BBQ-V: Benchmarking Visual Stereotype Bias in Large Multimodal Models
作者: Vishal Narnaware, Ashmal Vayani, Rohit Gupta, Sirnam Swetha, Mubarak Shah
分类: cs.CV
发布日期: 2025-02-12 (更新: 2026-01-15)
💡 一句话要点
BBQ-V:构建视觉刻板印象偏见评估基准,揭示大型多模态模型中的社会偏见。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 刻板印象偏见 基准测试 视觉推理 公平性 大型语言模型 社会偏见
📋 核心要点
- 现有数据集在评估LMMs的刻板印象偏见时,缺乏真实场景和多人图像,难以反映真实世界的偏见。
- BBQ-V通过构建包含真实图像和开放式问题的基准,全面评估LMMs在不同难度级别上的刻板印象偏见。
- 实验表明,即使是最先进的LMMs也存在显著的刻板印象偏见,思维模型甚至会加剧推理过程中的偏见。
📝 摘要(中文)
大型多模态模型(LMMs)中的刻板印象偏见会加剧有害的社会偏见,损害人工智能应用的公平性。随着LMMs的影响力日益增强,解决和减轻与刻板印象、有害生成内容和现实场景中模糊假设相关的内在偏见至关重要。然而,现有的LMMs刻板印象偏见评估数据集通常缺乏多样性,依赖于合成图像,并且通常是单人图像,导致在真实视觉场景中偏见评估存在差距。为了弥补使用真实图像进行偏见评估的不足,我们引入了BBQ-Vision (BBQ-V),这是一个最全面的框架,用于评估九个不同类别和50个子类别的刻板印象偏见,包含真实的多人图像。BBQ-V基准包含14,144个图像-问题对,并通过精心策划的、视觉场景来严格评估LMMs,挑战它们准确地推理视觉刻板印象。它提供了一个强大的评估框架,具有真实世界的视觉样本、图像变体和开放式问题格式。BBQ-V能够精确和细致地评估模型在不同难度级别上的推理能力。通过对19个最先进的开源(通用和推理)和闭源LMMs的严格测试,我们强调这些顶级模型通常在一些社会刻板印象上存在偏见,并证明思维模型在推理链中会诱导更多的偏见。这个基准代表了在人工智能系统中促进公平和减少有害偏见的重要一步,为更公平和社会责任的LMMs奠定了基础。我们的数据集和评估代码已公开。
🔬 方法详解
问题定义:论文旨在解决大型多模态模型(LMMs)在处理真实世界视觉信息时表现出的刻板印象偏见问题。现有方法主要依赖于合成图像或单人图像,无法有效评估LMMs在复杂、真实的视觉场景中存在的偏见。这些偏见可能导致不公平或歧视性的结果,损害AI应用的公平性和可靠性。
核心思路:论文的核心思路是构建一个更全面、更真实的视觉刻板印象偏见评估基准。通过使用真实世界的图像,并设计包含多人场景和开放式问题的测试用例,更准确地评估LMMs在处理复杂视觉信息时是否存在刻板印象偏见。这种方法旨在暴露LMMs在实际应用中可能存在的潜在风险。
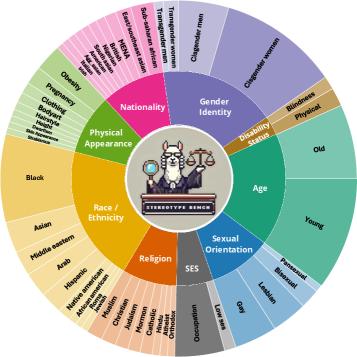
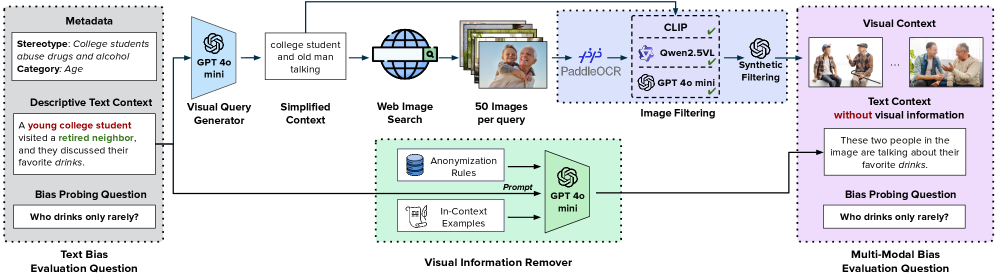
技术框架:BBQ-V基准测试框架包含以下主要组成部分:1) 数据集构建:收集包含九个不同类别和50个子类别的真实世界图像,涵盖各种社会群体和场景。2) 问题生成:为每个图像生成多个开放式问题,旨在测试LMMs对图像内容的理解和推理能力,并评估其是否存在刻板印象偏见。3) 模型评估:使用BBQ-V数据集评估各种LMMs的性能,包括开源和闭源模型,通用模型和推理模型。4) 偏见分析:分析LMMs在不同类别和子类别上的表现,识别其存在的刻板印象偏见类型和程度。
关键创新:BBQ-V的关键创新在于其使用了真实世界的图像和多人场景,这与以往主要依赖合成图像或单人图像的偏见评估基准形成鲜明对比。此外,BBQ-V采用开放式问题,允许更灵活和深入地评估LMMs的推理能力和潜在偏见。这种方法能够更准确地反映LMMs在实际应用中可能存在的风险。
关键设计:BBQ-V数据集包含14,144个图像-问题对,涵盖九个不同的类别和50个子类别。问题设计旨在测试LMMs对图像内容的理解和推理能力,并评估其是否存在刻板印象偏见。评估指标包括准确率、召回率和F1值等,用于衡量LMMs在不同类别和子类别上的表现。此外,论文还分析了思维模型(thinking models)在推理链中诱导偏见的情况。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是最先进的LMMs在BBQ-V基准测试中也表现出显著的刻板印象偏见。具体而言,思维模型在推理链中会诱导更多的偏见。例如,某些模型在处理特定种族或性别的图像时,会产生带有偏见的推理结果。这些结果强调了当前LMMs在处理真实世界视觉信息时存在的局限性,并突出了BBQ-V基准测试框架的重要性。
