Diff9D: Diffusion-Based Domain-Generalized Category-Level 9-DoF Object Pose Estimation
作者: Jian Liu, Wei Sun, Hui Yang, Pengchao Deng, Chongpei Liu, Nicu Sebe, Hossein Rahmani, Ajmal Mian
分类: cs.CV, cs.RO
发布日期: 2025-02-04
备注: 17 pages, 13 figures
期刊: IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
DOI: 10.1109/TPAMI.2025.3552132
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于扩散模型的域泛化9自由度物体姿态估计方法Diff9D
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 9自由度姿态估计 域泛化 扩散模型 类别级物体 机器人抓取
📋 核心要点
- 现有类别级物体姿态估计方法依赖大量真实数据,标注成本高昂,且泛化性受限。
- Diff9D利用扩散模型强大的生成能力,仅用合成数据训练,实现对真实场景的域泛化。
- 实验表明,Diff9D在基准数据集和真实机器人系统中均取得SOTA性能,并接近实时。
📝 摘要(中文)
本文提出了一种基于扩散模型的域泛化类别级9自由度物体姿态估计方法。类别级方法因其对类内未知物体的泛化潜力而备受关注。然而,这些方法需要手动收集和标注大规模真实世界训练数据。为了解决这个问题,我们利用扩散模型的潜在泛化能力来应对物体姿态估计中的域泛化挑战。该模型仅在渲染的合成数据上进行训练,以实现对真实世界场景的泛化。我们提出了一个有效的扩散模型,从生成角度重新定义了9自由度物体姿态估计。我们的模型在训练或推理过程中不需要任何3D形状先验。通过采用去噪扩散隐式模型,我们证明了反向扩散过程可以在短短3步内执行,从而实现接近实时的性能。最后,我们设计了一个包含硬件和软件组件的机器人抓取系统。通过在两个基准数据集和真实世界机器人系统上的综合实验,我们表明我们的方法实现了最先进的域泛化性能。代码将在https://github.com/CNJianLiu/Diff9D上公开。
🔬 方法详解
问题定义:论文旨在解决类别级9自由度物体姿态估计中的域泛化问题。现有方法依赖于大量真实世界标注数据,获取成本高,且模型在合成数据上训练后,难以泛化到真实场景。因此,如何在仅使用合成数据训练的情况下,实现对真实世界场景的精确姿态估计,是本文要解决的核心问题。
