Controllable Video Generation with Provable Disentanglement
作者: Yifan Shen, Peiyuan Zhu, Zijian Li, Shaoan Xie, Namrata Deka, Zongfang Liu, Zeyu Tang, Guangyi Chen, Kun Zhang
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-02-04 (更新: 2025-10-04)
💡 一句话要点
提出CoVoGAN,通过可证明的解耦实现可控视频生成
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 可控视频生成 解耦表示 生成对抗网络 时间建模 视频编辑
📋 核心要点
- 现有可控视频生成方法通常将视频视为整体,忽略了精细的时空关系,限制了控制精度和效率。
- CoVoGAN的核心思想是解耦视频中的静态和动态潜在变量,并利用最小变化原则和充分变化特性实现独立控制。
- 通过在GAN中集成时间转换模块,并在多个视频生成基准上进行验证,显著提升了生成质量和可控性。
📝 摘要(中文)
本文提出了一种可控视频生成对抗网络(CoVoGAN),旨在解耦视频概念,从而实现对各个概念的高效和独立控制。遵循最小变化原则,首先解耦静态和动态潜在变量。然后,利用充分变化特性实现动态潜在变量的组件式可辨识性,从而实现对视频生成的解耦控制。本文提供了严格的理论分析,证明了该方法的可辨识性。基于这些理论见解,设计了一个时间转换模块来解耦潜在动态。为了强制执行最小变化原则和充分变化特性,最小化了潜在动态变量的维度,并施加了时间条件独立性。通过将该模块作为GAN的插件进行集成来验证该方法。在各种视频生成基准上的大量定性和定量实验表明,该方法显著提高了各种真实场景中的生成质量和可控性。
🔬 方法详解
问题定义:现有可控视频生成方法难以精细控制视频内容,因为它们通常将整个视频作为一个整体进行处理,忽略了视频中复杂的时空关系。这导致控制的精度和效率都受到限制,难以实现对视频中各个元素的独立控制。
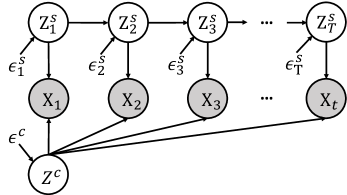
核心思路:CoVoGAN的核心思路是将视频的概念进行解耦,特别是将静态和动态的潜在变量分离。通过解耦,可以独立地控制视频中的各个概念,从而提高控制的精度和效率。此外,论文还利用最小变化原则和充分变化特性来保证解耦的有效性和可辨识性。
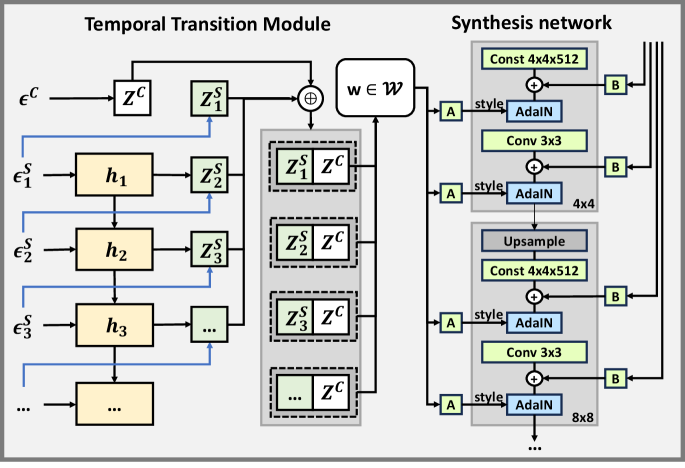
技术框架:CoVoGAN的技术框架主要包括以下几个部分:首先,使用GAN作为基础的生成模型。然后,引入一个时间转换模块(Temporal Transition Module)来解耦潜在动态。该模块被设计成一个插件,可以方便地集成到现有的GAN架构中。为了保证解耦的效果,论文还设计了一系列的损失函数和约束条件。
关键创新:CoVoGAN的关键创新在于其可证明的解耦能力。论文通过理论分析证明了该方法能够有效地解耦视频中的静态和动态潜在变量,并实现对各个变量的独立控制。此外,时间转换模块的设计也是一个重要的创新点,它能够有效地捕捉视频中的时间动态信息。
关键设计:为了强制执行最小变化原则和充分变化特性,论文最小化了潜在动态变量的维度,并施加了时间条件独立性。具体来说,论文使用了KL散度来约束潜在变量的分布,并使用时间对比损失来保证时间动态的一致性。时间转换模块的具体结构未知,但其目标是学习一个能够捕捉视频时间动态的映射函数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CoVoGAN在多个视频生成基准上都取得了显著的性能提升。与现有方法相比,CoVoGAN能够生成更高质量、更可控的视频。具体的性能数据未知,但论文强调了在生成质量和可控性方面的显著改进。
🎯 应用场景
CoVoGAN在视频编辑、内容创作、游戏开发等领域具有广泛的应用前景。例如,用户可以使用CoVoGAN来编辑视频中的人物动作、改变场景的风格、或者生成具有特定故事情节的视频。该技术还可以用于生成逼真的虚拟环境,为游戏开发提供更丰富的素材。
📄 摘要(原文)
Controllable video generation remains a significant challenge, despite recent advances in generating high-quality and consistent videos. Most existing methods for controlling video generation treat the video as a whole, neglecting intricate fine-grained spatiotemporal relationships, which limits both control precision and efficiency. In this paper, we propose Controllable Video Generative Adversarial Networks (CoVoGAN) to disentangle the video concepts, thus facilitating efficient and independent control over individual concepts. Specifically, following the minimal change principle, we first disentangle static and dynamic latent variables. We then leverage the sufficient change property to achieve component-wise identifiability of dynamic latent variables, enabling disentangled control of video generation. To establish the theoretical foundation, we provide a rigorous analysis demonstrating the identifiability of our approach. Building on these theoretical insights, we design a Temporal Transition Module to disentangle latent dynamics. To enforce the minimal change principle and sufficient change property, we minimize the dimensionality of latent dynamic variables and impose temporal conditional independence. To validate our approach, we integrate this module as a plug-in for GANs. Extensive qualitative and quantitative experiments on various video generation benchmarks demonstrate that our method significantly improves generation quality and controllability across diverse real-world scenarios.