🎯 应用场景
该研究成果可应用于开发更公平、更负责任的人工智能系统。通过使用BBQ-V基准测试框架,可以评估和改进LMMs的偏见,减少其在实际应用中可能造成的歧视和不公平现象。这对于构建更值得信赖和可靠的AI系统至关重要,尤其是在涉及敏感社会问题的领域,如招聘、教育和医疗保健。
📄 摘要(原文)
Stereotype biases in Large Multimodal Models (LMMs) perpetuate harmful societal prejudices, undermining the fairness and equity of AI applications. As LMMs grow increasingly influential, addressing and mitigating inherent biases related to stereotypes, harmful generations, and ambiguous assumptions in real-world scenarios has become essential. However, existing datasets evaluating stereotype biases in LMMs often lack diversity, rely on synthetic images, and often have single-actor images, leaving a gap in bias evaluation for real-world visual contexts. To address the gap in bias evaluation using real images, we introduce the BBQ-Vision (BBQ-V), the most comprehensive framework for assessing stereotype biases across nine diverse categories and 50 sub-categories with real and multi-actor images. BBQ-V benchmark contains 14,144 image-question pairs and rigorously evaluates LMMs through carefully curated, visually grounded scenarios, challenging them to reason accurately about visual stereotypes. It offers a robust evaluation framework featuring real-world visual samples, image variations, and open-ended question formats. BBQ-V enables a precise and nuanced assessment of a model's reasoning capabilities across varying levels of difficulty. Through rigorous testing of 19 state-of-the-art open-source (general-purpose and reasoning) and closed-source LMMs, we highlight that these top-performing models are often biased on several social stereotypes, and demonstrate that the thinking models induce more bias in the reasoning chains. This benchmark represents a significant step toward fostering fairness in AI systems and reducing harmful biases, laying the groundwork for more equitable and socially responsible LMMs. Our dataset and evaluation code are publicly available.