Mind the Gap: Evaluating Patch Embeddings from General-Purpose and Histopathology Foundation Models for Cell Segmentation and Classification
作者: Valentina Vadori, Antonella Peruffo, Jean-Marie Graïc, Livio Finos, Enrico Grisan
分类: cs.CV, cs.AI, cs.LG, q-bio.QM
发布日期: 2025-02-04
💡 一句话要点
对比通用与病理学预训练模型,评估细胞分割与分类中的Patch Embedding性能差距
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 预训练模型 细胞分割 细胞分类 数字病理学 表征学习 病理学图像分析 深度学习 Transformer
📋 核心要点
- 现有方法在细胞分析任务中,对通用预训练模型和病理学预训练模型的性能差异缺乏深入研究。
- 本文通过比较两类模型提取的patch embedding在细胞分割和分类任务中的表现,分析其表征学习的差距。
- 实验结果表明,领域相关的病理学预训练模型在特定任务上可能优于通用模型,为模型选择提供参考。
📝 摘要(中文)
近年来,预训练模型显著提升了计算机视觉性能,包括数字病理学领域。然而,对于细胞分析等特定任务,领域相关的病理学预训练模型相对于通用模型的优势尚不明确。本研究通过分析多层patch embedding,探讨这两类模型在细胞实例分割和分类中的表征学习差距。我们采用统一的解码器,搭配卷积、ViT和混合编码器,这些编码器预训练于ImageNet-22K或LVD-142M(通用模型),并与UNI、Virchow2和Prov-GigaPath(病理学模型)的ViT编码器进行比较。解码器通过跳跃连接整合不同编码器深度的patch embedding,生成语义图和距离图,用于细胞实例分割和细胞类型分类。所有编码器在训练期间保持冻结,以评估其预训练特征提取能力。我们在PanNuke、CoNIC和新引入的Nissl染色CytoDArk0数据集上,评估了实例级别的检测、分割精度和细胞类型分类性能,为细胞病理学和脑细胞结构分析中的模型选择提供指导。
🔬 方法详解
问题定义:论文旨在解决细胞分析任务中,如何选择合适的预训练模型的问题。现有方法缺乏对通用预训练模型和领域特定(病理学)预训练模型在细胞分割和分类任务中性能差异的系统性评估,导致模型选择缺乏理论依据。
核心思路:论文的核心思路是通过比较不同预训练模型提取的patch embedding在细胞分割和分类任务中的表现,来分析它们在表征学习上的差异。通过冻结编码器,专注于评估预训练特征的质量,从而揭示通用模型和病理学模型各自的优势和局限性。
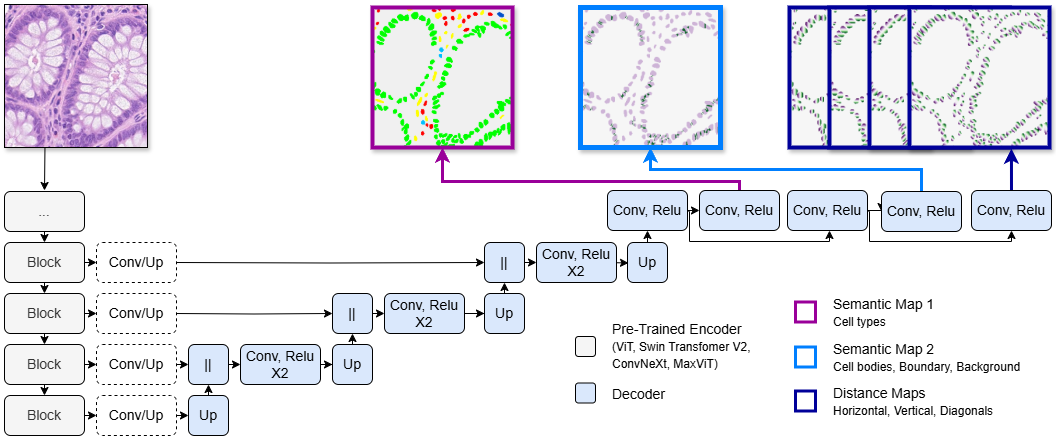
技术框架:整体框架是一个编码器-解码器结构。编码器部分使用不同的预训练模型,包括通用模型(ImageNet-22K, LVD-142M预训练的卷积、ViT和混合模型)和病理学模型(UNI, Virchow2, Prov-GigaPath预训练的ViT模型)。解码器部分保持一致,通过跳跃连接整合来自不同编码器深度的特征。解码器的输出是语义图和距离图,用于后续的细胞实例分割和细胞类型分类。
关键创新:论文的关键创新在于对通用预训练模型和病理学预训练模型在细胞分析任务中的表征学习能力进行了直接比较。通过冻结编码器,避免了微调带来的影响,更纯粹地评估了预训练特征的质量。此外,论文还引入了新的Nissl染色CytoDArk0数据集,用于脑细胞结构研究。
关键设计:编码器部分使用了多种预训练模型,包括不同架构(卷积、ViT、混合)和不同训练数据集(ImageNet-22K, LVD-142M, 病理学WSI数据集)。解码器部分使用了跳跃连接,将来自不同编码器深度的特征进行融合,以提高分割和分类的性能。损失函数未知,但推测使用了适用于分割和分类任务的常用损失函数,如交叉熵损失和Dice损失。
🖼️ 关键图片

📊 实验亮点
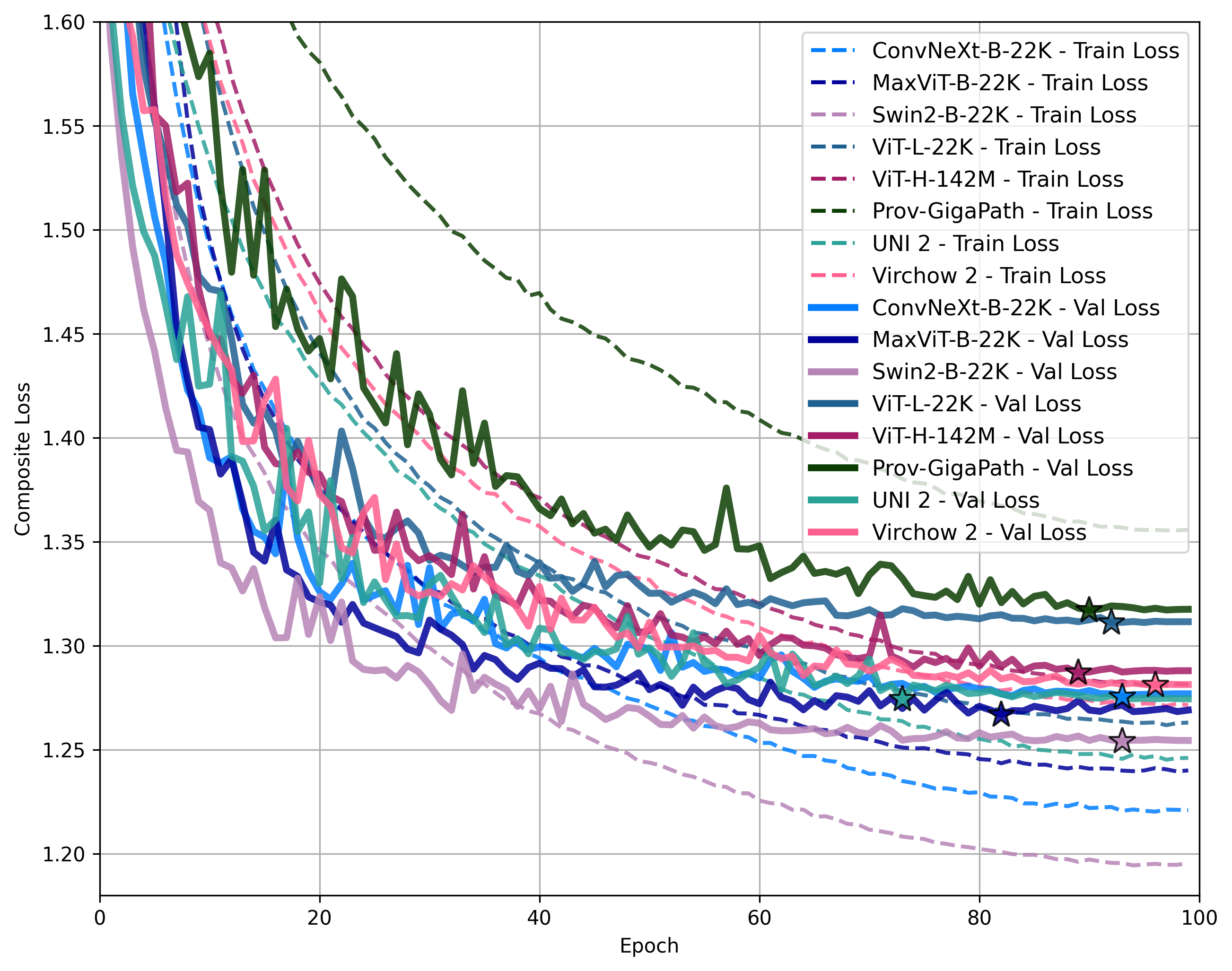
实验结果表明,在PanNuke和CoNIC数据集上,病理学预训练模型在细胞分割和分类任务中表现出一定的优势。特别是在新引入的Nissl染色CytoDArk0数据集上,病理学预训练模型展现了更强的特征提取能力。具体的性能提升幅度未知,但研究结果为模型选择提供了重要的参考依据。
🎯 应用场景
