DICE: Distilling Classifier-Free Guidance into Text Embeddings
作者: Zhenyu Zhou, Defang Chen, Can Wang, Chun Chen, Siwei Lyu
分类: cs.CV
发布日期: 2025-02-06 (更新: 2025-11-24)
备注: AAAI 2026 (Oral)
🔗 代码/项目: GITHUB
💡 一句话要点
提出DICE以降低文本图像生成中的计算复杂度
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 文本到图像生成 无分类器引导 计算复杂度 文本嵌入 图像生成模型
📋 核心要点
- 现有的文本到图像生成模型在文本表示上存在不足,导致生成图像与文本提示的对齐效果不佳。
- DICE通过蒸馏无分类器引导,优化文本嵌入以复制CFG的引导方向,从而降低计算复杂度。
- 实验结果表明,DICE在多个数据集上表现出色,生成图像质量与对齐效果优于传统CFG方法。
📝 摘要(中文)
文本到图像的扩散模型能够生成高质量图像,但预训练文本表示的不足常导致生成图像与文本提示不够对齐。无分类器引导(CFG)是一种流行且有效的技术,用于改善生成过程中的文本图像对齐。然而,CFG引入了显著的计算开销。本文提出了通过锐化文本嵌入蒸馏CFG(DICE),在保持相似生成质量的同时,将CFG在采样过程中的计算复杂度降低了一半。DICE通过精炼文本嵌入来复制基于CFG的方向,从而避免了CFG的计算缺陷,实现高质量、良好对齐的图像生成,并提高了采样速度。通过对多种Stable Diffusion v1.5变体、SDXL和PixArt-$α$的广泛实验,验证了我们方法的有效性。
🔬 方法详解
问题定义:本文旨在解决文本到图像生成中由于预训练文本表示不足导致的图像与文本提示不对齐的问题。现有的无分类器引导(CFG)方法虽然有效,但计算开销较大,限制了其应用。
核心思路:DICE的核心思路是通过蒸馏CFG的引导信息,优化文本嵌入,使其在不使用CFG的情况下仍能保持高质量的图像生成。通过这种方式,DICE显著降低了计算复杂度,同时保持了生成质量。
