RadVLM: A Multitask Conversational Vision-Language Model for Radiology
作者: Nicolas Deperrois, Hidetoshi Matsuo, Samuel Ruipérez-Campillo, Moritz Vandenhirtz, Sonia Laguna, Alain Ryser, Koji Fujimoto, Mizuho Nishio, Thomas M. Sutter, Julia E. Vogt, Jonas Kluckert, Thomas Frauenfelder, Christian Blüthgen, Farhad Nooralahzadeh, Michael Krauthammer
分类: cs.CV, cs.AI
发布日期: 2025-02-05 (更新: 2025-10-10)
备注: 21 pages, 15 figures
💡 一句话要点
RadVLM:用于放射学的多任务对话式视觉-语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 放射学 胸部X光片 多任务学习 对话系统 医学影像分析 视觉定位
📋 核心要点
- 现有VLM在放射学报告生成等任务中表现出潜力,但缺乏交互式诊断能力,限制了临床应用。
- RadVLM通过构建大规模指令数据集并进行多任务联合训练,提升了模型在对话和视觉定位方面的能力。
- 实验结果表明,RadVLM在对话能力和视觉定位方面达到了SOTA,并在其他放射学任务中保持竞争力。
📝 摘要(中文)
胸部X光片(CXR)的广泛使用以及放射科医生的短缺,推动了对自动化CXR分析和AI辅助报告的日益增长的兴趣。现有的视觉-语言模型(VLM)在报告生成或异常检测等特定任务中显示出前景,但它们通常缺乏对交互式诊断能力的支持。本文提出了RadVLM,一个紧凑的、多任务对话式基础模型,专为CXR解读而设计。为此,我们整理了一个大规模的指令数据集,包含超过100万个图像-指令对,其中包含单轮任务(如报告生成、异常分类和视觉定位)以及多轮、多任务对话交互。在对RadVLM在此指令数据集上进行微调后,我们评估了它在不同任务中的表现,并重新实现了基线VLM。结果表明,RadVLM在对话能力和视觉定位方面取得了最先进的性能,同时在其他放射学任务中保持了竞争力。消融研究进一步突出了跨多个任务进行联合训练的好处,尤其是在注释数据有限的情况下。总而言之,这些发现突出了RadVLM作为临床相关的AI助手的潜力,提供结构化的CXR解读和对话能力,以支持更有效和可访问的诊断工作流程。
🔬 方法详解
问题定义:论文旨在解决胸部X光片(CXR)解读中,现有视觉-语言模型(VLM)缺乏交互式诊断能力的问题。现有方法通常专注于单一任务,如报告生成或异常检测,无法支持多轮对话和多任务协作,限制了其在临床环境中的应用潜力。
核心思路:论文的核心思路是构建一个多任务对话式VLM,使其能够同时处理多种放射学任务,并支持与用户的交互式对话。通过大规模指令数据集的训练,模型能够学习不同任务之间的关联,并根据用户的提问提供更全面和深入的诊断信息。
技术框架:RadVLM的整体框架基于一个预训练的VLM模型,并在此基础上进行微调。主要包含以下几个模块:1) 图像编码器:用于提取CXR图像的视觉特征;2) 文本编码器:用于编码用户输入的文本指令;3) 多模态融合模块:将视觉特征和文本特征进行融合,得到联合表示;4) 任务解码器:根据联合表示,生成相应的输出,如报告、异常分类结果或视觉定位结果。
关键创新:RadVLM的关键创新在于其多任务对话式训练方法。通过构建包含单轮和多轮任务的大规模指令数据集,模型能够学习不同任务之间的关联,并具备对话能力。此外,论文还通过消融研究验证了联合训练的有效性,特别是在数据有限的情况下。
关键设计:RadVLM的关键设计包括:1) 大规模指令数据集的构建,涵盖多种放射学任务和对话场景;2) 多任务联合训练策略,通过共享参数和损失函数,提高模型的泛化能力;3) 针对对话任务的优化,如引入对话历史信息和注意力机制,提高对话的连贯性和准确性。
🖼️ 关键图片


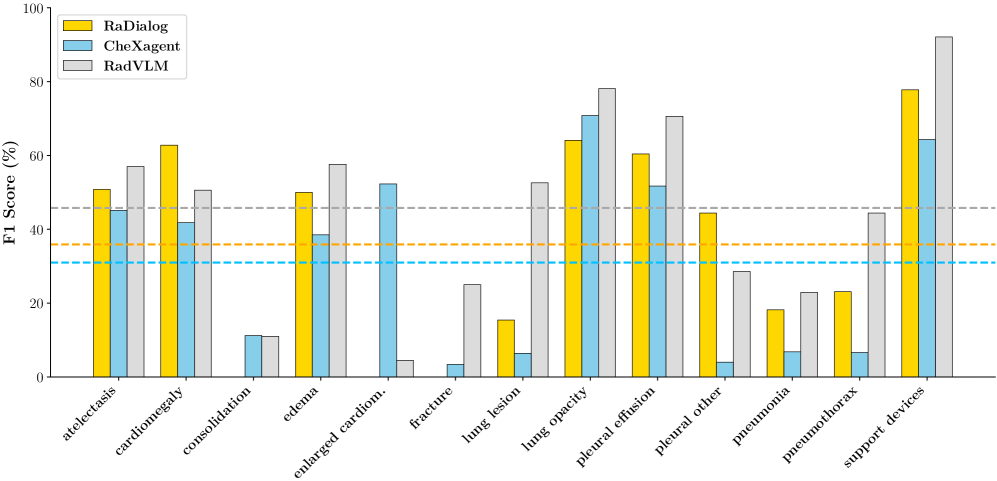
📊 实验亮点
RadVLM在对话能力和视觉定位方面取得了SOTA性能,并在其他放射学任务中保持竞争力。消融研究表明,联合训练显著提升了模型在数据有限情况下的性能。例如,在视觉定位任务中,RadVLM的性能优于其他基线模型,证明了其在多任务学习和对话交互方面的优势。
🎯 应用场景
RadVLM具有广泛的应用前景,可作为放射科医生的AI助手,辅助进行CXR解读和诊断。它可以应用于临床诊断、远程医疗、医学教育等领域,提高诊断效率和准确性,并为患者提供更便捷的医疗服务。未来,RadVLM有望与其他医疗影像模态(如CT、MRI)相结合,构建更全面的医学影像分析系统。
📄 摘要(原文)
The widespread use of chest X-rays (CXRs), coupled with a shortage of radiologists, has driven growing interest in automated CXR analysis and AI-assisted reporting. While existing vision-language models (VLMs) show promise in specific tasks such as report generation or abnormality detection, they often lack support for interactive diagnostic capabilities. In this work we present RadVLM, a compact, multitask conversational foundation model designed for CXR interpretation. To this end, we curate a large-scale instruction dataset comprising over 1 million image-instruction pairs containing both single-turn tasks -- such as report generation, abnormality classification, and visual grounding -- and multi-turn, multi-task conversational interactions. After fine-tuning RadVLM on this instruction dataset, we evaluate it across different tasks along with re-implemented baseline VLMs. Our results show that RadVLM achieves state-of-the-art performance in conversational capabilities and visual grounding while remaining competitive in other radiology tasks. Ablation studies further highlight the benefit of joint training across multiple tasks, particularly for scenarios with limited annotated data. Together, these findings highlight the potential of RadVLM as a clinically relevant AI assistant, providing structured CXR interpretation and conversational capabilities to support more effective and accessible diagnostic workflows.