MaxInfo: A Training-Free Key-Frame Selection Method Using Maximum Volume for Enhanced Video Understanding
作者: Pengyi Li, Irina Abdullaeva, Alexander Gambashidze, Andrey Kuznetsov, Ivan Oseledets
分类: cs.CV, cs.LG
发布日期: 2025-02-05 (更新: 2025-12-29)
🔗 代码/项目: GITHUB
💡 一句话要点
提出MaxInfo,一种免训练的关键帧选择方法,提升视频理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 关键帧选择 最大体积原则 免训练方法 视频大语言模型
📋 核心要点
- 现有VLLM依赖的均匀帧采样方法,在处理长视频时,由于帧冗余和内容变化,难以有效捕捉关键信息。
- MaxInfo基于最大体积原则,通过选择能够最大化嵌入空间几何体积的帧,来减少冗余并保持视频内容的多样性。
- 实验表明,MaxInfo在多个长视频理解基准测试中,显著提升了VLLM的性能,且无需额外训练,易于部署。
📝 摘要(中文)
现代视频大语言模型(VLLM)通常依赖均匀帧采样进行视频理解,但由于帧冗余和视频内容变化,这种方法经常无法捕捉关键信息。我们提出了MaxInfo,这是第一个基于最大体积原则的免训练方法,它提供快速版、慢速版和基于分块的版本,用于选择和保留视频中最具代表性的帧。通过最大化所选嵌入形成的几何体积,MaxInfo确保所选帧覆盖嵌入空间中最具信息的区域,有效减少冗余,同时保持多样性。该方法提高了输入表示的质量,并提升了长视频理解的性能。例如,MaxInfo在LLaVA-Video-7B上,LongVideoBench提升了3.28%,EgoSchema提升了6.4%。此外,MaxInfo在LLaVA-Video-72B上LongVideoBench性能提升了3.47%,在MiniCPM4.5上提升了3.44%。该方法易于实现,无需额外训练即可与现有VLLM配合使用,且延迟非常低,使其成为传统均匀采样方法的实用且有效的替代方案。
🔬 方法详解
问题定义:现有视频大语言模型在处理长视频时,通常采用均匀采样策略提取视频帧。这种方法忽略了视频帧之间的冗余性,并且无法保证关键信息的有效提取,导致模型性能受限。因此,如何高效地从长视频中选择最具代表性的关键帧,成为提升视频理解能力的关键问题。
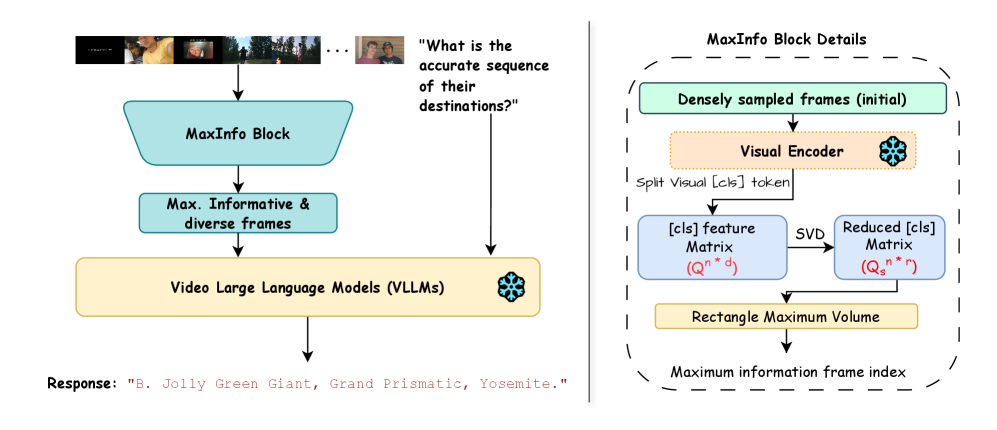
核心思路:MaxInfo的核心思路是基于最大体积原则,选择能够最大化嵌入空间几何体积的帧。具体来说,将视频帧通过预训练的视觉编码器映射到高维嵌入空间,然后选择一组帧,使得这些帧对应的嵌入向量所构成的多面体体积最大。这种方法旨在选择最具代表性和多样性的帧,从而有效减少冗余并保留关键信息。
技术框架:MaxInfo的整体框架包括以下几个主要步骤:1) 视频帧嵌入:使用预训练的视觉编码器(如CLIP)提取视频帧的嵌入向量。2) 关键帧选择:基于最大体积原则,从所有帧的嵌入向量中选择一组关键帧。MaxInfo提供了快速版、慢速版和基于分块的版本,以适应不同的计算资源和性能需求。3) 视频理解:将选择的关键帧输入到视频大语言模型中进行视频理解任务。
关键创新:MaxInfo最关键的创新在于其免训练的关键帧选择方法。与需要额外训练的关键帧选择方法不同,MaxInfo直接利用预训练的视觉编码器提取的嵌入向量,并通过最大体积原则进行选择。这种方法无需额外的训练数据和计算资源,易于部署和应用。此外,MaxInfo还提供了多种版本,以适应不同的计算资源和性能需求。
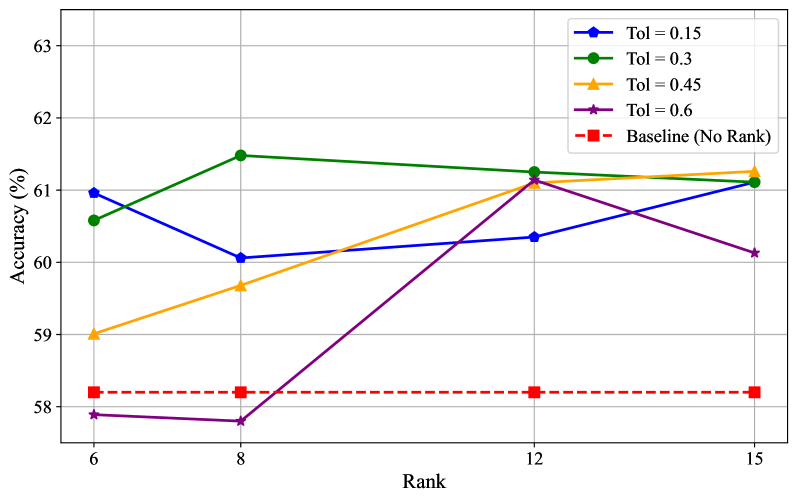
关键设计:MaxInfo的关键设计在于最大体积的计算方法。论文中具体采用了哪种最大体积计算方法(例如,基于行列式的计算方法)未知。此外,不同版本的MaxInfo在关键帧选择策略上可能存在差异,例如,快速版可能采用近似的体积计算方法,而慢速版则采用更精确的计算方法。基于分块的版本则将视频分割成多个块,并在每个块中独立选择关键帧。
