Efficiently Integrate Large Language Models with Visual Perception: A Survey from the Training Paradigm Perspective
作者: Xiaorui Ma, Haoran Xie, S. Joe Qin
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2025-02-03
备注: 28 pages, 3 figures
💡 一句话要点
综述视觉-语言大模型训练范式,聚焦参数高效的模态融合方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 大型语言模型 参数高效学习 训练范式 模态融合
📋 核心要点
- 现有视觉-语言大模型综述主要关注双阶段训练,忽略了训练范式的演变和参数高效性。
- 本文从训练范式角度,对视觉-语言大模型进行分类和回顾,重点关注参数高效的模态融合方法。
- 通过比较代表性模型的实验结果,深入分析不同训练范式在参数效率方面的有效性,并复现了直接适配范式的实验。
📝 摘要(中文)
视觉-语言模态的融合一直是多模态学习的重要方向,传统上依赖于视觉-语言预训练模型。然而,随着大型语言模型(LLM)的出现,将LLM与视觉模态相结合已成为一种显著趋势。随之而来的是,将视觉模态整合到LLM中的训练范式也在不断发展。最初的方法是通过预训练模态整合器来整合模态,称为单阶段调整。此后,它又分支为侧重于性能增强的方法(双阶段调整)和优先考虑参数效率的方法(直接适配)。然而,现有的综述主要关注采用双阶段调整的最新视觉大型语言模型(VLLM),未能充分理解训练范式的演变及其独特的参数效率考量。本文对来自顶级会议、期刊和高引用的Arxiv论文中的34个VLLM进行了分类和回顾,重点关注从训练范式角度出发的适配过程中的参数效率。我们首先介绍了LLM的架构和参数高效学习方法,然后讨论了视觉编码器和模态整合器的综合分类。接着,我们回顾了三种训练范式及其效率考量,并总结了VLLM领域的基准。为了更深入地了解它们在参数效率方面的有效性,我们比较和讨论了代表性模型的实验结果,其中复制了直接适配范式的实验。本综述提供了对最新发展和实际应用的见解,是研究人员和从业人员高效地将视觉模态整合到LLM中的重要指南。
🔬 方法详解
问题定义:现有视觉-语言模型通常采用两阶段训练方法,计算成本高昂,参数效率较低。如何高效地将视觉信息融入大型语言模型,同时保持较小的参数规模,是当前研究面临的关键问题。现有综述对参数高效的训练范式关注不足。
核心思路:本文的核心在于从训练范式的角度对现有的视觉-语言大模型进行分类和分析,重点关注参数高效的训练方法。通过对比不同训练范式的优缺点,为研究人员提供选择合适训练策略的指导。
