Learning Human Skill Generators at Key-Step Levels
作者: Yilu Wu, Chenhui Zhu, Shuai Wang, Hanlin Wang, Jing Wang, Zhaoxiang Zhang, Limin Wang
分类: cs.CV
发布日期: 2025-02-12
🔗 代码/项目: GITHUB
💡 一句话要点
提出关键步骤技能生成(KS-Gen)任务,用于生成人类技能视频的关键步骤,提升具身智能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频生成 人类技能生成 关键步骤 多模态学习 具身智能
📋 核心要点
- 现有视频生成模型难以处理人类技能,因为人类技能涉及多步骤、长时间动作和复杂场景转换,简单的自回归方法无法胜任。
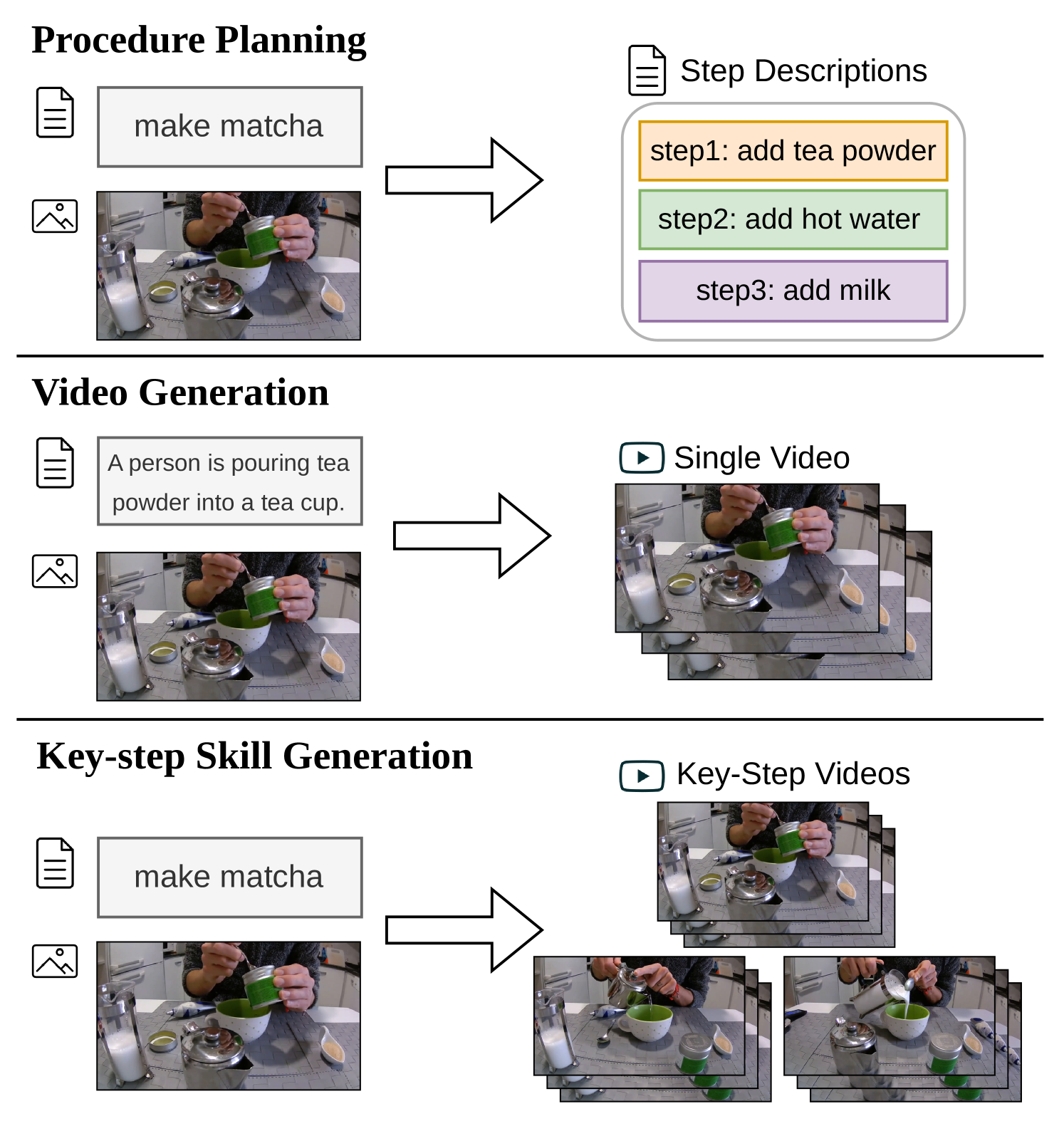
- 提出关键步骤技能生成(KS-Gen)任务,通过生成关键步骤视频片段来降低生成人类技能视频的复杂性,并构建了相应数据集。
- 设计包含多模态大语言模型、关键步骤图像生成器和视频生成模型的框架,以生成具有时间一致性的关键步骤视频片段。
📝 摘要(中文)
本文致力于学习关键步骤级别的人类技能生成器。技能生成是一项具有挑战性的工作,但其成功实现将极大地促进人类技能学习,并为具身智能提供更多经验。虽然当前的视频生成模型可以合成简单和原子的人类操作,但由于人类技能的复杂过程,它们难以处理人类技能。人类技能涉及多步骤、长时间的动作和复杂的场景转换,因此现有的用于合成长视频的朴素自回归方法无法生成人类技能。为了解决这个问题,我们提出了一项新的任务,即关键步骤技能生成(KS-Gen),旨在降低生成人类技能视频的复杂性。给定初始状态和技能描述,该任务是生成关键步骤的视频片段以完成技能,而不是完整的视频。为了支持这项任务,我们引入了一个精心策划的数据集,并定义了多个评估指标来评估性能。考虑到KS-Gen的复杂性,我们为这项任务提出了一个新的框架。首先,多模态大型语言模型(MLLM)使用检索参数生成关键步骤的描述。随后,我们使用关键步骤图像生成器(KIG)来解决技能视频中关键步骤之间的不连续性。最后,视频生成模型使用这些描述和关键步骤图像来生成具有高时间一致性的关键步骤的视频片段。我们提供了对结果的详细分析,希望为人类技能生成提供更多见解。所有模型和数据均可在https://github.com/MCG-NJU/KS-Gen 获得。