🖼️ 关键图片

📊 实验亮点
MaxInfo在多个长视频理解基准测试中取得了显著的性能提升。例如,在LLaVA-Video-7B上,LongVideoBench提升了3.28%,EgoSchema提升了6.4%。此外,MaxInfo在LLaVA-Video-72B上LongVideoBench性能提升了3.47%,在MiniCPM4.5上提升了3.44%。这些结果表明,MaxInfo是一种有效且实用的关键帧选择方法,可以显著提升视频大语言模型的性能。
🎯 应用场景
MaxInfo可广泛应用于各种需要长视频理解的场景,例如视频摘要、视频检索、智能监控、自动驾驶等。通过提升视频大语言模型的性能,MaxInfo可以帮助人们更有效地理解和利用视频信息,提高工作效率和生活质量。未来,MaxInfo还可以与其他视频处理技术相结合,进一步拓展其应用领域。
📄 摘要(原文)
Modern Video Large Language Models (VLLMs) often rely on uniform frame sampling for video understanding, but this approach frequently fails to capture critical information due to frame redundancy and variations in video content. We propose MaxInfo, the first training-free method based on the maximum volume principle, which is available in Fast and Slow versions and a Chunk-based version that selects and retains the most representative frames from a video. By maximizing the geometric volume formed by selected embeddings, MaxInfo ensures that the chosen frames cover the most informative regions of the embedding space, effectively reducing redundancy while preserving diversity. This method enhances the quality of input representations and improves long video comprehension performance across benchmarks. For instance, MaxInfo achieves a 3.28% improvement on LongVideoBench and a 6.4% improvement on EgoSchema for LLaVA-Video-7B. Moreover, MaxInfo boosts LongVideoBench performance by 3.47% on LLaVA-Video-72B and 3.44% on MiniCPM4.5. The approach is simple to implement and works with existing VLLMs without the need for additional training and very lower latency, making it a practical and effective alternative to traditional uniform sampling methods. Our code are available at https://github.com/FusionBrainLab/MaxInfo.git