Goku: Flow Based Video Generative Foundation Models
作者: Shoufa Chen, Chongjian Ge, Yuqi Zhang, Yida Zhang, Fengda Zhu, Hao Yang, Hongxiang Hao, Hui Wu, Zhichao Lai, Yifei Hu, Ting-Che Lin, Shilong Zhang, Fu Li, Chuan Li, Xing Wang, Yanghua Peng, Peize Sun, Ping Luo, Yi Jiang, Zehuan Yuan, Bingyue Peng, Xiaobing Liu
分类: cs.CV
发布日期: 2025-02-07 (更新: 2025-02-10)
备注: Demo: https://saiyan-world.github.io/goku/
💡 一句话要点
Goku:基于流的视频生成基础模型,实现业界领先的图像和视频联合生成性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频生成 图像生成 生成模型 修正流 Transformer
📋 核心要点
- 现有图像和视频生成模型在高质量和一致性方面存在挑战,难以满足日益增长的应用需求。
- Goku采用修正流Transformer,通过优化数据流形上的路径,实现高质量的图像和视频联合生成。
- 实验结果表明,Goku在文本到图像和文本到视频生成任务上均取得了显著的性能提升,刷新了现有基准。
📝 摘要(中文)
本文介绍了Goku,一种最先进的图像和视频联合生成模型系列,它利用修正流Transformer来实现业界领先的性能。我们详细阐述了实现高质量视觉生成的基础要素,包括数据整理流程、模型架构设计、流公式以及用于高效和稳健的大规模训练的先进基础设施。Goku模型在定性和定量评估中均表现出卓越的性能,为主要任务设定了新的基准。具体而言,Goku在文本到图像生成方面,GenEval上达到0.76,DPG-Bench上达到83.65,在文本到视频任务的VBench上达到84.85。我们相信这项工作为研究界在开发图像和视频联合生成模型方面提供了宝贵的见解和实际进展。
🔬 方法详解
问题定义:现有的图像和视频生成模型,尤其是在联合生成方面,面临着生成质量不高、时间一致性差、以及训练成本高等问题。这些问题限制了它们在实际应用中的潜力。论文旨在解决这些痛点,提供一种能够生成高质量、高一致性图像和视频的通用模型。
核心思路:Goku的核心思路是利用修正流(Rectified Flow)Transformer。修正流通过学习数据流形上的最优传输路径,将噪声分布平滑地映射到目标数据分布,从而实现高质量的生成。Transformer架构则提供了强大的建模能力,能够捕捉图像和视频中的复杂依赖关系。
技术框架:Goku的整体框架包含以下几个主要模块:1) 数据预处理和增强模块,用于准备高质量的训练数据;2) 修正流Transformer模型,作为生成器的核心;3) 判别器(可选),用于对抗训练,进一步提升生成质量;4) 训练基础设施,支持大规模分布式训练。整个流程包括数据输入、模型训练、以及生成结果的评估。
关键创新:Goku的关键创新在于将修正流的概念与Transformer架构相结合,用于图像和视频的联合生成。与传统的GAN或VAE等生成模型相比,修正流能够提供更稳定的训练过程和更高质量的生成结果。此外,Goku还针对图像和视频数据的特点,对Transformer架构进行了优化。
关键设计:Goku的关键设计包括:1) 修正流的损失函数,用于优化数据流形上的传输路径;2) Transformer的注意力机制,用于捕捉图像和视频中的长程依赖关系;3) 大规模分布式训练策略,用于加速模型训练并提升模型性能;4) 数据增强策略,用于提升模型的泛化能力。具体参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片


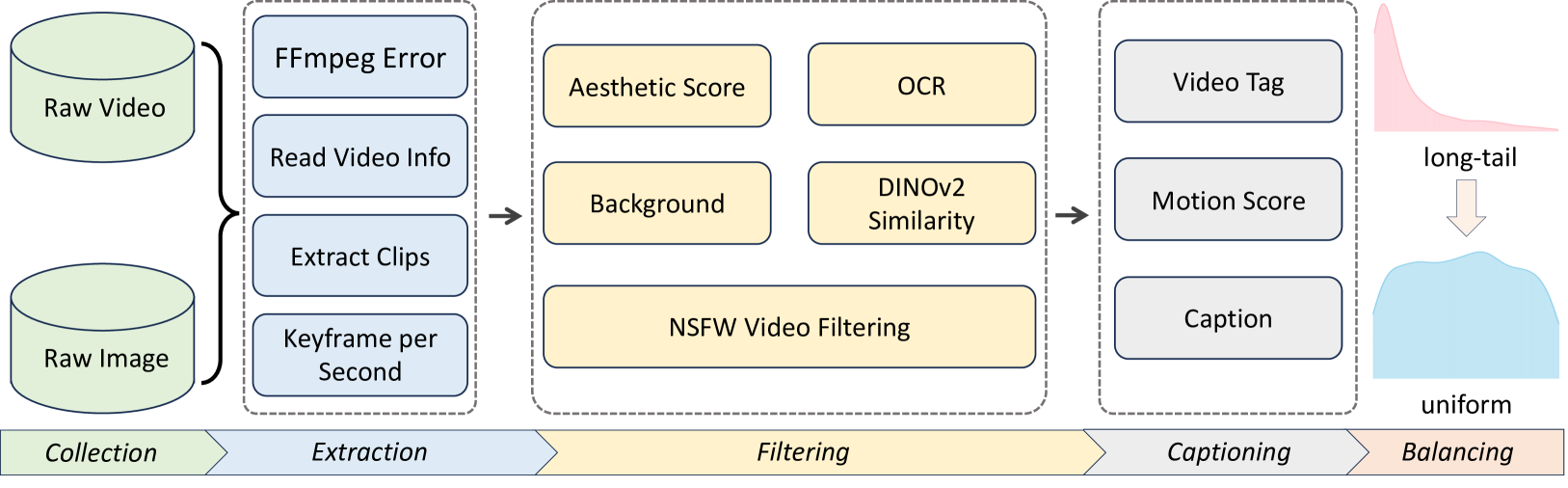
📊 实验亮点
Goku在文本到图像生成任务中,GenEval指标达到0.76,DPG-Bench指标达到83.65。在文本到视频生成任务中,VBench指标达到84.85。这些结果显著优于现有的其他模型,表明Goku在图像和视频联合生成方面具有强大的竞争力。
🎯 应用场景
Goku在多个领域具有广泛的应用前景,包括内容创作、游戏开发、广告设计、教育娱乐等。它可以用于生成逼真的图像和视频内容,例如电影特效、虚拟现实场景、以及个性化广告。此外,Goku还可以作为一种通用的视觉生成模型,用于解决各种图像和视频相关的任务。
📄 摘要(原文)
This paper introduces Goku, a state-of-the-art family of joint image-and-video generation models leveraging rectified flow Transformers to achieve industry-leading performance. We detail the foundational elements enabling high-quality visual generation, including the data curation pipeline, model architecture design, flow formulation, and advanced infrastructure for efficient and robust large-scale training. The Goku models demonstrate superior performance in both qualitative and quantitative evaluations, setting new benchmarks across major tasks. Specifically, Goku achieves 0.76 on GenEval and 83.65 on DPG-Bench for text-to-image generation, and 84.85 on VBench for text-to-video tasks. We believe that this work provides valuable insights and practical advancements for the research community in developing joint image-and-video generation models.