🔬 方法详解
问题定义:现有视频生成模型难以生成复杂的人类技能视频,因为这些技能通常包含多步骤、长时间的动作以及复杂的场景转换。传统的自回归方法在处理这种长序列依赖和场景变化时表现不佳,导致生成的视频质量不高,缺乏连贯性和真实感。因此,需要一种新的方法来简化人类技能视频的生成过程。
核心思路:论文的核心思路是将复杂的人类技能视频生成任务分解为关键步骤的生成。通过只关注技能执行过程中的关键帧或步骤,可以显著降低生成任务的复杂性,并更容易控制视频的内容和质量。这种方法类似于人类学习技能的过程,即先掌握关键步骤,再将它们组合起来。
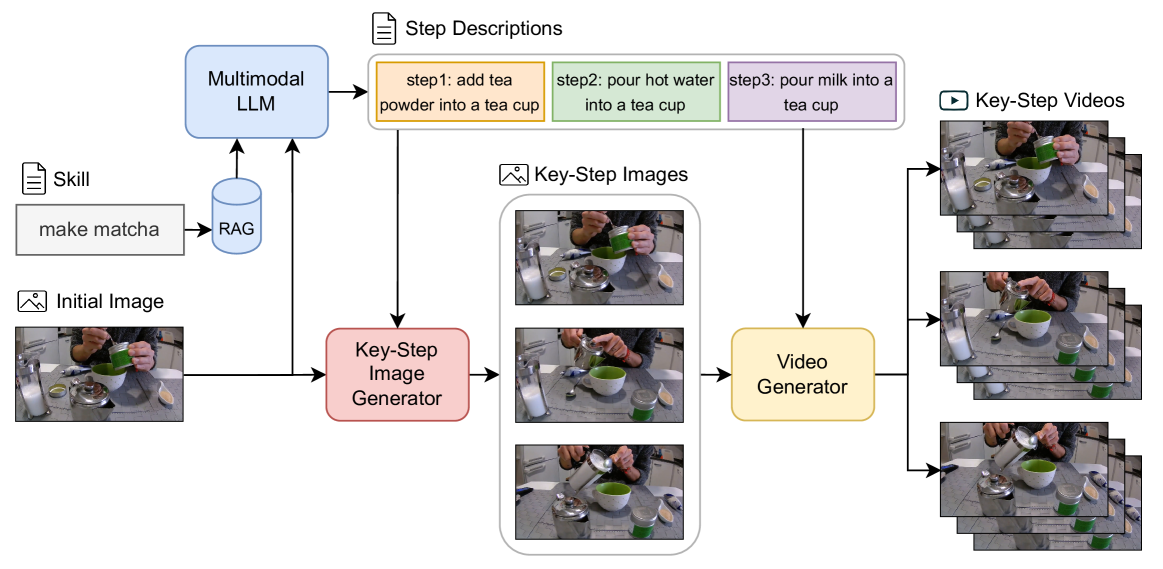
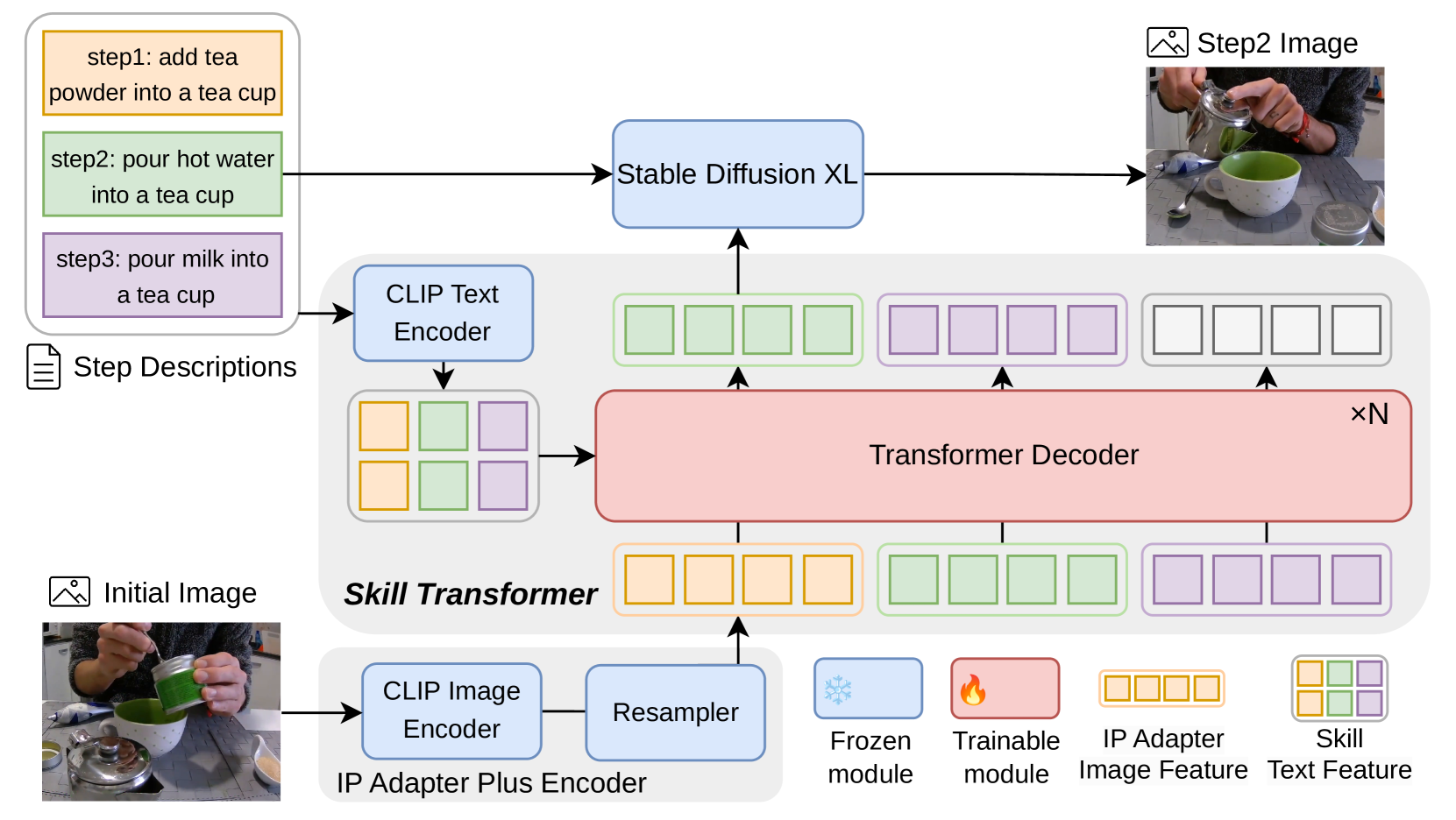
技术框架:该框架主要包含三个模块:1) 多模态大型语言模型(MLLM):用于根据初始状态和技能描述,生成关键步骤的文本描述,利用检索增强生成更准确的描述。2) 关键步骤图像生成器(KIG):用于生成关键步骤的图像,弥合关键步骤之间的视觉不连续性,提供更平滑的过渡。3) 视频生成模型:用于根据关键步骤的文本描述和图像,生成具有时间一致性的视频片段。整个流程是先用MLLM生成文本描述,然后用KIG生成图像,最后用视频生成模型将文本和图像转化为视频。
关键创新:该论文的关键创新在于提出了关键步骤技能生成(KS-Gen)任务,并设计了相应的框架。与传统的直接生成完整视频的方法相比,KS-Gen通过关注关键步骤,显著降低了生成任务的难度,并提高了生成视频的质量和可控性。此外,利用多模态大语言模型和关键步骤图像生成器,进一步增强了生成视频的真实感和连贯性。
关键设计:论文中使用了多模态大语言模型来生成关键步骤的描述,具体使用的模型和训练细节未知。关键步骤图像生成器(KIG)的具体网络结构和损失函数未知,但其目标是生成能够平滑过渡关键步骤的图像。视频生成模型的具体实现也未知,但其需要能够根据文本描述和图像生成具有时间一致性的视频片段。数据集的构建也至关重要,需要包含各种人类技能的视频,并标注出关键步骤。
