Keep It Light! Simplifying Image Clustering Via Text-Free Adapters
作者: Yicen Li, Haitz Sáez de Ocáriz Borde, Anastasis Kratsios, Paul D. McNicholas
分类: cs.CV, cs.LG, cs.NE, stat.CO, stat.ML
发布日期: 2025-02-06 (更新: 2025-12-19)
💡 一句话要点
SCP:通过无文本适配器简化图像聚类,实现媲美SOTA的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像聚类 深度聚类 预训练模型 无监督学习 对比学习
📋 核心要点
- 现有聚类方法依赖文本信息,计算成本高,且文本-图像对在实际应用中难以获取。
- SCP方法仅训练小型聚类头,利用预训练视觉模型特征和正样本对,无需文本信息。
- 实验表明,SCP在多个数据集上达到与SOTA方法相当的性能,且计算成本更低。
📝 摘要(中文)
在预训练模型时代,简单的线性探测或轻量级读出层通常可以实现有效的分类。相比之下,许多有竞争力的聚类流程采用多模态设计,利用大型语言模型(LLM)或其他文本编码器以及文本-图像对,而这些在现实世界的下游应用中通常不可用。此外,此类框架通常训练复杂且需要大量计算资源,这使得广泛采用具有挑战性。本文表明,在深度聚类中,使用无文本且高度简化的训练流程可以实现与更复杂的最新方法相媲美的性能。特别地,我们的方法,即通过预训练模型进行简单聚类(SCP),仅训练一个小的聚类头,同时利用预训练的视觉模型特征表示和正数据对。在包括CIFAR-10、CIFAR-20、CIFAR-100、STL-10、ImageNet-10和ImageNet-Dogs在内的基准数据集上的实验表明,SCP实现了极具竞争力的性能。此外,我们提供了一个理论结果,解释了为什么至少在理想条件下,额外的基于文本的嵌入可能不是在视觉中实现强大聚类性能所必需的。
🔬 方法详解
问题定义:现有深度聚类方法通常依赖于多模态信息,特别是文本信息,例如使用大型语言模型或文本编码器来辅助图像聚类。这些方法计算成本高昂,训练复杂,并且需要文本-图像对,这在许多实际应用场景中是不可行的。因此,如何在不依赖文本信息的情况下,实现高效且高性能的图像聚类是一个关键问题。
核心思路:本文的核心思路是利用预训练的视觉模型提取图像特征,并在此基础上训练一个小型聚类头。通过正样本对的约束,使得聚类头能够学习到图像的内在结构,从而实现有效的聚类。该方法避免了使用文本信息,大大简化了训练流程,降低了计算成本。
