Particle Trajectory Representation Learning with Masked Point Modeling
作者: Sam Young, Yeon-jae Jwa, Kazuhiro Terao
分类: hep-ex, cs.CV, cs.LG
发布日期: 2025-02-04 (更新: 2025-07-06)
备注: Preprint. 28 pages, 18 figures. v3 includes new results on data efficiency and attention maps
💡 一句话要点
提出PoLAr-MAE,利用掩码点建模实现LArTPC图像的自监督粒子轨迹表示学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自监督学习 掩码点建模 LArTPC 粒子轨迹 表示学习
📋 核心要点
- LArTPC数据分析依赖有偏的监督学习,需要探索无监督方法。
- 提出PoLAr-MAE,使用掩码点建模和领域知识进行自监督学习。
- 仅用100个标注样本微调,性能媲美10万+样本训练的监督模型。
📝 摘要(中文)
有效的自监督学习(SSL)技术一直是解锁大型数据集进行表征学习的关键。虽然已经开发了许多有前途的方法,使用在线语料库和带有标题的照片,但它们在科学领域的应用仍然是一个挑战,因为这些领域的数据编码了高度专业化的知识。液氩时间投影室(LArTPC)为基础物理提供高分辨率3D成像,但对其稀疏、复杂的点云数据的分析通常依赖于在大型模拟上训练的监督方法,这引入了潜在的偏差。我们引入了基于点的液氩掩码自动编码器(PoLAr-MAE),它使用特定领域的体素化标记和能量预测,将掩码点建模应用于未标记的LArTPC图像。我们表明,这种SSL方法直接从数据中学习物理上有意义的轨迹表示。这产生了显著的数据效率:在仅100个标记事件上进行微调,实现了与在>100,000个事件上训练的最先进的监督基线相当的轨迹/簇语义分割性能。此外,内部注意力图表现出粒子轨迹的新兴实例分割。虽然仍然存在挑战,特别是对于细粒度特征,但我们使SSL在构建LArTPC图像分析的基础模型方面的潜力具体化,该模型能够作为所有数据重建任务的通用基础。为了促进进一步的进展,我们发布了PILArNet-M,一个包含100万个LArTPC事件的大型数据集。项目网站:https://youngsm.com/polarmae。
🔬 方法详解
问题定义:LArTPC(Liquid Argon Time Projection Chamber)产生高分辨率的3D粒子轨迹图像,但对其进行分析通常依赖于在大量模拟数据上训练的监督学习方法。这种方法的痛点在于,模拟数据本身可能存在偏差,从而影响最终分析结果的准确性。此外,获取大量标注数据成本高昂。
核心思路:论文的核心思路是利用自监督学习(SSL)方法,从大量的未标注LArTPC数据中学习到有意义的粒子轨迹表示。通过掩码点建模,迫使模型理解和重建被遮盖的区域,从而学习到数据内在的物理规律和结构信息。这样可以减少对标注数据的依赖,并降低模拟数据偏差的影响。
技术框架:PoLAr-MAE的整体框架是一个基于掩码自动编码器(MAE)的结构。首先,将LArTPC图像进行体素化标记(volumetric tokenization),将3D空间划分为小的体素单元。然后,随机掩盖掉一部分体素单元,并将剩余的体素单元输入到编码器中。编码器学习这些可见体素的表示,并将这些表示传递给解码器。解码器的目标是重建被掩盖的体素单元的能量值。通过最小化重建误差,模型学习到LArTPC数据的内在表示。
关键创新:该论文的关键创新在于将掩码点建模应用于LArTPC图像的自监督学习,并结合了领域特定的体素化标记和能量预测。这种方法能够有效地从无标注数据中学习到物理上有意义的轨迹表示,从而显著提高了数据效率。此外,论文还发现,模型的内部注意力图能够涌现出粒子轨迹的实例分割,这表明模型学习到了数据的深层结构信息。
关键设计:论文中关键的设计包括:1) 领域特定的体素化标记,根据LArTPC数据的特点,将3D空间划分为合适的体素大小;2) 能量预测作为重建目标,利用了LArTPC数据中能量信息的物理意义;3) 掩码比例的选择,需要平衡模型的学习难度和信息保留;4) 注意力机制的应用,帮助模型关注重要的特征区域。
🖼️ 关键图片