🖼️ 关键图片
📊 实验亮点
论文提出了KS-Gen任务并构建了相应数据集,为人类技能生成研究提供了新的方向。虽然论文中没有给出具体的性能数据,但通过引入多模态大语言模型和关键步骤图像生成器,可以有效提高生成视频的质量和时间一致性。具体的实验结果和对比基线性能提升幅度未知。
🎯 应用场景
该研究成果可应用于机器人技能学习、虚拟现实内容生成、教育培训等领域。例如,机器人可以通过学习关键步骤技能生成,更快地掌握各种操作技能;虚拟现实应用可以利用该技术生成更逼真的人类技能演示;教育培训领域可以利用该技术制作更有效的技能教学视频。
📄 摘要(原文)
We are committed to learning human skill generators at key-step levels. The generation of skills is a challenging endeavor, but its successful implementation could greatly facilitate human skill learning and provide more experience for embodied intelligence. Although current video generation models can synthesis simple and atomic human operations, they struggle with human skills due to their complex procedure process. Human skills involve multi-step, long-duration actions and complex scene transitions, so the existing naive auto-regressive methods for synthesizing long videos cannot generate human skills. To address this, we propose a novel task, the Key-step Skill Generation (KS-Gen), aimed at reducing the complexity of generating human skill videos. Given the initial state and a skill description, the task is to generate video clips of key steps to complete the skill, rather than a full-length video. To support this task, we introduce a carefully curated dataset and define multiple evaluation metrics to assess performance. Considering the complexity of KS-Gen, we propose a new framework for this task. First, a multimodal large language model (MLLM) generates descriptions for key steps using retrieval argument. Subsequently, we use a Key-step Image Generator (KIG) to address the discontinuity between key steps in skill videos. Finally, a video generation model uses these descriptions and key-step images to generate video clips of the key steps with high temporal consistency. We offer a detailed analysis of the results, hoping to provide more insights on human skill generation. All models and data are available at https://github.com/MCG-NJU/KS-Gen.