技术框架:DICE的整体架构包括文本嵌入的锐化模块和图像生成模块。首先,文本嵌入经过锐化处理,以增强其语义信息和细节,然后将处理后的嵌入输入到图像生成模型中。
关键创新:DICE的主要创新在于通过精炼文本嵌入来复制CFG的引导方向,从而实现无分类器引导的高效图像生成。这一方法与传统的CFG方法相比,显著降低了计算复杂度。
关键设计:在DICE中,关键设计包括文本嵌入的锐化算法和损失函数的优化,以确保在降低计算复杂度的同时,保持生成图像的质量和对齐效果。
🖼️ 关键图片
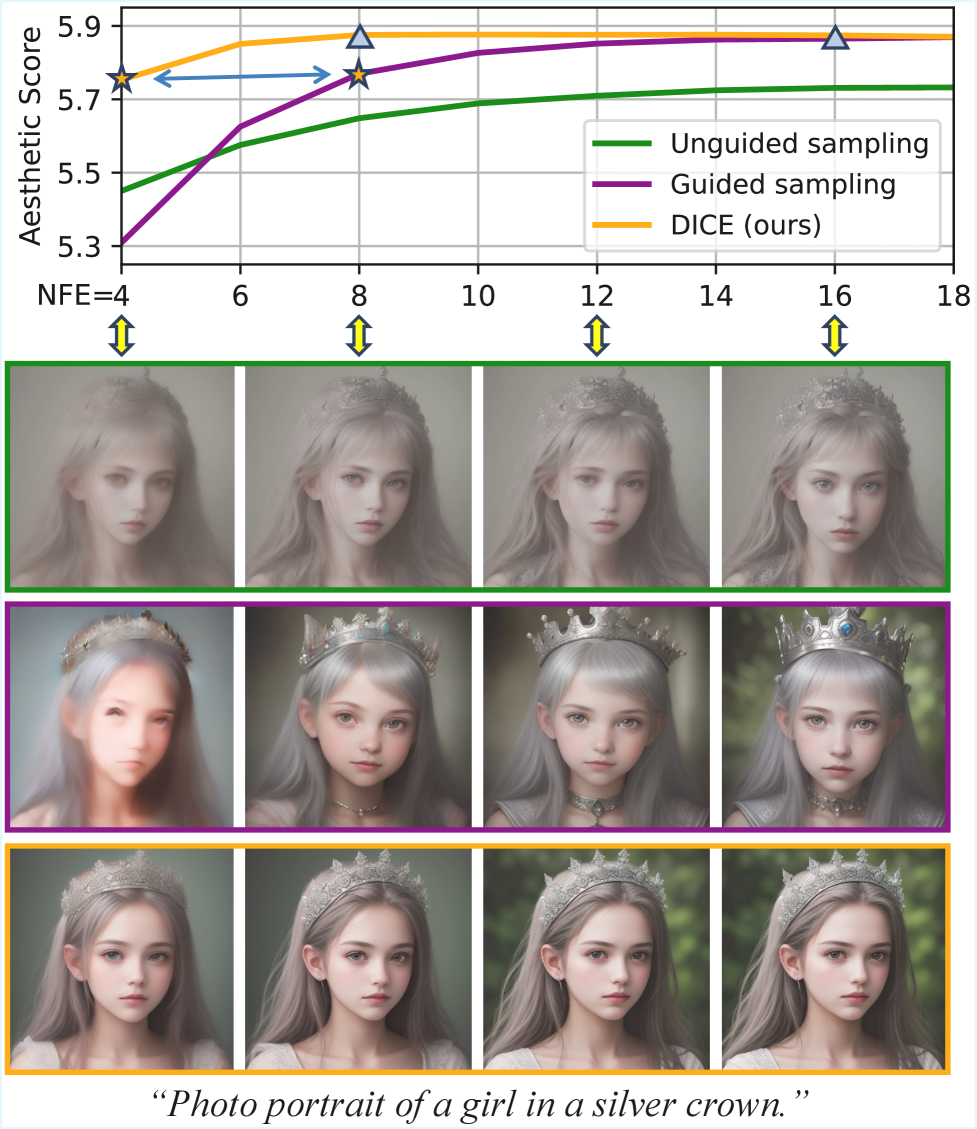
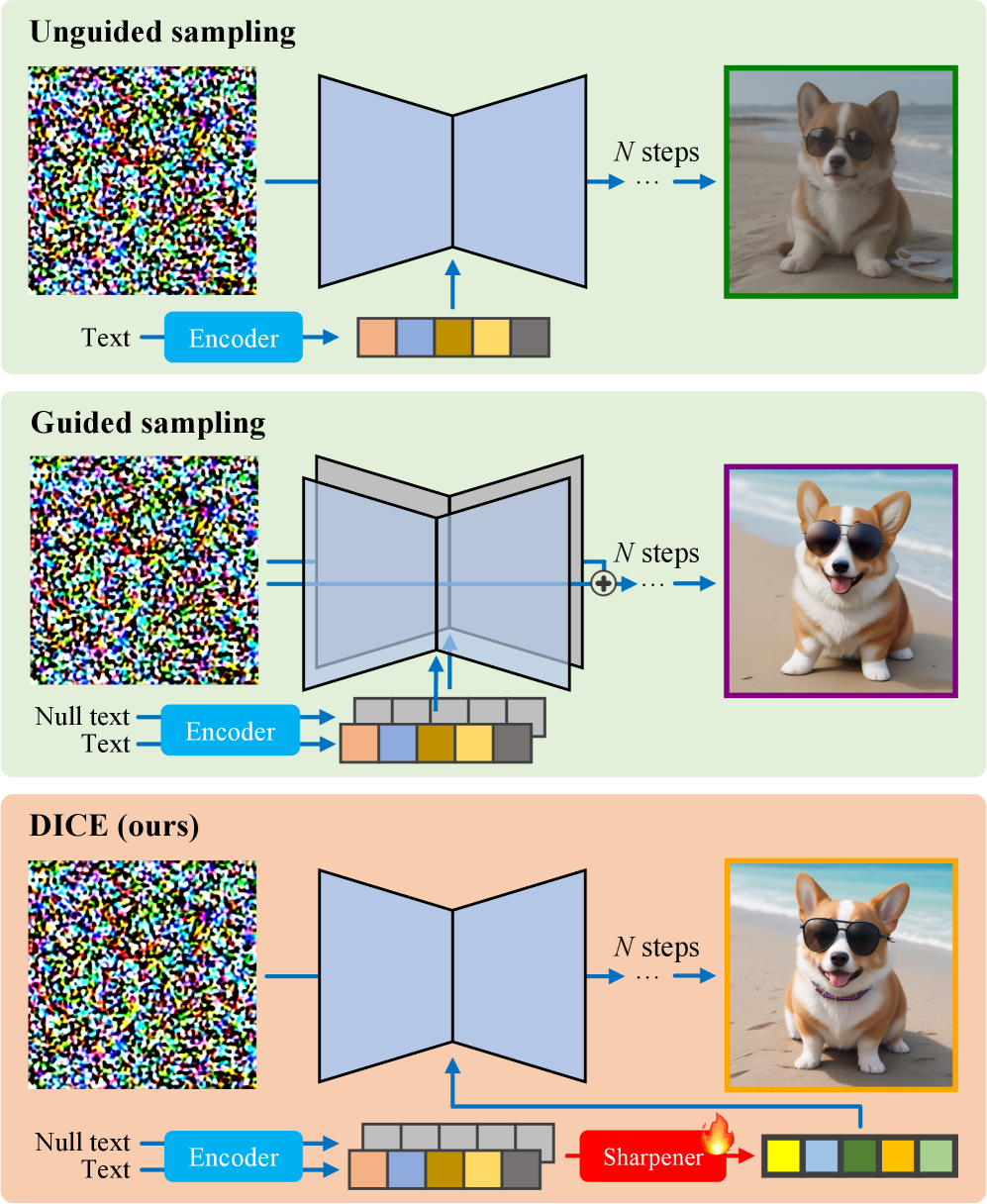

📊 实验亮点
实验结果显示,DICE在多个数据集上均表现优异,相较于传统CFG方法,生成图像的质量和对齐效果保持不变,同时计算复杂度降低了50%。具体而言,在Stable Diffusion v1.5变体上,DICE的生成速度显著提高,且图像质量评估指标均优于基线。
🎯 应用场景
该研究的潜在应用领域包括计算机视觉、艺术创作和虚拟现实等。通过降低文本到图像生成的计算复杂度,DICE可以在实时应用中实现高效的图像生成,提升用户体验。未来,DICE可能会在多模态生成任务中发挥更大作用,推动相关技术的发展。
📄 摘要(原文)
Text-to-image diffusion models are capable of generating high-quality images, but suboptimal pre-trained text representations often result in these images failing to align closely with the given text prompts. Classifier-free guidance (CFG) is a popular and effective technique for improving text-image alignment in the generative process. However, CFG introduces significant computational overhead. In this paper, we present DIstilling CFG by sharpening text Embeddings (DICE) that replaces CFG in the sampling process with half the computational complexity while maintaining similar generation quality. DICE distills a CFG-based text-to-image diffusion model into a CFG-free version by refining text embeddings to replicate CFG-based directions. In this way, we avoid the computational drawbacks of CFG, enabling high-quality, well-aligned image generation at a fast sampling speed. Furthermore, examining the enhancement pattern, we identify the underlying mechanism of DICE that sharpens specific components of text embeddings to preserve semantic information while enhancing fine-grained details. Extensive experiments on multiple Stable Diffusion v1.5 variants, SDXL, and PixArt-$α$ demonstrate the effectiveness of our method. Code is available at https://github.com/zju-pi/dice.