Dress-1-to-3: Single Image to Simulation-Ready 3D Outfit with Diffusion Prior and Differentiable Physics
作者: Xuan Li, Chang Yu, Wenxin Du, Ying Jiang, Tianyi Xie, Yunuo Chen, Yin Yang, Chenfanfu Jiang
分类: cs.CV
发布日期: 2025-02-05 (更新: 2025-05-21)
备注: Project page: https://dress-1-to-3.github.io/
💡 一句话要点
Dress-1-to-3:提出一种从单张图像重建可用于仿真的可分离3D服装方法
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 3D服装重建 可微物理模拟 图像到3D 虚拟试穿 扩散模型
📋 核心要点
- 现有图像到3D重建方法生成的模型通常融合成单块,限制了其在虚拟试穿等下游任务中的应用。
- Dress-1-to-3结合预训练模型和可微物理模拟,从单张图像重建可分离、可用于仿真的3D服装。
- 实验表明,该方法能有效提升3D服装与输入图像的几何对齐,并可生成逼真的动态服装演示。
📝 摘要(中文)
本文提出Dress-1-to-3,一种新颖的流程,能够从单张真实图像中重建具有物理合理性、可用于仿真的、可分离的服装,并生成缝纫图案和人体模型。该方法首先利用预训练的图像到缝纫图案生成模型创建粗略的缝纫图案,然后使用预训练的多视角扩散模型生成多视角图像。接着,基于生成的多视角图像,使用可微的服装模拟器进一步优化缝纫图案。实验结果表明,该优化方法显著提高了重建的3D服装和人体与输入图像的几何对齐。此外,通过集成纹理生成模块和人体运动生成模块,该方法能够生成定制的、物理上合理且逼真的动态服装演示。
🔬 方法详解
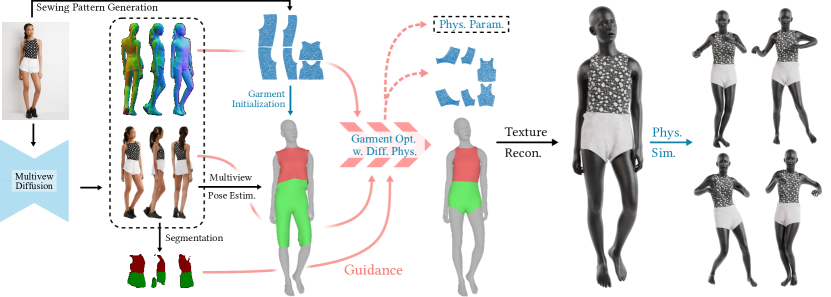
问题定义:现有图像到3D服装重建方法主要存在两个痛点:一是重建的服装通常是与人体融合在一起的,无法单独分离出来进行编辑和仿真;二是重建的服装缺乏物理合理性,无法直接用于动态仿真,例如虚拟试穿等应用。
核心思路:Dress-1-to-3的核心思路是结合预训练的生成模型和可微的物理模拟器,首先利用生成模型从单张图像中生成粗略的服装结构和纹理,然后利用可微的物理模拟器对生成的服装进行优化,使其在物理上更加合理,并且与输入图像更加一致。这样既可以利用生成模型的先验知识,又可以通过物理模拟来保证服装的真实感。
技术框架:Dress-1-to-3的整体流程包括以下几个主要阶段:1) 粗略缝纫图案生成:使用预训练的图像到缝纫图案生成模型,从单张图像中生成粗略的缝纫图案。2) 多视角图像生成:使用预训练的多视角扩散模型,基于单张图像生成多视角图像,为后续的3D重建提供更丰富的视角信息。3) 可微物理模拟优化:使用可微的服装模拟器,基于生成的多视角图像,对缝纫图案进行优化,使其在物理上更加合理,并且与输入图像更加一致。4) 纹理生成与人体运动:集成纹理生成模块和人体运动生成模块,生成定制的、物理上合理且逼真的动态服装演示。
关键创新:Dress-1-to-3的关键创新在于将预训练的生成模型和可微的物理模拟器结合起来,实现从单张图像到可用于仿真的3D服装的重建。与现有方法相比,Dress-1-to-3能够生成可分离的服装,并且具有更好的物理合理性。此外,使用可微的物理模拟器进行优化,可以有效地提高重建的3D服装与输入图像的几何对齐。
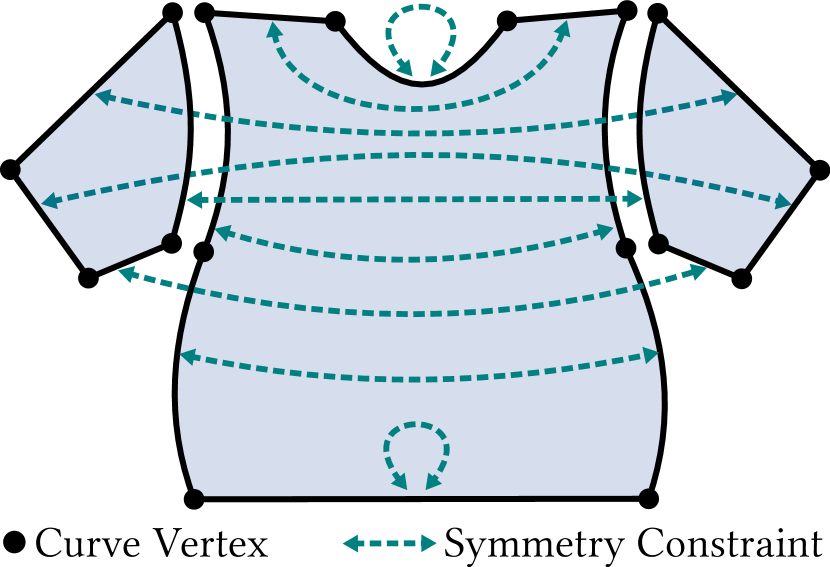
