MotionLab: Unified Human Motion Generation and Editing via the Motion-Condition-Motion Paradigm
作者: Ziyan Guo, Zeyu Hu, De Wen Soh, Na Zhao
分类: cs.CV
发布日期: 2025-02-04 (更新: 2025-07-22)
备注: Accepted by ICCV 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
MotionLab:通过运动-条件-运动范式统一生成和编辑人体运动
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion)
关键词: 人体运动生成 人体运动编辑 运动-条件-运动范式 校正流 多任务学习
📋 核心要点
- 现有的人体运动生成和编辑方法缺乏统一性,难以进行细粒度控制和跨任务知识共享。
- MotionLab 提出“运动-条件-运动”范式,利用校正流学习条件引导下的源运动到目标运动的映射。
- MotionLab 在多个基准测试中表现出良好的泛化能力和推理效率,无需特定任务模块。
📝 摘要(中文)
人体运动生成和编辑是计算机视觉的关键组成部分。然而,目前的方法倾向于提供针对特定任务的孤立解决方案,这在实际应用中效率低下且不实用。虽然一些工作旨在统一运动相关任务,但这些方法仅使用不同的模态作为条件来指导运动生成。因此,它们缺乏编辑能力、细粒度控制,并且无法促进跨任务的知识共享。为了解决这些限制,并提供一个能够处理人体运动生成和编辑的多功能统一框架,我们引入了一种新的范式:运动-条件-运动,它能够使用三个概念统一制定各种任务:源运动、条件和目标运动。基于此范式,我们提出了一个统一的框架MotionLab,它结合了校正流来学习从源运动到目标运动的映射,并由指定的条件引导。在MotionLab中,我们引入了1) MotionFlow Transformer,以增强条件生成和编辑,而无需特定于任务的模块;2) 对齐旋转位置编码,以保证源运动和目标运动之间的时间同步;3) 任务指定指令调制;以及4) 运动课程学习,以实现有效的多任务学习和跨任务的知识共享。值得注意的是,我们的MotionLab在人体运动的多个基准测试中展示了有希望的泛化能力和推理效率。我们的代码和其他视频结果可在https://diouo.github.io/motionlab.github.io/上找到。
🔬 方法详解
问题定义:现有的人体运动生成和编辑方法通常是孤立的,针对特定任务设计,缺乏通用性和灵活性。它们难以实现细粒度的编辑控制,并且无法有效地在不同运动任务之间共享知识。这限制了它们在实际应用中的潜力。
核心思路:MotionLab 的核心思路是提出一种新的“运动-条件-运动”范式,将各种运动生成和编辑任务统一建模为:给定源运动和条件,生成目标运动。这种范式能够灵活地处理不同类型的条件,例如文本描述、其他运动序列或约束条件,从而实现更广泛的任务覆盖和更精细的控制。
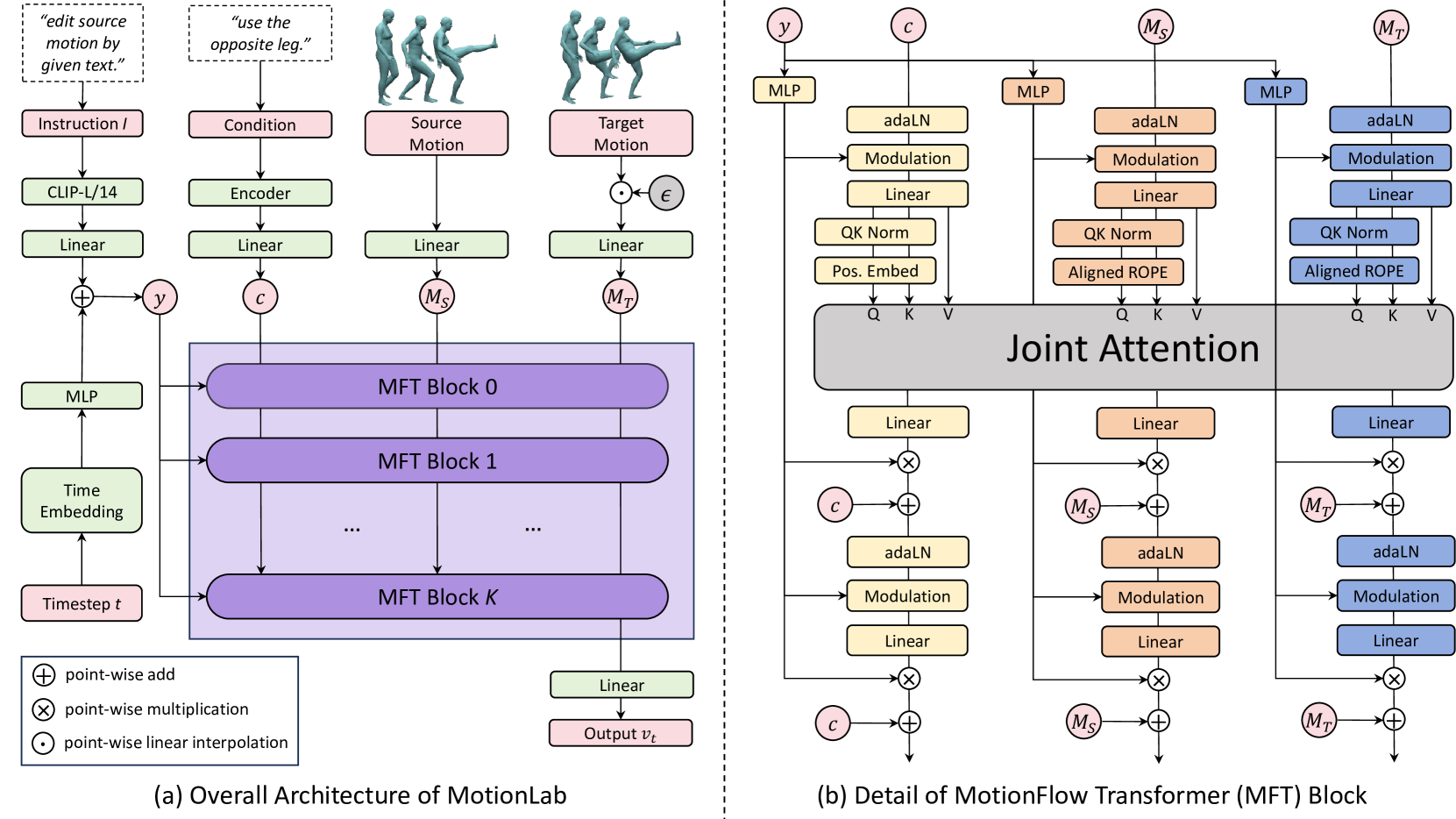
技术框架:MotionLab 的整体框架包括以下几个主要模块:1) MotionFlow Transformer:用于学习源运动到目标运动的映射,并根据条件进行调整。2) 对齐旋转位置编码:确保源运动和目标运动在时间上同步。3) 任务指定指令调制:根据不同的任务类型调整模型的行为。4) 运动课程学习:用于有效地进行多任务学习,并促进跨任务的知识共享。该框架使用校正流来学习运动之间的映射关系。
关键创新:MotionLab 的关键创新在于“运动-条件-运动”范式,它提供了一种统一的方式来处理各种人体运动生成和编辑任务。此外,MotionFlow Transformer 能够增强条件生成和编辑能力,而无需针对特定任务设计模块,提高了模型的泛化能力。
关键设计:MotionFlow Transformer 的具体结构未知,但可以推测其利用了 Transformer 架构的优势,例如自注意力机制,来捕捉运动序列中的长期依赖关系。对齐旋转位置编码的具体实现方式未知,但其目的是保证源运动和目标运动在时间维度上的对齐。运动课程学习的具体策略未知,但其目标是逐步增加训练难度,从而提高模型的学习效率和泛化能力。
🖼️ 关键图片


📊 实验亮点
MotionLab 在多个公开的人体运动数据集上进行了评估,包括 Human3.6M 和 AMASS。实验结果表明,MotionLab 在运动生成和编辑任务上都取得了有竞争力的性能。特别是在一些复杂的编辑任务上,MotionLab 能够生成更自然、更符合条件的运动序列。论文中提到 MotionLab 具有良好的泛化能力和推理效率,但没有提供具体的性能数据和提升幅度。