该研究成果可应用于数字病理学领域,辅助病理学家进行细胞级别的分析,例如细胞分割、细胞类型识别和细胞计数。通过选择合适的预训练模型,可以提高细胞分析的准确性和效率,从而加速疾病诊断和治疗方案的制定。此外,该研究方法也可推广到其他医学图像分析任务中。
📄 摘要(原文)
Recent advancements in foundation models have transformed computer vision, driving significant performance improvements across diverse domains, including digital histopathology. However, the advantages of domain-specific histopathology foundation models over general-purpose models for specialized tasks such as cell analysis remain underexplored. This study investigates the representation learning gap between these two categories by analyzing multi-level patch embeddings applied to cell instance segmentation and classification. We implement an encoder-decoder architecture with a consistent decoder and various encoders. These include convolutional, vision transformer (ViT), and hybrid encoders pre-trained on ImageNet-22K or LVD-142M, representing general-purpose foundation models. These are compared against ViT encoders from the recently released UNI, Virchow2, and Prov-GigaPath foundation models, trained on patches extracted from hundreds of thousands of histopathology whole-slide images. The decoder integrates patch embeddings from different encoder depths via skip connections to generate semantic and distance maps. These maps are then post-processed to create instance segmentation masks where each label corresponds to an individual cell and to perform cell-type classification. All encoders remain frozen during training to assess their pre-trained feature extraction capabilities. Using the PanNuke and CoNIC histopathology datasets, and the newly introduced Nissl-stained CytoDArk0 dataset for brain cytoarchitecture studies, we evaluate instance-level detection, segmentation accuracy, and cell-type classification. This study provides insights into the comparative strengths and limitations of general-purpose vs. histopathology foundation models, offering guidance for model selection in cell-focused histopathology and brain cytoarchitecture analysis workflows.