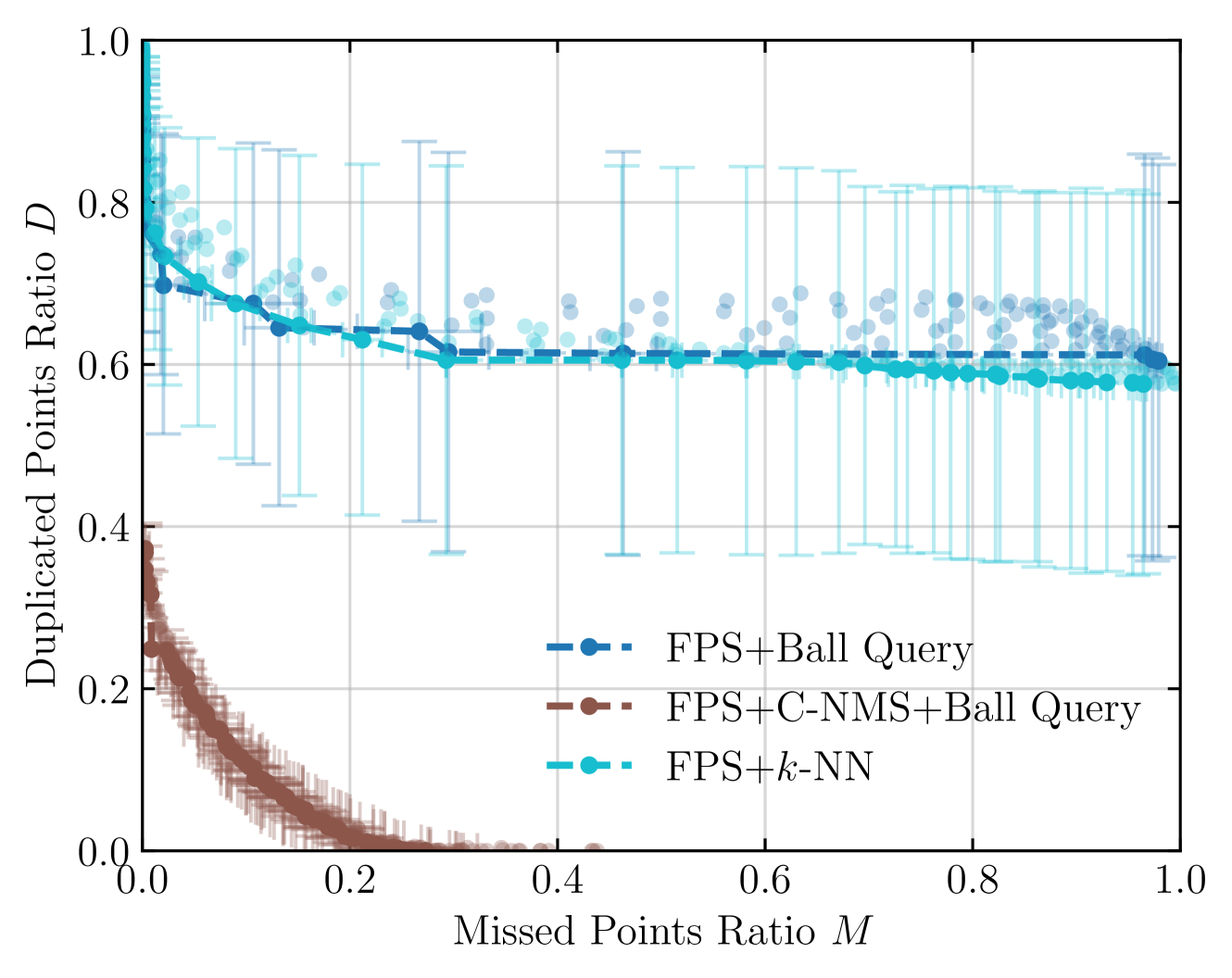
📊 实验亮点
PoLAr-MAE在仅使用100个标注事件进行微调后,实现了与在超过10万个事件上训练的最先进的监督基线相当的轨迹/簇语义分割性能。这表明该方法具有显著的数据效率,能够极大地减少对标注数据的需求。此外,内部注意力图表现出粒子轨迹的新兴实例分割,进一步验证了模型学习到的表示的有效性。
🎯 应用场景
该研究成果可应用于高能物理实验中LArTPC数据的分析与重建,例如中微子振荡研究、暗物质探测等。通过自监督学习,可以减少对模拟数据的依赖,提高数据分析的准确性和效率。未来,该方法有望推广到其他科学领域,例如医学图像分析、材料科学等。
📄 摘要(原文)
Effective self-supervised learning (SSL) techniques have been key to unlocking large datasets for representation learning. While many promising methods have been developed using online corpora and captioned photographs, their application to scientific domains, where data encodes highly specialized knowledge, remains a challenge. Liquid Argon Time Projection Chambers (LArTPCs) provide high-resolution 3D imaging for fundamental physics, but analysis of their sparse, complex point cloud data often relies on supervised methods trained on large simulations, introducing potential biases. We introduce the Point-based Liquid Argon Masked Autoencoder (PoLAr-MAE), applying masked point modeling to unlabeled LArTPC images using domain-specific volumetric tokenization and energy prediction. We show this SSL approach learns physically meaningful trajectory representations directly from data. This yields remarkable data efficiency: fine-tuning on just 100 labeled events achieves track/shower semantic segmentation performance comparable to the state-of-the-art supervised baseline trained on $>$100,000 events. Furthermore, internal attention maps exhibit emergent instance segmentation of particle trajectories. While challenges remain, particularly for fine-grained features, we make concrete SSL's potential for building a foundation model for LArTPC image analysis capable of serving as a common base for all data reconstruction tasks. To facilitate further progress, we release PILArNet-M, a large dataset of 1M LArTPC events. Project site: https://youngsm.com/polarmae.