🎯 应用场景
MotionLab 有潜力应用于各种领域,例如虚拟现实、游戏开发、动画制作、机器人控制和康复训练。它可以用于生成逼真的人体运动,编辑现有运动序列,并根据用户指定的条件生成新的运动。该研究的实际价值在于提供了一个统一、灵活和高效的框架,可以简化人体运动生成和编辑的流程,并提高相关应用的质量和效率。未来,MotionLab 可以进一步扩展到处理更复杂的运动场景,例如多人交互和物理约束。
📄 摘要(原文)
Human motion generation and editing are key components of computer vision. However, current approaches in this field tend to offer isolated solutions tailored to specific tasks, which can be inefficient and impractical for real-world applications. While some efforts have aimed to unify motion-related tasks, these methods simply use different modalities as conditions to guide motion generation. Consequently, they lack editing capabilities, fine-grained control, and fail to facilitate knowledge sharing across tasks. To address these limitations and provide a versatile, unified framework capable of handling both human motion generation and editing, we introduce a novel paradigm: \textbf{Motion-Condition-Motion}, which enables the unified formulation of diverse tasks with three concepts: source motion, condition, and target motion. Based on this paradigm, we propose a unified framework, \textbf{MotionLab}, which incorporates rectified flows to learn the mapping from source motion to target motion, guided by the specified conditions. In MotionLab, we introduce the 1) MotionFlow Transformer to enhance conditional generation and editing without task-specific modules; 2) Aligned Rotational Position Encoding to guarantee the time synchronization between source motion and target motion; 3) Task Specified Instruction Modulation; and 4) Motion Curriculum Learning for effective multi-task learning and knowledge sharing across tasks. Notably, our MotionLab demonstrates promising generalization capabilities and inference efficiency across multiple benchmarks for human motion. Our code and additional video results are available at: https://diouo.github.io/motionlab.github.io/.