技术框架:SCP方法的整体框架包括以下几个主要步骤:1. 使用预训练的视觉模型(例如,ResNet、ViT)提取图像的特征表示。2. 构建正样本对,例如使用数据增强技术生成同一图像的不同版本。3. 训练一个小型聚类头,该聚类头将图像特征映射到聚类标签。4. 使用对比损失函数,鼓励正样本对的特征表示映射到相同的聚类标签。
关键创新:该方法最重要的创新点在于其简洁性。它避免了使用复杂的文本编码器和多模态融合策略,而是专注于利用预训练视觉模型的强大特征提取能力和正样本对的约束。这种简化不仅降低了计算成本,也使得该方法更易于部署和应用。此外,论文还提供了一个理论结果,解释了在理想条件下,为什么额外的文本信息可能不是必需的。
关键设计:SCP的关键设计包括:1. 使用预训练的视觉模型,例如ResNet或ViT,作为特征提取器。2. 使用数据增强技术(例如,随机裁剪、颜色抖动)生成正样本对。3. 使用一个简单的线性层或多层感知机作为聚类头。4. 使用对比损失函数,例如InfoNCE损失,来训练聚类头。损失函数的具体形式可以根据实际情况进行调整。学习率、batch size等超参数的选择也会影响最终的聚类效果。
🖼️ 关键图片

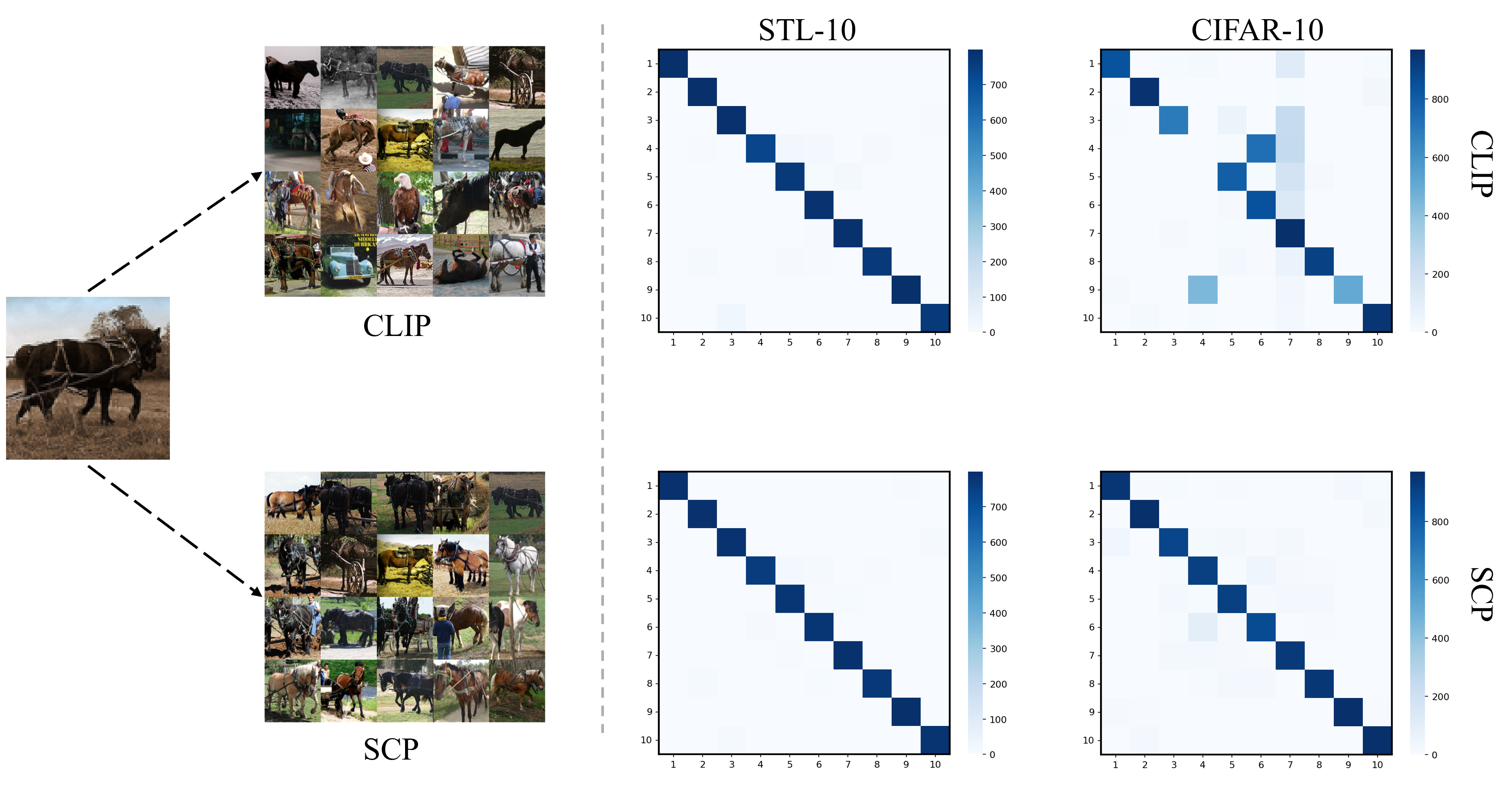
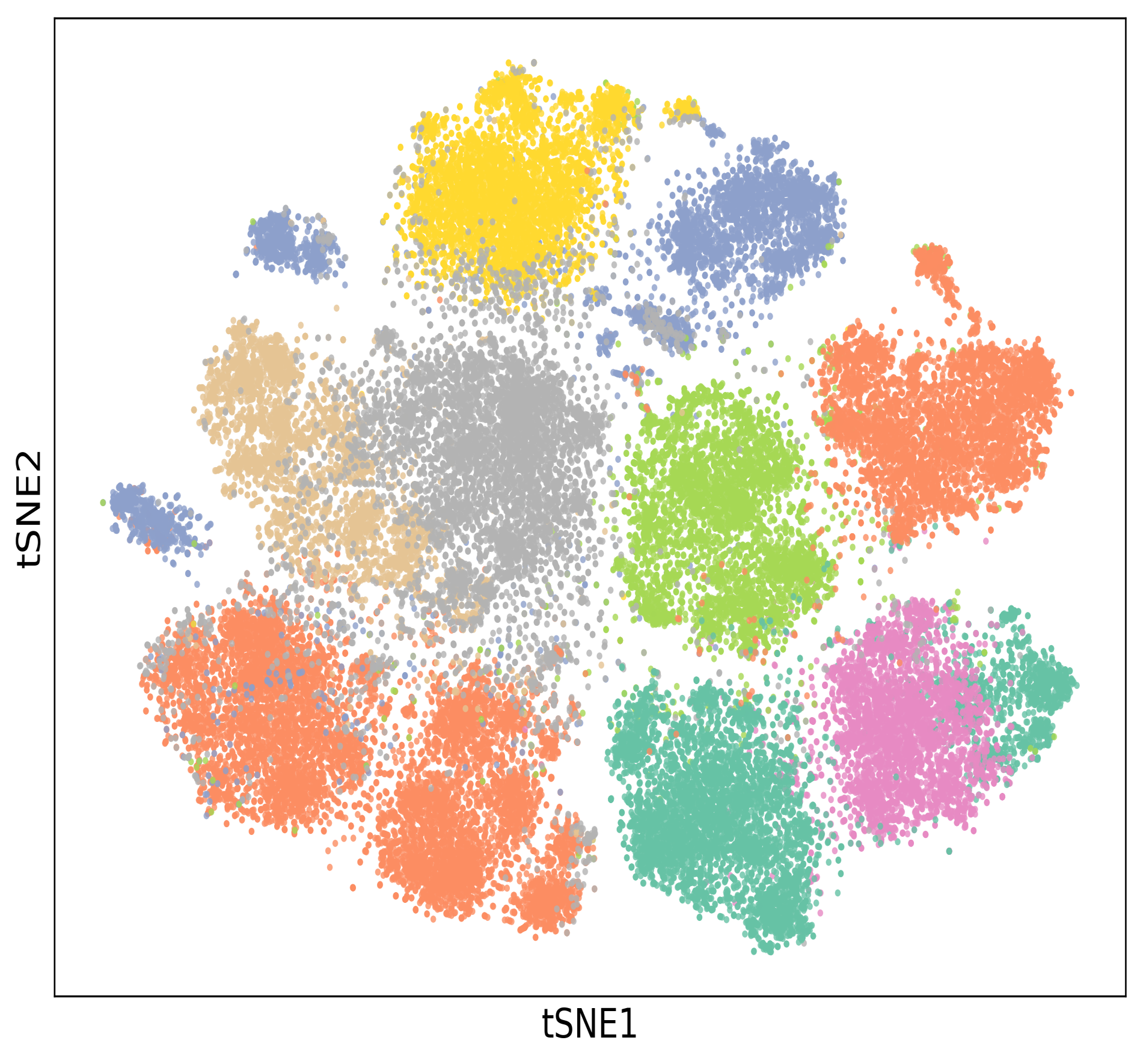
📊 实验亮点
SCP在CIFAR-10、CIFAR-20、CIFAR-100、STL-10、ImageNet-10和ImageNet-Dogs等多个基准数据集上进行了评估,实验结果表明,SCP在性能上与更复杂的SOTA方法具有竞争力,同时显著降低了计算成本和训练复杂度。例如,在某些数据集上,SCP甚至超过了需要文本信息的聚类方法。
🎯 应用场景
该研究成果可广泛应用于图像检索、图像分类、异常检测等领域。例如,在图像检索中,可以将图像聚类成不同的类别,从而加速检索过程。在异常检测中,可以将正常图像聚类在一起,从而更容易地识别异常图像。此外,该方法还可以应用于无监督学习和半监督学习等领域,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
In the era of pre-trained models, effective classification can often be achieved using simple linear probing or lightweight readout layers. In contrast, many competitive clustering pipelines have a multi-modal design, leveraging large language models (LLMs) or other text encoders, and text-image pairs, which are often unavailable in real-world downstream applications. Additionally, such frameworks are generally complicated to train and require substantial computational resources, making widespread adoption challenging. In this work, we show that in deep clustering, competitive performance with more complex state-of-the-art methods can be achieved using a text-free and highly simplified training pipeline. In particular, our approach, Simple Clustering via Pre-trained models (SCP), trains only a small cluster head while leveraging pre-trained vision model feature representations and positive data pairs. Experiments on benchmark datasets, including CIFAR-10, CIFAR-20, CIFAR-100, STL-10, ImageNet-10, and ImageNet-Dogs, demonstrate that SCP achieves highly competitive performance. Furthermore, we provide a theoretical result explaining why, at least under ideal conditions, additional text-based embeddings may not be necessary to achieve strong clustering performance in vision.