UNIP: Rethinking Pre-trained Attention Patterns for Infrared Semantic Segmentation
作者: Tao Zhang, Jinyong Wen, Zhen Chen, Kun Ding, Shiming Xiang, Chunhong Pan
分类: cs.CV
发布日期: 2025-02-04 (更新: 2025-03-20)
备注: ICLR 2025. 27 pages, 13 figures, 21 tables
🔗 代码/项目: GITHUB
💡 一句话要点
UNIP:重新思考红外语义分割的预训练注意力模式
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 红外语义分割 预训练 注意力机制 领域自适应 知识蒸馏
📋 核心要点
- 现有预训练方法在红外语义分割中,由于领域差异大,性能提升有限,且对不同注意力模式的理解不足。
- UNIP框架通过混合注意力蒸馏、大规模混合数据集预训练和最后一层特征金字塔网络微调,提升红外语义分割性能。
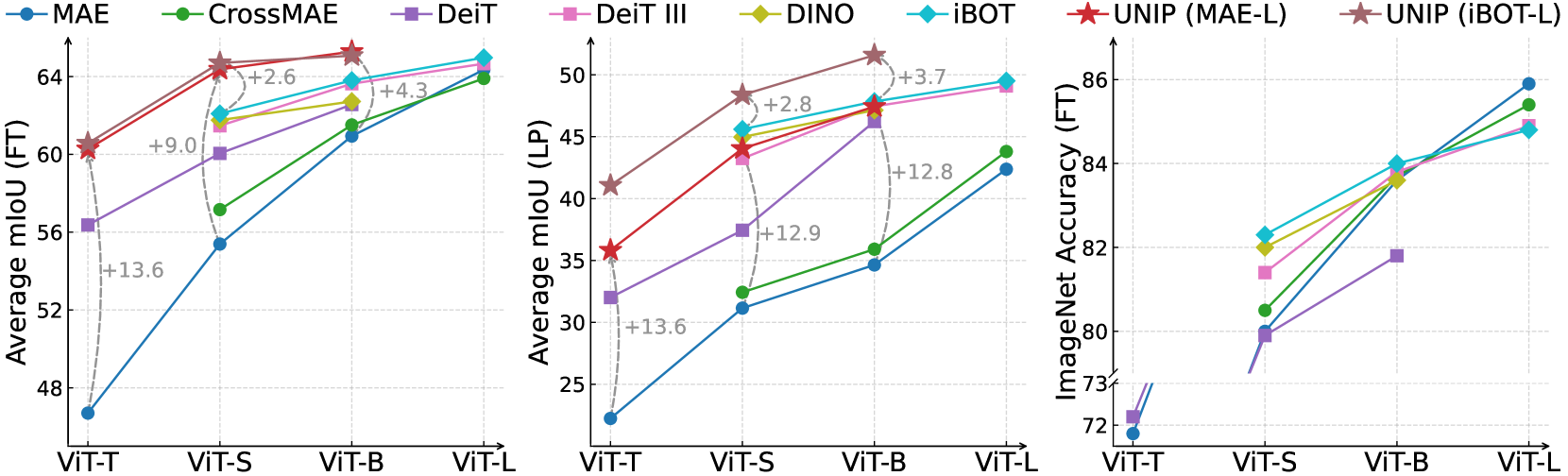
- 实验表明,UNIP在红外分割任务上显著优于现有预训练方法,平均mIoU提升高达13.5%,且计算成本更低。
📝 摘要(中文)
预训练技术显著提升了语义分割任务在有限训练数据下的性能。然而,预训练(如RGB)和微调(如红外)之间存在较大领域差距时,其有效性仍未得到充分探索。本研究首先对各种预训练方法在红外语义分割上的性能进行了基准测试,揭示了与RGB领域不同的现象。接下来,我们对预训练注意力图进行逐层分析,发现:(1)存在三种典型的注意力模式(局部、混合和全局);(2)预训练任务显著影响跨层的模式分布;(3)混合模式对于语义分割至关重要,因为它同时关注附近和前景元素;(4)纹理偏差阻碍了模型在红外任务中的泛化。基于这些见解,我们提出了UNIP,一个统一的红外预训练框架,以提高预训练模型的性能。该框架使用混合注意力蒸馏NMI-HAD作为预训练目标,一个大规模混合数据集InfMix用于预训练,以及一个最后一层特征金字塔网络LL-FPN用于微调。实验结果表明,UNIP在三个红外分割任务上,通过微调和线性探测指标评估,平均mIoU优于各种预训练方法高达13.5%。UNIP-S实现了与MAE-L相当的性能,同时仅需1/10的计算成本。此外,UNIP显著超越了最先进的红外或RGB分割方法,并展示了在其他模态(如RGB和深度)中的广泛应用潜力。
🔬 方法详解
问题定义:论文旨在解决红外图像语义分割中,由于与RGB图像存在较大领域差异,直接应用RGB图像预训练模型效果不佳的问题。现有方法未能充分利用红外图像的特性,并且忽略了不同注意力模式对分割性能的影响。
核心思路:论文的核心思路是设计一个专门针对红外图像的预训练框架UNIP,通过分析预训练注意力模式,发现混合注意力模式的重要性,并以此为指导,设计混合注意力蒸馏目标,从而提升模型在红外图像上的泛化能力。
技术框架:UNIP框架包含三个主要组成部分:1) 混合注意力蒸馏NMI-HAD:作为预训练的目标,鼓励模型学习混合注意力模式。2) 大规模混合数据集InfMix:用于预训练,包含多种红外图像数据,增强模型的鲁棒性。3) 最后一层特征金字塔网络LL-FPN:用于微调,提升模型对红外图像细节的感知能力。整体流程为:首先使用InfMix数据集和NMI-HAD目标预训练模型,然后使用LL-FPN进行微调,最终完成红外图像语义分割任务。
关键创新:论文的关键创新在于:1) 首次系统性地分析了预训练注意力模式对红外语义分割的影响,发现了混合注意力模式的重要性。2) 提出了混合注意力蒸馏NMI-HAD,能够有效地引导模型学习混合注意力模式。3) 构建了大规模混合数据集InfMix,为红外图像预训练提供了数据支持。
关键设计:NMI-HAD损失函数的设计是关键,它通过蒸馏的方式,让学生网络学习教师网络的混合注意力模式。InfMix数据集包含了多种红外图像数据,并进行了数据增强,以提高模型的泛化能力。LL-FPN的设计旨在充分利用最后一层特征,提升模型对红外图像细节的感知能力。具体的参数设置和网络结构细节可以在论文原文中找到。
🖼️ 关键图片


📊 实验亮点
