Articulate That Object Part (ATOP): 3D Part Articulation via Text and Motion Personalization
作者: Aditya Vora, Sauradip Nag, Kai Wang, Hao Zhang
分类: cs.CV
发布日期: 2025-02-11 (更新: 2025-11-09)
备注: Technical Report, 16 pages
💡 一句话要点
ATOP:提出一种基于文本和运动个性化的3D部件可动性建模方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion)
关键词: 3D部件可动性 运动生成 扩散模型 文本驱动 少样本学习
📋 核心要点
- 现有方法在3D部件可动性建模中,由于缺乏带运动属性标注的数据集,泛化能力不足。
- ATOP利用文本提示驱动扩散模型生成运动样本,并结合3D对象进行运动个性化,实现少样本学习。
- 实验表明,ATOP能生成更逼真的运动样本,并在3D运动预测方面优于现有少样本方法。
📝 摘要(中文)
本文提出了一种名为ATOP(Articulate That Object Part)的新型少样本方法,该方法基于运动个性化,根据文本提示来表达静态3D对象的部件及其运动。 鉴于缺乏带有运动属性注释的可用数据集,现有方法难以在此任务中很好地泛化。 我们的工作利用文本输入来挖掘现代扩散模型的能力,从而为正确的对象类别和部件生成合理的运动样本。 反过来,输入的3D对象提供“图像提示”,以将生成的运动个性化到该输入对象。 我们的方法首先进行少样本微调,以将可动性感知注入到当前的扩散模型中,从而学习与目标对象部件相关的唯一运动标识符。 我们的微调应用于预训练的扩散模型,用于可控的多视角运动生成,该模型使用少量参考运动帧进行训练,这些运动帧展示了适当的部件运动。 然后,由此产生的运动模型可用于从多个视角实现输入3D对象的合理运动。 最后,我们通过可微渲染将个性化的运动转移到对象的3D空间,从而通过分数蒸馏采样损失来优化部件可动性参数。 在PartNet-Mobility和ACD数据集上的实验表明,与之前的少样本方法相比,我们的方法可以生成具有更高准确性的逼真运动样本,从而实现更具泛化性的3D运动预测。
🔬 方法详解
问题定义:论文旨在解决在缺乏大量标注数据的情况下,如何使3D模型按照文本描述,以自然的方式活动指定部件的问题。现有方法依赖大量标注数据,难以泛化到新的对象和运动类型。
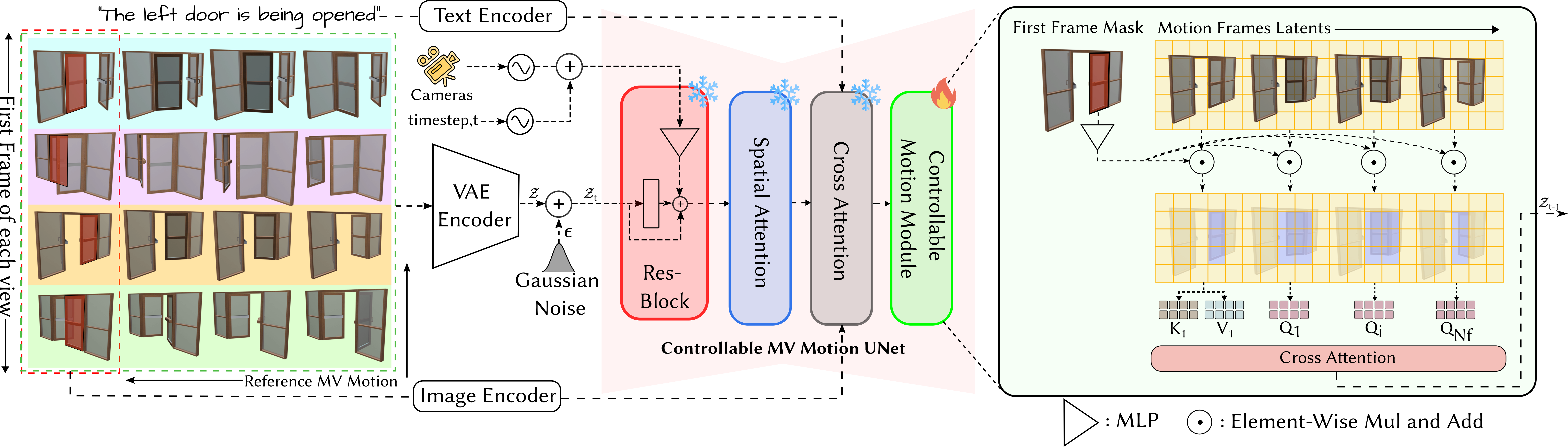
核心思路:核心思想是利用文本描述作为引导,通过扩散模型生成符合描述的运动序列,然后将这些运动序列“个性化”到特定的3D对象上。通过这种方式,可以利用扩散模型的生成能力和3D对象的几何信息,在少量样本下实现高质量的部件可动性建模。
技术框架:ATOP包含以下主要阶段:1) 少样本微调:使用少量参考运动帧微调预训练的扩散模型,使其具备部件可动性感知能力。2) 运动生成:利用微调后的扩散模型,根据文本提示和3D对象,生成多视角的运动序列。3) 运动转移与优化:通过可微渲染将生成的运动序列转移到3D对象上,并使用分数蒸馏采样损失优化部件可动性参数。
关键创新:主要创新在于将文本驱动的扩散模型与3D对象的几何信息相结合,实现运动的个性化。与现有方法相比,ATOP不需要大量标注数据,并且能够生成更逼真、更符合文本描述的运动序列。
关键设计:关键设计包括:1) 使用少量参考运动帧进行微调,以提高扩散模型的效率。2) 使用可微渲染将运动序列转移到3D对象上,实现端到端的优化。3) 使用分数蒸馏采样损失,确保生成的运动序列符合文本描述。
🖼️ 关键图片


📊 实验亮点
ATOP在PartNet-Mobility和ACD数据集上进行了实验,结果表明,与现有少样本方法相比,ATOP能够生成更逼真的运动样本,并实现更高的运动预测准确率。具体性能提升数据在论文中给出,证明了ATOP在少样本条件下的有效性。
🎯 应用场景
该研究成果可应用于虚拟现实、游戏开发、机器人控制等领域。例如,可以用于创建更逼真的虚拟角色动画,或者使机器人能够根据指令灵活地操作物体。此外,该方法还可以用于辅助设计,例如帮助设计师快速预览3D模型在不同运动状态下的效果。
📄 摘要(原文)
We present ATOP (Articulate That Object Part), a novel few-shot method based on motion personalization to articulate a static 3D object with respect to a part and its motion as prescribed in a text prompt. Given the scarcity of available datasets with motion attribute annotations, existing methods struggle to generalize well in this task. In our work, the text input allows us to tap into the power of modern-day diffusion models to generate plausible motion samples for the right object category and part. In turn, the input 3D object provides ``image prompting'' to personalize the generated motion to the very input object. Our method starts with a few-shot finetuning to inject articulation awareness to current diffusion models to learn a unique motion identifier associated with the target object part. Our finetuning is applied to a pre-trained diffusion model for controllable multi-view motion generation, trained with a small collection of reference motion frames demonstrating appropriate part motion. The resulting motion model can then be employed to realize plausible motion of the input 3D object from multiple views. At last, we transfer the personalized motion to the 3D space of the object via differentiable rendering to optimize part articulation parameters by a score distillation sampling loss. Experiments on PartNet-Mobility and ACD datasets demonstrate that our method can generate realistic motion samples with higher accuracy, leading to more generalizable 3D motion predictions compared to prior approaches in the few-shot setting.