核心思路:论文的核心思路是利用扩散模型强大的生成能力和潜在的泛化能力。通过将9自由度姿态估计问题转化为一个生成问题,模型学习从噪声中生成目标物体的姿态。由于扩散模型在图像生成等任务中表现出良好的泛化性能,因此可以期望其在姿态估计任务中也能实现较好的域泛化能力。
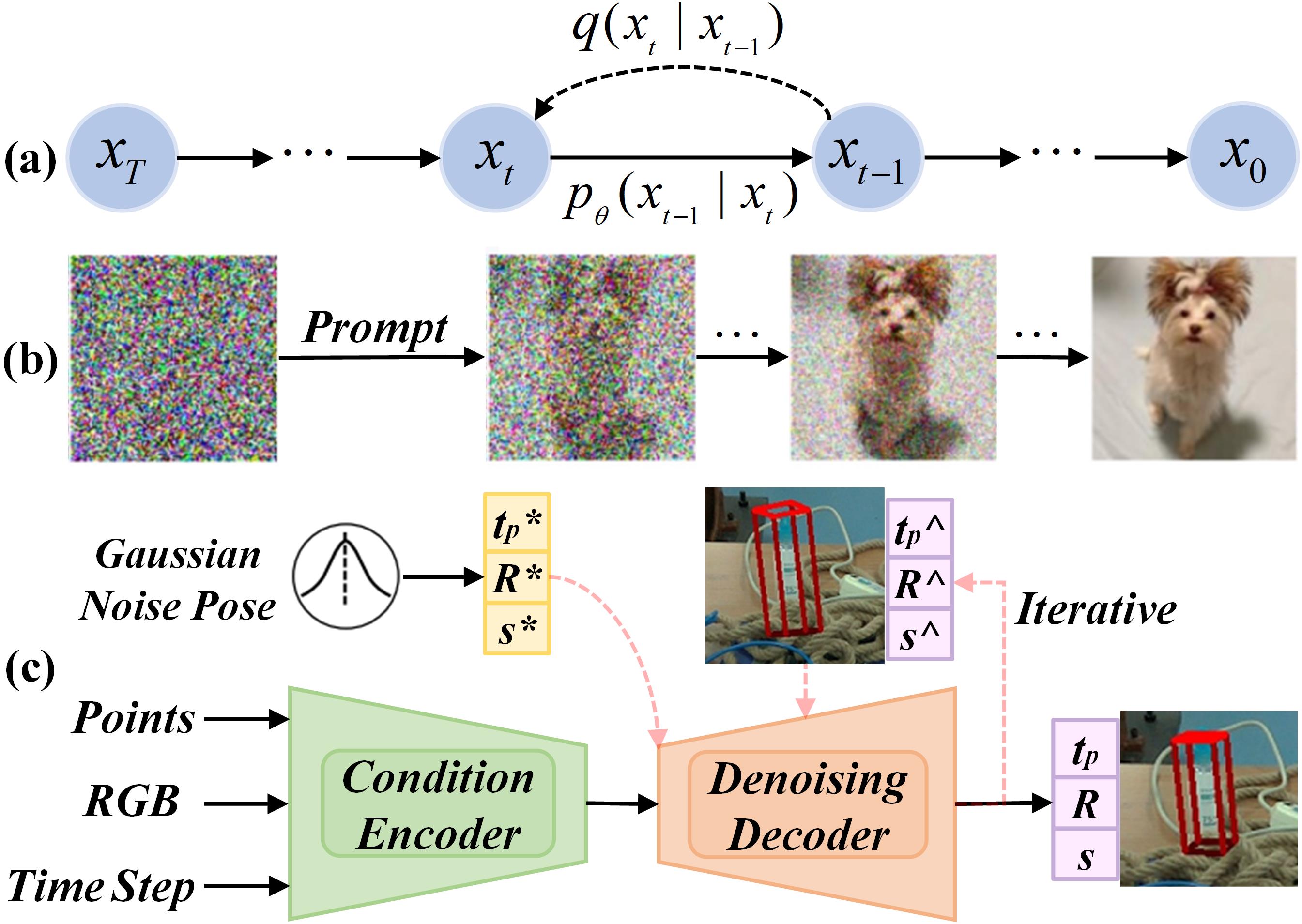
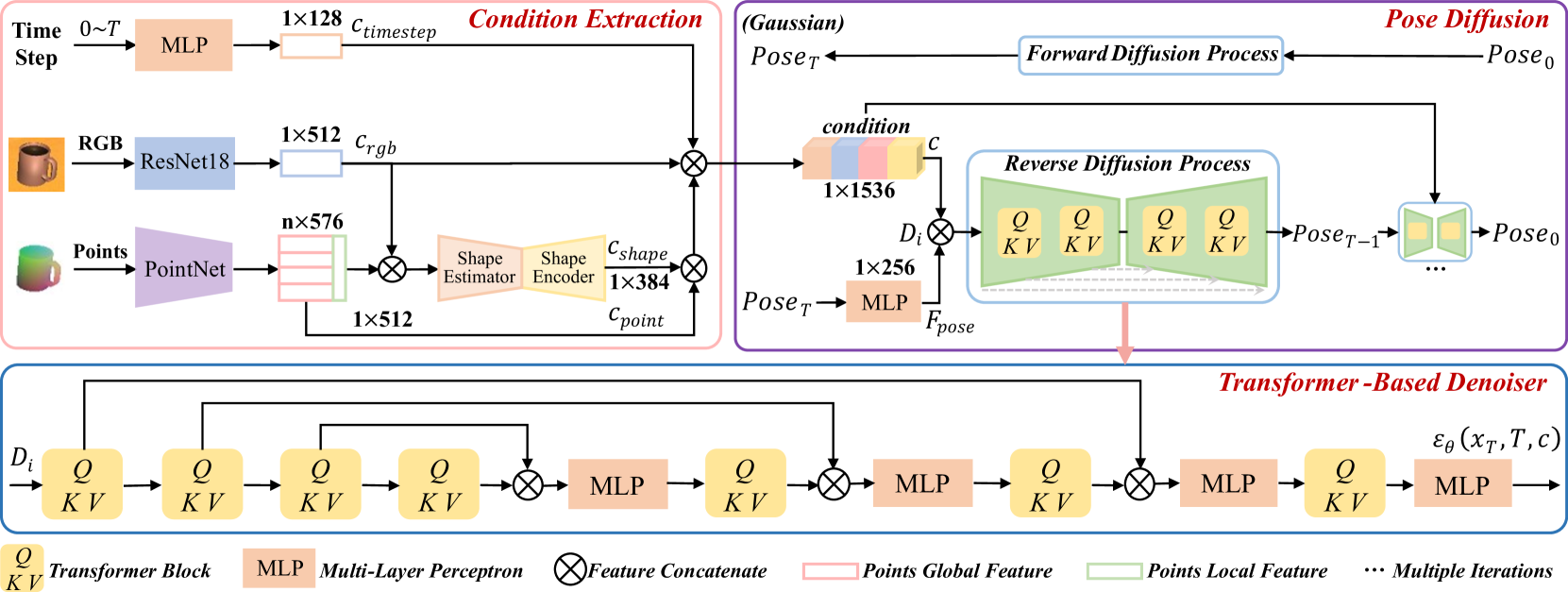
技术框架:Diff9D采用Denoising Diffusion Implicit Model (DDIM) 作为其核心框架。整体流程包括:1) 前向扩散过程,将真实的9自由度姿态逐步加入噪声,直至完全变为噪声;2) 反向扩散过程,从纯噪声出发,逐步去噪,最终生成目标物体的9自由度姿态。该模型在训练阶段仅使用合成数据,在推理阶段则可以直接应用于真实场景。
关键创新:Diff9D的关键创新在于将扩散模型引入到类别级9自由度物体姿态估计任务中,并利用其生成能力实现域泛化。与传统方法依赖于3D形状先验或大量真实数据不同,Diff9D无需任何3D形状先验,仅使用合成数据进行训练,即可实现对真实场景的姿态估计。此外,通过DDIM,反向扩散过程可以仅用少量步骤完成,从而实现接近实时的性能。
关键设计:Diff9D采用DDIM作为反向扩散过程的加速方法,通过调整采样步数,可以在精度和速度之间进行权衡。论文中提到,仅需3步即可实现接近实时的性能。损失函数的设计主要基于扩散模型的训练目标,即最小化预测噪声与真实噪声之间的差异。具体的网络结构细节(如U-Net的具体配置)在论文中可能有所描述,但摘要中未明确提及。
🖼️ 关键图片

📊 实验亮点
Diff9D在两个基准数据集上取得了SOTA的域泛化性能,证明了其有效性。此外,通过采用DDIM,该方法能够在短短3步内完成反向扩散过程,实现接近实时的性能,使其更具实用价值。在真实机器人系统上的实验也验证了该方法在实际应用中的可行性。
🎯 应用场景
Diff9D在增强现实、机器人操作等领域具有广泛的应用前景。例如,在AR应用中,可以用于准确估计虚拟物体在真实场景中的姿态,从而实现更逼真的AR体验。在机器人操作中,可以用于引导机器人抓取和操作各种物体,尤其是在未知物体的情况下,其域泛化能力更具优势。该研究有助于推动机器人技术在复杂环境中的应用。
📄 摘要(原文)
Nine-degrees-of-freedom (9-DoF) object pose and size estimation is crucial for enabling augmented reality and robotic manipulation. Category-level methods have received extensive research attention due to their potential for generalization to intra-class unknown objects. However, these methods require manual collection and labeling of large-scale real-world training data. To address this problem, we introduce a diffusion-based paradigm for domain-generalized category-level 9-DoF object pose estimation. Our motivation is to leverage the latent generalization ability of the diffusion model to address the domain generalization challenge in object pose estimation. This entails training the model exclusively on rendered synthetic data to achieve generalization to real-world scenes. We propose an effective diffusion model to redefine 9-DoF object pose estimation from a generative perspective. Our model does not require any 3D shape priors during training or inference. By employing the Denoising Diffusion Implicit Model, we demonstrate that the reverse diffusion process can be executed in as few as 3 steps, achieving near real-time performance. Finally, we design a robotic grasping system comprising both hardware and software components. Through comprehensive experiments on two benchmark datasets and the real-world robotic system, we show that our method achieves state-of-the-art domain generalization performance. Our code will be made public at https://github.com/CNJianLiu/Diff9D.