3D Foundation Model for Generalizable Disease Detection in Head Computed Tomography
作者: Weicheng Zhu, Haoxu Huang, Huanze Tang, Rushabh Musthyala, Boyang Yu, Long Chen, Emilio Vega, Thomas O'Donnell, Seena Dehkharghani, Jennifer A. Frontera, Arjun V. Masurkar, Kara Melmed, Narges Razavian
分类: cs.CV, cs.AI
发布日期: 2025-02-04 (更新: 2025-09-28)
备注: Under Review Preprint
💡 一句话要点
提出FM-CT:用于头部CT图像疾病检测的3D基础模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 头部CT图像 自监督学习 基础模型 疾病检测 3D卷积神经网络
📋 核心要点
- 高质量头部CT图像标注数据稀缺,尤其对于罕见疾病,限制了深度学习模型的发展。
- 提出FM-CT,利用自监督学习在大量未标注的3D头部CT扫描数据上预训练模型,学习可泛化的特征。
- 实验表明,FM-CT在下游诊断任务中显著优于从头训练的模型和之前的3D CT基础模型,提升了诊断性能。
📝 摘要(中文)
头部CT成像是一种广泛使用的医学成像方式,具有多种医学适应症,尤其是在评估大脑、颅骨和脑血管系统的病理方面。由于其图像采集速度快、安全性高、成本低且普遍存在,它通常是神经科急诊的一线成像方式。深度学习模型可以促进多种疾病的检测。然而,高质量标签和注释的稀缺,尤其是在不太常见的疾病中,严重阻碍了强大模型的开发。为了应对这一挑战,我们引入了FM-CT:一种用于头部CT的基础模型,用于可泛化的疾病检测,使用自监督学习进行训练。我们的方法在361,663个非对比3D头部CT扫描的大型多样化数据集上预训练深度学习模型,无需手动注释,使模型能够学习稳健、可泛化的特征。为了研究自监督学习在头部CT中的潜力,我们采用了具有自蒸馏的判别和掩码图像建模,并且我们以3D而不是切片级别(2D)构建我们的模型,以更全面有效地利用头部CT扫描的结构。使用内部和三个外部数据集评估模型的下游分类性能,包括同分布(ID)和异分布(OOD)数据。我们的结果表明,与从头开始训练的模型和以前的3D CT基础模型相比,自监督基础模型显着提高了下游诊断任务的性能。这项工作突出了自监督学习在医学成像中的有效性,并为3D头部CT图像分析设定了新的基准,从而可以更广泛地使用人工智能进行基于头部CT的诊断。
🔬 方法详解
问题定义:论文旨在解决头部CT图像中疾病检测任务中,由于高质量标注数据稀缺导致深度学习模型泛化能力不足的问题。现有方法依赖大量标注数据,难以应用于罕见疾病或新的临床场景。
核心思路:论文的核心思路是利用自监督学习,在大规模未标注的头部CT图像数据上预训练一个基础模型。通过学习图像的内在结构和特征表示,提高模型在下游诊断任务中的泛化能力,减少对标注数据的依赖。
技术框架:FM-CT的整体框架包括两个主要阶段:自监督预训练和下游任务微调。在预训练阶段,模型使用大规模未标注的3D头部CT扫描数据进行训练,采用两种自监督学习方法:具有自蒸馏的判别和掩码图像建模。在下游任务微调阶段,使用少量标注数据对预训练模型进行微调,以适应特定的诊断任务。
关键创新:论文的关键创新在于以下几点:1) 提出了一种基于自监督学习的3D头部CT基础模型,能够有效利用未标注数据学习可泛化的特征表示。2) 结合了具有自蒸馏的判别和掩码图像建模两种自监督学习方法,充分挖掘图像信息。3) 在3D空间中进行建模,能够更全面地利用头部CT扫描的结构信息。
关键设计:在自监督预训练阶段,采用了两种损失函数:判别损失和掩码图像建模损失。判别损失通过自蒸馏的方式,鼓励模型学习一致的特征表示。掩码图像建模损失通过预测被掩盖的图像区域,促使模型学习图像的上下文信息。网络结构基于3D卷积神经网络,具体结构细节未知。
🖼️ 关键图片
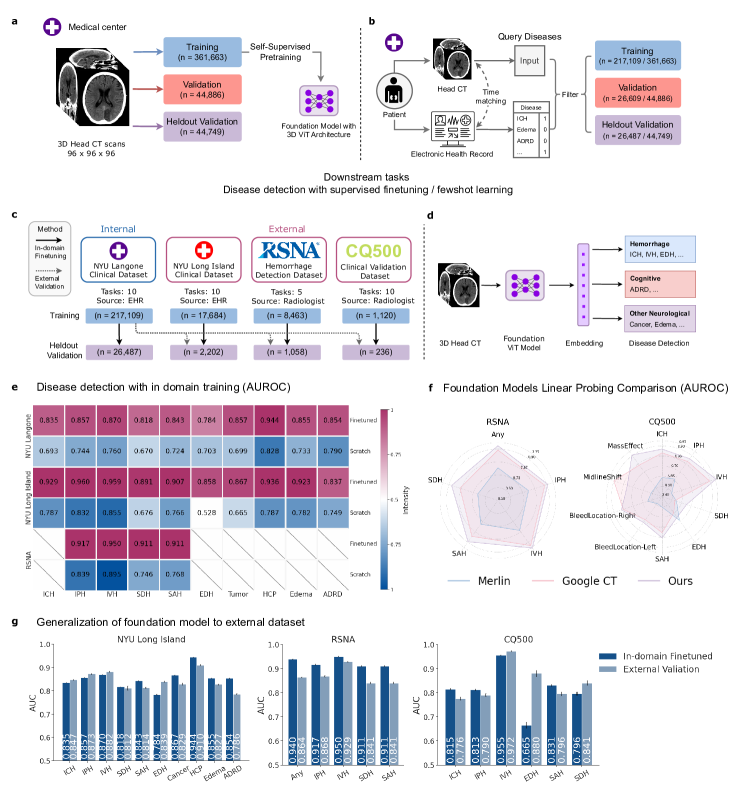
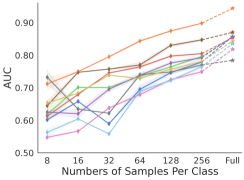
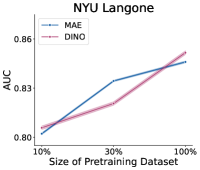
📊 实验亮点
实验结果表明,FM-CT在内部和三个外部数据集上均取得了显著的性能提升。与从头训练的模型相比,FM-CT在下游诊断任务中表现更优,尤其是在异分布(OOD)数据上,验证了其良好的泛化能力。具体性能数据未知,但论文强调了相对于其他3D CT基础模型的显著提升。