UNIP在三个红外语义分割任务上取得了显著的性能提升,平均mIoU优于现有预训练方法高达13.5%。UNIP-S在仅使用1/10计算成本的情况下,实现了与MAE-L相当的性能。此外,UNIP还超越了当前最先进的红外或RGB分割方法,证明了其优越性和泛化能力。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、安防监控、工业检测等领域。在这些场景中,红外图像能够提供可见光图像无法提供的环境信息,例如在夜间或恶劣天气条件下。UNIP框架能够有效提升红外图像语义分割的精度,从而提高相关系统的可靠性和智能化水平,具有重要的实际应用价值和广阔的发展前景。
📄 摘要(原文)
Pre-training techniques significantly enhance the performance of semantic segmentation tasks with limited training data. However, the efficacy under a large domain gap between pre-training (e.g. RGB) and fine-tuning (e.g. infrared) remains underexplored. In this study, we first benchmark the infrared semantic segmentation performance of various pre-training methods and reveal several phenomena distinct from the RGB domain. Next, our layerwise analysis of pre-trained attention maps uncovers that: (1) There are three typical attention patterns (local, hybrid, and global); (2) Pre-training tasks notably influence the pattern distribution across layers; (3) The hybrid pattern is crucial for semantic segmentation as it attends to both nearby and foreground elements; (4) The texture bias impedes model generalization in infrared tasks. Building on these insights, we propose UNIP, a UNified Infrared Pre-training framework, to enhance the pre-trained model performance. This framework uses the hybrid-attention distillation NMI-HAD as the pre-training target, a large-scale mixed dataset InfMix for pre-training, and a last-layer feature pyramid network LL-FPN for fine-tuning. Experimental results show that UNIP outperforms various pre-training methods by up to 13.5\% in average mIoU on three infrared segmentation tasks, evaluated using fine-tuning and linear probing metrics. UNIP-S achieves performance on par with MAE-L while requiring only 1/10 of the computational cost. Furthermore, UNIP significantly surpasses state-of-the-art (SOTA) infrared or RGB segmentation methods and demonstrates broad potential for application in other modalities, such as RGB and depth. Our code is available at https://github.com/casiatao/UNIP.