Survey on AI-Generated Media Detection: From Non-MLLM to MLLM
作者: Yueying Zou, Peipei Li, Zekun Li, Huaibo Huang, Xing Cui, Xuannan Liu, Chenghanyu Zhang, Ran He
分类: cs.CV
发布日期: 2025-02-07 (更新: 2025-02-12)
💡 一句话要点
综述AI生成媒体检测技术:从非MLLM到MLLM的演进与挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI生成媒体检测 多模态学习 大型语言模型 深度学习 信息安全
📋 核心要点
- 现有AI生成媒体检测方法缺乏对领域特定方法向通用方法转变的系统性分析,限制了对技术演进的全面理解。
- 本文系统回顾了基于非MLLM和MLLM的AI生成媒体检测方法,从单模态和多模态角度分析其异同,并探讨混合方法。
- 分析了生成式AI的伦理和安全问题,并考察了不同司法管辖区对生成式AI的监管,为研究人员和从业者提供参考。
📝 摘要(中文)
人工智能生成媒体的激增对信息真实性和社会信任构成了重大挑战,因此迫切需要可靠的检测方法。AI生成媒体的检测方法发展迅速,与多模态大型语言模型(MLLM)的进步并行。目前的检测方法可分为两大类:基于非MLLM的方法和基于MLLM的方法。前者采用由深度学习技术驱动的高精度、领域特定检测器,而后者则利用基于MLLM的通用检测器,集成了真实性验证、可解释性和定位能力。尽管该领域取得了显著进展,但文献中仍然缺乏对从领域特定到通用检测方法转变的全面综述。本文通过对这两种方法进行系统回顾来弥补这一差距,从单模态和多模态的角度对其进行分析。我们对这些类别进行了详细的比较分析,考察了它们的方法论异同。通过分析,我们探讨了潜在的混合方法,并确定了伪造检测中的关键挑战,为未来的研究提供了方向。此外,随着MLLM在检测任务中变得越来越普遍,伦理和安全考虑已成为关键的全球问题。我们考察了各个司法管辖区围绕生成式人工智能(GenAI)的监管格局,为该领域的研究人员和从业人员提供了宝贵的见解。
🔬 方法详解
问题定义:当前AI生成媒体检测领域面临的挑战是如何有效地检测和识别日益复杂的AI生成内容,尤其是在多模态场景下。现有方法,特别是早期基于非MLLM的方法,虽然在特定领域表现良好,但泛化能力有限,难以适应快速发展的AI生成技术。同时,缺乏对MLLM在AI生成内容检测中作用的系统性研究。
核心思路:本文的核心思路是对现有的AI生成媒体检测方法进行分类和比较,重点关注从传统的非MLLM方法到新兴的MLLM方法的演进。通过分析不同方法的优缺点,探讨混合方法的可能性,并识别当前检测技术面临的关键挑战,为未来的研究方向提供指导。
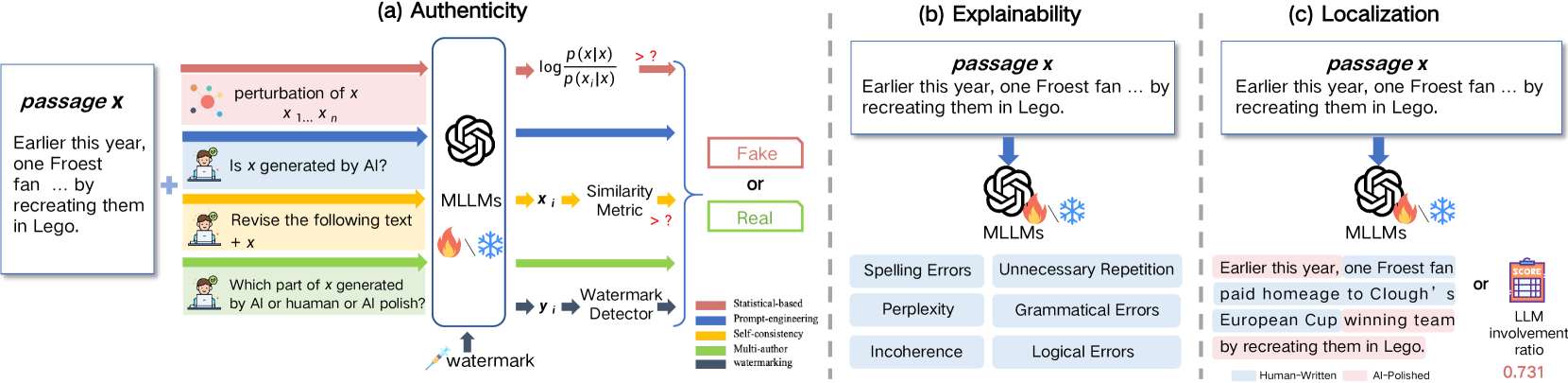
技术框架:本文的综述框架主要包括以下几个部分:首先,对AI生成媒体检测的背景和意义进行介绍;其次,将现有方法分为基于非MLLM和基于MLLM的两大类,并分别从单模态和多模态的角度进行详细分析;然后,对这两类方法进行比较,总结其异同和优缺点;最后,探讨了未来研究方向,并分析了生成式AI的伦理和安全问题。
关键创新:该综述的关键创新在于系统性地分析了AI生成媒体检测方法从非MLLM到MLLM的演进过程,并对两类方法进行了全面的比较。此外,本文还关注了生成式AI的伦理和安全问题,并对不同司法管辖区的监管政策进行了分析,这在以往的综述中较少涉及。
关键设计:本文的关键设计在于其分类框架和比较分析。通过将现有方法分为基于非MLLM和基于MLLM的两大类,并从单模态和多模态的角度进行分析,可以更清晰地了解不同方法的特点和适用场景。此外,本文还对不同方法的性能、复杂度和可解释性等方面进行了比较,为研究人员选择合适的方法提供了参考。
🖼️ 关键图片


📊 实验亮点
本文对非MLLM和MLLM两大类AI生成媒体检测方法进行了全面的对比分析,总结了各自的优缺点,并探讨了混合方法的潜力。此外,还对生成式AI的伦理和安全问题进行了深入探讨,为未来的研究方向提供了有价值的见解。
