各种点云自监督损失的影响,并提出了混合语义损失来提取高层语义。2) 在指令调优阶段,我们引入了分层几何聚合策略,将归纳偏置融入LLM层,以关注点云的局部细节。最终,我们提出了第一个无编码器的3D LMM,ENEL。我们的7B模型与最先进的模型PointLLM-PiSA-13B相媲美,在分类、描述和VQA任务上分别实现了57.91%、61.0%和55.20%。结果表明,无编码器架构在3D理解领域非常有希望取代基于编码器的架构。
🔬 方法详解
问题定义:现有基于编码器的3D LMMs存在两个主要问题。一是难以适应不同分辨率的点云输入,因为预训练的编码器通常对特定分辨率的点云表现最佳。二是编码器提取的点特征可能无法很好地满足LLM的语义需求,导致下游任务性能受限。因此,如何设计一个能够直接处理点云数据并生成高质量语义特征的3D LMM是一个关键挑战。
核心思路:本文的核心思路是移除预训练的3D点云编码器,让LLM直接承担3D特征编码的任务。通过精心设计的预训练和指令调优策略,使LLM能够从原始点云数据中学习到丰富的语义信息,并将其用于下游任务。这种方法避免了编码器带来的分辨率适应性和语义鸿沟问题。
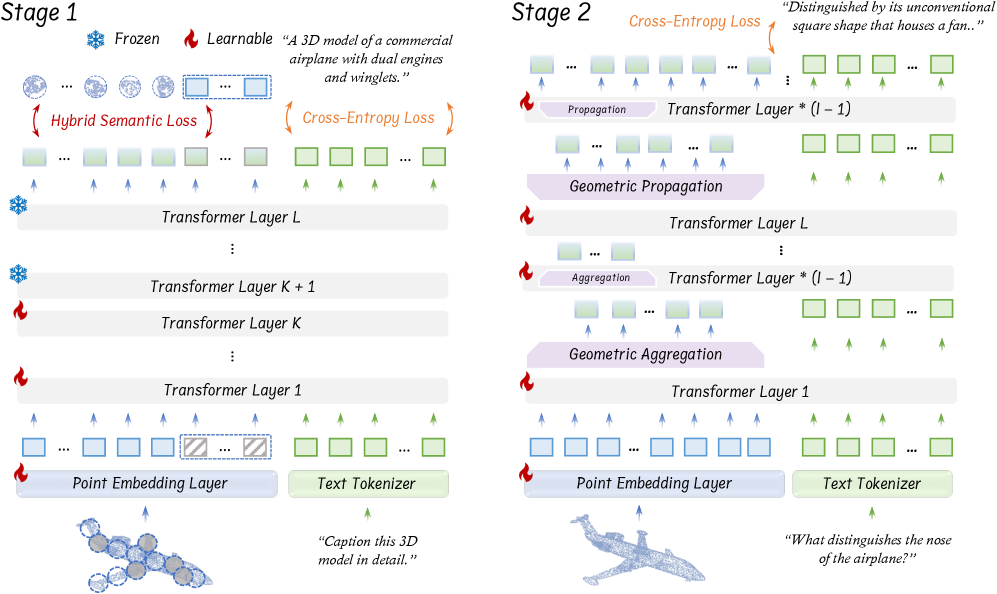
技术框架:ENEL的整体框架包括两个主要阶段:预训练阶段和指令调优阶段。在预训练阶段,使用LLM嵌入的语义编码策略,通过不同的点云自监督损失函数来训练LLM,使其能够理解点云的结构和语义信息。同时,提出混合语义损失,进一步提升LLM提取高层语义的能力。在指令调优阶段,引入分层几何聚合策略,将归纳偏置融入LLM层,使其能够关注点云的局部细节。
关键创新:ENEL最重要的创新点在于其无编码器的架构设计。与传统的基于编码器的3D LMMs不同,ENEL直接利用LLM来处理点云数据,避免了编码器带来的限制。此外,LLM嵌入的语义编码策略和分层几何聚合策略也是关键创新,它们分别提升了LLM的语义理解能力和局部细节感知能力。
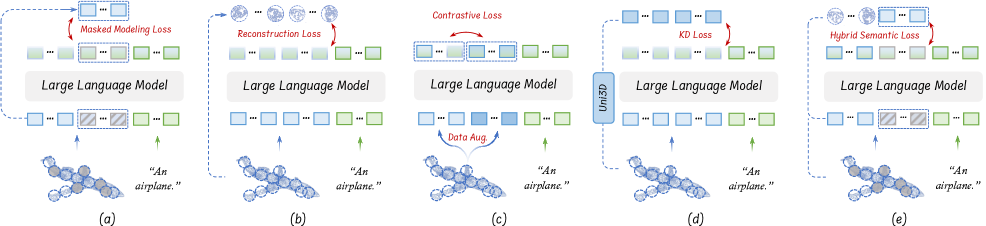
关键设计:在预训练阶段,探索了多种点云自监督损失函数,包括对比学习损失、掩码点云建模损失等。混合语义损失结合了多种损失函数,以提取更全面的语义信息。在指令调优阶段,分层几何聚合策略通过多层Transformer层来逐步聚合局部几何信息,每一层关注不同尺度的局部区域。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
ENEL 7B模型在分类、描述和VQA任务上分别取得了57.91%、61.0%和55.20%的性能,与state-of-the-art的PointLLM-PiSA-13B模型性能相当,甚至在某些任务上有所超越。这表明无编码器架构在3D LMMs领域具有巨大的潜力,能够有效提升3D场景理解能力。
🎯 应用场景
该研究成果可广泛应用于机器人导航、自动驾驶、三维场景理解、虚拟现实等领域。无编码器架构降低了模型对特定点云分辨率的依赖,使其在实际应用中更具灵活性和鲁棒性。未来,该方法有望推动3D视觉与自然语言处理的深度融合,实现更智能化的3D场景理解和交互。
📄 摘要(原文)
Encoder-free architectures have been preliminarily explored in the 2D Large Multimodal Models (LMMs), yet it remains an open question whether they can be effectively applied to 3D understanding scenarios. In this paper, we present the first comprehensive investigation into the potential of encoder-free architectures to alleviate the challenges of encoder-based 3D LMMs. These long-standing challenges include the failure to adapt to varying point cloud resolutions during inference and the point features from the encoder not meeting the semantic needs of Large Language Models (LLMs). We identify key aspects for 3D LMMs to remove the pre-trained encoder and enable the LLM to assume the role of the 3D encoder: 1) We propose the LLM-embedded Semantic Encoding strategy in the pre-training stage, exploring the effects of various point cloud self-supervised losses. And we present the Hybrid Semantic Loss to extract high-level semantics. 2) We introduce the Hierarchical Geometry Aggregation strategy in the instruction tuning stage. This incorporates inductive bias into the LLM layers to focus on the local details of the point clouds. To the end, we present the first Encoder-free 3D LMM, ENEL. Our 7B model rivals the state-of-the-art model, PointLLM-PiSA-13B, achieving 57.91%, 61.0%, and 55.20% on the classification, captioning, and VQA tasks, respectively. Our results show that the encoder-free architecture is highly promising for replacing encoder-based architectures in the field of 3D understanding. The code is released at https://github.com/Ivan-Tang-3D/ENEL