HumanDiT: Pose-Guided Diffusion Transformer for Long-form Human Motion Video Generation
作者: Qijun Gan, Yi Ren, Chen Zhang, Zhenhui Ye, Pan Xie, Xiang Yin, Zehuan Yuan, Bingyue Peng, Jianke Zhu
分类: cs.CV
发布日期: 2025-02-07 (更新: 2025-08-04)
备注: https://agnjason.github.io/HumanDiT-page/
💡 一句话要点
HumanDiT:姿态引导的扩散Transformer用于生成长时程人体运动视频
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 人体运动生成 扩散Transformer 姿态引导 长时程视频 视频延续
📋 核心要点
- 现有方法在长序列和复杂运动中,难以准确渲染人体运动视频中的手和面部等精细身体部位,并且依赖于固定分辨率。
- HumanDiT基于扩散Transformer,通过姿态引导,支持可变分辨率和序列长度,并引入前缀-潜在参考策略保持个性化特征。
- 实验表明,HumanDiT在生成长时程、姿态准确的视频方面表现出色,能够从静态图像或视频延续,并支持姿态迁移。
📝 摘要(中文)
本文提出HumanDiT,一个基于姿态引导的扩散Transformer(DiT)框架,旨在解决长序列和复杂运动中人体运动视频生成时,难以准确渲染手和面部等精细身体部位的问题。该框架基于包含14000小时高质量视频的大型数据集进行训练,能够生成具有精细身体渲染的高保真视频。HumanDiT基于DiT,支持多种视频分辨率和可变序列长度,从而促进长序列视频生成的学习。此外,引入了一种前缀-潜在参考策略,以保持跨越扩展序列的个性化特征。在推理过程中,HumanDiT利用Keypoint-DiT生成后续姿态序列,从而实现从静态图像或现有视频的视频延续。它还利用姿态适配器来实现给定序列的姿态迁移。大量实验表明,该方法在生成各种场景下的长时程、姿态准确的视频方面表现出色。
🔬 方法详解
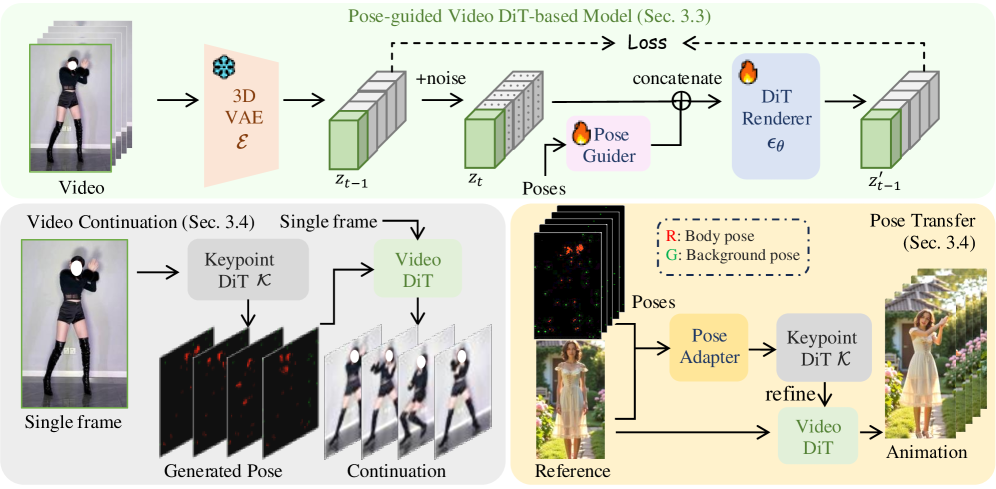
问题定义:现有的人体运动视频生成方法难以准确渲染精细的身体部位,如手和面部,尤其是在长序列和复杂的运动中。此外,这些方法通常依赖于固定的分辨率,难以保持视觉一致性。因此,需要一种能够生成高保真、长时程、姿态准确的人体运动视频的方法。
核心思路:HumanDiT的核心思路是利用扩散Transformer(DiT)的强大生成能力,并结合姿态引导,从而生成高质量的人体运动视频。通过在大规模数据集上训练,模型能够学习到人体运动的模式和细节,并通过姿态信息来控制生成过程。前缀-潜在参考策略用于保持视频序列中的个性化特征。
技术框架:HumanDiT的整体框架包括以下几个主要模块:1) 基于DiT的视频生成模型,负责生成视频帧;2) Keypoint-DiT,用于生成后续的姿态序列,实现视频延续;3) 姿态适配器,用于实现姿态迁移。在训练阶段,模型在大规模数据集上进行训练,学习人体运动的模式和细节。在推理阶段,模型首先根据输入的姿态序列生成视频帧,然后利用Keypoint-DiT生成后续的姿态序列,或者利用姿态适配器实现姿态迁移。
关键创新:HumanDiT的关键创新在于以下几个方面:1) 基于DiT的视频生成模型,能够生成高保真的视频;2) 前缀-潜在参考策略,能够保持视频序列中的个性化特征;3) Keypoint-DiT和姿态适配器,能够实现视频延续和姿态迁移。与现有方法相比,HumanDiT能够生成更长、更逼真、姿态更准确的人体运动视频。
关键设计:HumanDiT的关键设计包括:1) 采用扩散Transformer(DiT)作为视频生成模型,利用其强大的生成能力;2) 设计前缀-潜在参考策略,通过在DiT的输入中加入前缀潜在向量,从而保持视频序列中的个性化特征;3) 训练Keypoint-DiT,用于生成后续的姿态序列,实现视频延续;4) 设计姿态适配器,通过将姿态信息融入到DiT的输入中,从而实现姿态迁移。具体的损失函数和网络结构等细节在论文中进行了详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
HumanDiT在生成长时程、姿态准确的视频方面表现出色。实验结果表明,HumanDiT能够生成具有精细身体渲染的高保真视频,并且能够保持跨越扩展序列的个性化特征。此外,HumanDiT还能够实现从静态图像或现有视频的视频延续,以及姿态迁移。具体的性能数据和对比基线在论文中进行了详细描述(未知)。
🎯 应用场景
HumanDiT具有广泛的应用前景,包括虚拟现实、游戏开发、电影制作、动画制作等领域。它可以用于生成逼真的人体运动视频,从而提升用户体验。例如,在虚拟现实中,HumanDiT可以用于生成虚拟角色的运动,使其更加自然和逼真。在游戏开发中,HumanDiT可以用于生成游戏角色的动画,从而提升游戏的视觉效果。未来,该技术有望应用于更多领域,例如远程医疗、运动分析等。
📄 摘要(原文)
Human motion video generation has advanced significantly, while existing methods still struggle with accurately rendering detailed body parts like hands and faces, especially in long sequences and intricate motions. Current approaches also rely on fixed resolution and struggle to maintain visual consistency. To address these limitations, we propose HumanDiT, a pose-guided Diffusion Transformer (DiT)-based framework trained on a large and wild dataset containing 14,000 hours of high-quality video to produce high-fidelity videos with fine-grained body rendering. Specifically, (i) HumanDiT, built on DiT, supports numerous video resolutions and variable sequence lengths, facilitating learning for long-sequence video generation; (ii) we introduce a prefix-latent reference strategy to maintain personalized characteristics across extended sequences. Furthermore, during inference, HumanDiT leverages Keypoint-DiT to generate subsequent pose sequences, facilitating video continuation from static images or existing videos. It also utilizes a Pose Adapter to enable pose transfer with given sequences. Extensive experiments demonstrate its superior performance in generating long-form, pose-accurate videos across diverse scenarios.