🎯 应用场景
该研究成果可应用于多种头部CT图像分析任务,例如脑出血、脑梗塞、肿瘤等疾病的自动检测与诊断。通过减少对标注数据的依赖,降低了模型开发成本,加速了人工智能在医学影像领域的应用,有望辅助医生提高诊断效率和准确性,尤其是在资源有限的医疗机构。
📄 摘要(原文)
Head computed tomography (CT) imaging is a widely-used imaging modality with multitudes of medical indications, particularly in assessing pathology of the brain, skull, and cerebrovascular system. It is commonly the first-line imaging in neurologic emergencies given its rapidity of image acquisition, safety, cost, and ubiquity. Deep learning models may facilitate detection of a wide range of diseases. However, the scarcity of high-quality labels and annotations, particularly among less common conditions, significantly hinders the development of powerful models. To address this challenge, we introduce FM-CT: a Foundation Model for Head CT for generalizable disease detection, trained using self-supervised learning. Our approach pre-trains a deep learning model on a large, diverse dataset of 361,663 non-contrast 3D head CT scans without the need for manual annotations, enabling the model to learn robust, generalizable features. To investigate the potential of self-supervised learning in head CT, we employed both discrimination with self-distillation and masked image modeling, and we construct our model in 3D rather than at the slice level (2D) to exploit the structure of head CT scans more comprehensively and efficiently. The model's downstream classification performance is evaluated using internal and three external datasets, encompassing both in-distribution (ID) and out-of-distribution (OOD) data. Our results demonstrate that the self-supervised foundation model significantly improves performance on downstream diagnostic tasks compared to models trained from scratch and previous 3D CT foundation models on scarce annotated datasets. This work highlights the effectiveness of self-supervised learning in medical imaging and sets a new benchmark for head CT image analysis in 3D, enabling broader use of artificial intelligence for head CT-based diagnosis.