🎯 应用场景
该研究成果可应用于信息安全、社交媒体内容审核、新闻真实性验证等领域。通过提升AI生成媒体的检测能力,可以有效防止虚假信息的传播,维护社会信任,并为相关监管政策的制定提供参考。
📄 摘要(原文)
The proliferation of AI-generated media poses significant challenges to information authenticity and social trust, making reliable detection methods highly demanded. Methods for detecting AI-generated media have evolved rapidly, paralleling the advancement of Multimodal Large Language Models (MLLMs). Current detection approaches can be categorized into two main groups: Non-MLLM-based and MLLM-based methods. The former employs high-precision, domain-specific detectors powered by deep learning techniques, while the latter utilizes general-purpose detectors based on MLLMs that integrate authenticity verification, explainability, and localization capabilities. Despite significant progress in this field, there remains a gap in literature regarding a comprehensive survey that examines the transition from domain-specific to general-purpose detection methods. This paper addresses this gap by providing a systematic review of both approaches, analyzing them from single-modal and multi-modal perspectives. We present a detailed comparative analysis of these categories, examining their methodological similarities and differences. Through this analysis, we explore potential hybrid approaches and identify key challenges in forgery detection, providing direction for future research. Additionally, as MLLMs become increasingly prevalent in detection tasks, ethical and security considerations have emerged as critical global concerns. We examine the regulatory landscape surrounding Generative AI (GenAI) across various jurisdictions, offering valuable insights for researchers and practitioners in this field.