关键设计:在可微物理模拟优化阶段,使用了基于cloth-MPM的模拟器,并设计了多种损失函数来约束服装的形状和运动。这些损失函数包括:1) 图像对齐损失:用于约束重建的服装与输入图像的几何对齐。2) 物理合理性损失:用于约束服装的物理行为,例如避免自相交等。3) 平滑性损失:用于约束服装的形状平滑性。此外,在多视角图像生成阶段,使用了预训练的Stable Diffusion模型,并针对服装图像进行了微调,以提高生成图像的质量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Dress-1-to-3能够显著提高重建的3D服装和人体与输入图像的几何对齐。通过与现有方法的对比,Dress-1-to-3在服装的物理合理性和可分离性方面表现出明显的优势。此外,该方法能够生成逼真的动态服装演示,为虚拟试穿等应用提供了有力的支持。项目主页提供了详细的实验结果和演示视频。
🎯 应用场景
Dress-1-to-3在虚拟试穿、游戏角色定制、电影服装设计等领域具有广泛的应用前景。该技术可以帮助用户快速生成个性化的3D服装,并进行动态展示和仿真,从而提升用户体验和创作效率。未来,该技术有望应用于电商平台,为用户提供更真实的在线试穿体验,并促进服装行业的数字化转型。
📄 摘要(原文)
Recent advances in large models have significantly advanced image-to-3D reconstruction. However, the generated models are often fused into a single piece, limiting their applicability in downstream tasks. This paper focuses on 3D garment generation, a key area for applications like virtual try-on with dynamic garment animations, which require garments to be separable and simulation-ready. We introduce Dress-1-to-3, a novel pipeline that reconstructs physics-plausible, simulation-ready separated garments with sewing patterns and humans from an in-the-wild image. Starting with the image, our approach combines a pre-trained image-to-sewing pattern generation model for creating coarse sewing patterns with a pre-trained multi-view diffusion model to produce multi-view images. The sewing pattern is further refined using a differentiable garment simulator based on the generated multi-view images. Versatile experiments demonstrate that our optimization approach substantially enhances the geometric alignment of the reconstructed 3D garments and humans with the input image. Furthermore, by integrating a texture generation module and a human motion generation module, we produce customized physics-plausible and realistic dynamic garment demonstrations. Project page: https://dress-1-to-3.github.io/