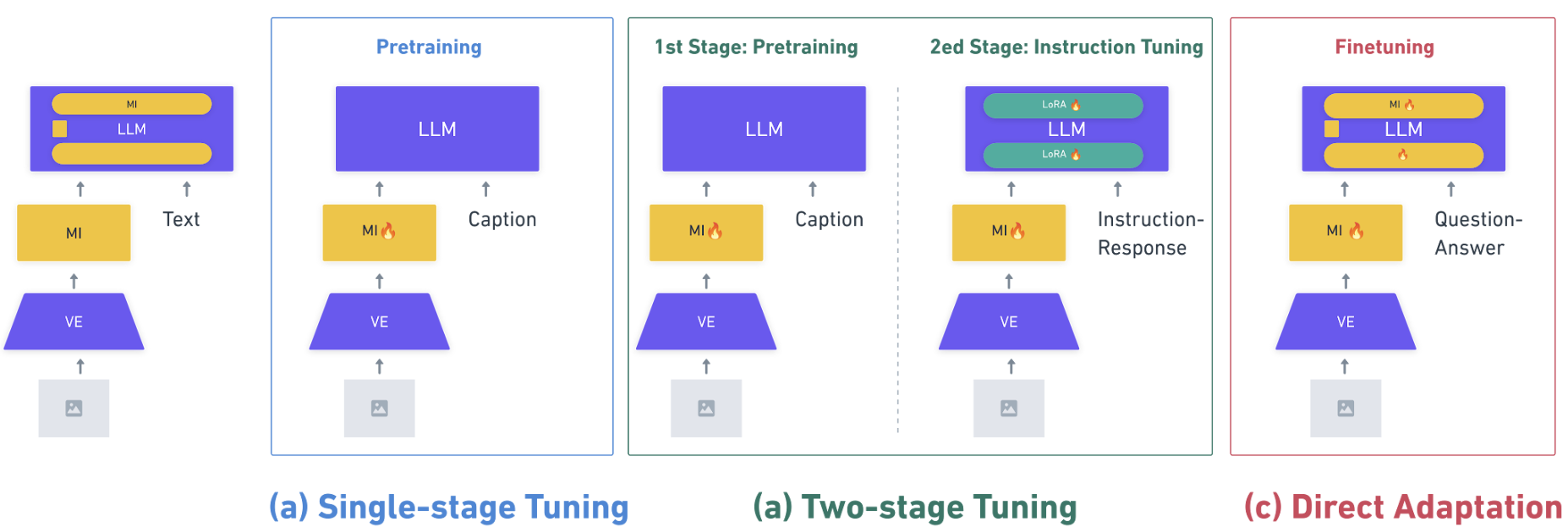
技术框架:本文首先介绍LLM的架构和参数高效学习方法,然后讨论视觉编码器和模态整合器的分类。接着,回顾了三种训练范式:单阶段调整、双阶段调整和直接适配,并分析了它们的效率考量。最后,总结了VLLM领域的基准,并比较了代表性模型的实验结果。
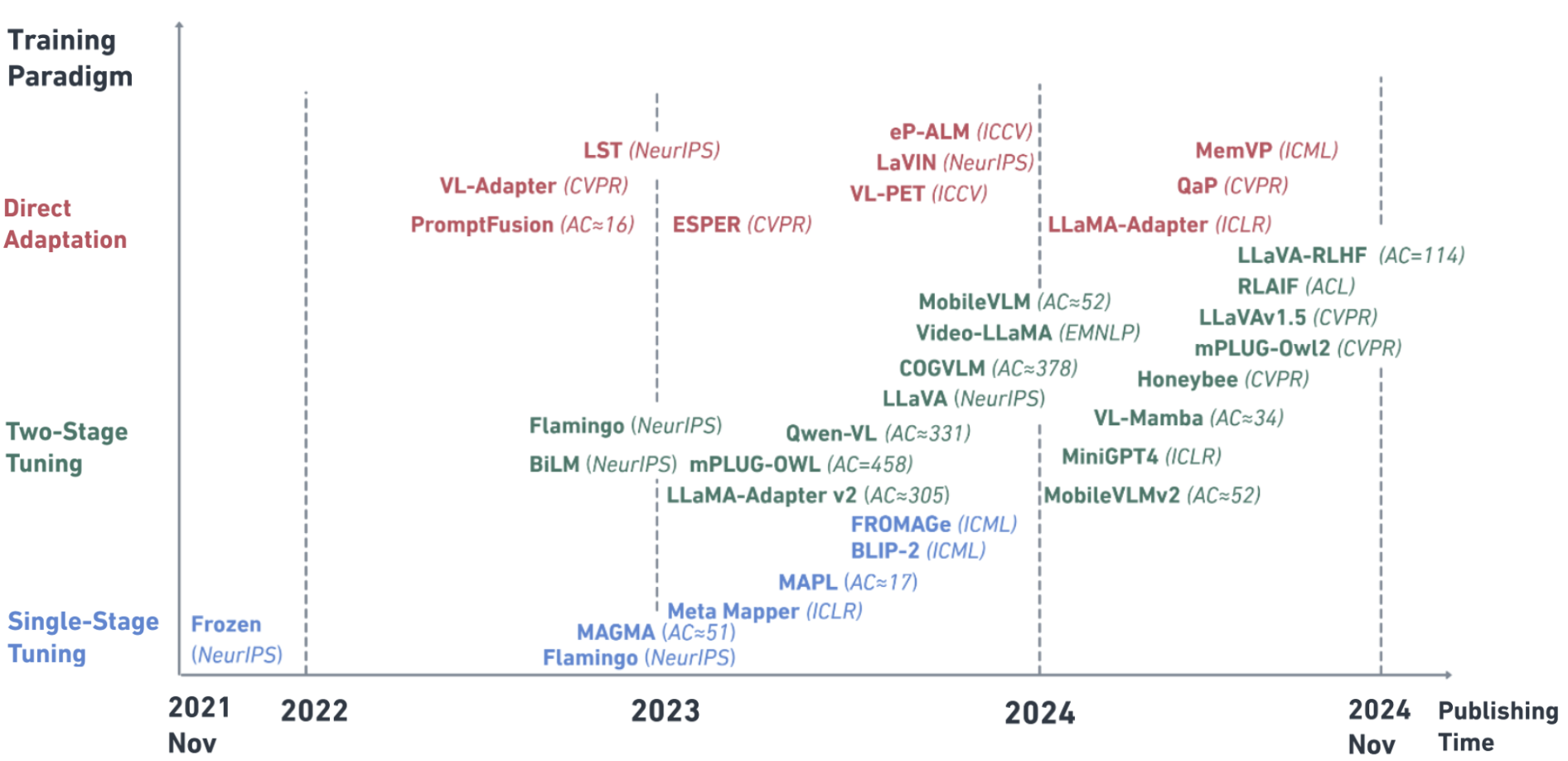
关键创新:本文的创新之处在于:1) 从训练范式的角度对视觉-语言大模型进行系统性的分类和回顾;2) 重点关注参数高效的训练方法,为研究人员提供更实用的指导;3) 复现了直接适配范式的实验,验证了其在参数效率方面的优势。
关键设计:本文对34个VLLM模型进行了分析,涵盖了单阶段调整、双阶段调整和直接适配三种训练范式。在实验部分,作者复现了直接适配范式的实验,并与其他范式进行了比较。具体的技术细节包括:视觉编码器的选择、模态整合器的设计、损失函数的设置等。这些细节影响着模型的性能和参数效率。
🖼️ 关键图片

📊 实验亮点
本文对三种训练范式进行了比较,发现直接适配范式在参数效率方面具有优势。通过复现直接适配范式的实验,验证了其在保持性能的同时,能够显著减少参数数量。具体的性能数据和对比基线在论文中有详细描述,为研究人员提供了参考。
🎯 应用场景
该研究成果可应用于各种需要视觉信息辅助的自然语言处理任务,例如图像描述生成、视觉问答、视觉推理等。通过高效地融合视觉和语言信息,可以提升模型的性能和泛化能力,使其在实际应用中更具竞争力。未来的研究可以进一步探索更有效的参数高效训练方法,以降低计算成本,并扩展到更多模态的融合。
📄 摘要(原文)
The integration of vision-language modalities has been a significant focus in multimodal learning, traditionally relying on Vision-Language Pretrained Models. However, with the advent of Large Language Models (LLMs), there has been a notable shift towards incorporating LLMs with vision modalities. Following this, the training paradigms for incorporating vision modalities into LLMs have evolved. Initially, the approach was to integrate the modalities through pretraining the modality integrator, named Single-stage Tuning. It has since branched out into methods focusing on performance enhancement, denoted as Two-stage Tuning, and those prioritizing parameter efficiency, referred to as Direct Adaptation. However, existing surveys primarily address the latest Vision Large Language Models (VLLMs) with Two-stage Tuning, leaving a gap in understanding the evolution of training paradigms and their unique parameter-efficient considerations. This paper categorizes and reviews 34 VLLMs from top conferences, journals, and highly cited Arxiv papers, focusing on parameter efficiency during adaptation from the training paradigm perspective. We first introduce the architecture of LLMs and parameter-efficient learning methods, followed by a discussion on vision encoders and a comprehensive taxonomy of modality integrators. We then review three training paradigms and their efficiency considerations, summarizing benchmarks in the VLLM field. To gain deeper insights into their effectiveness in parameter efficiency, we compare and discuss the experimental results of representative models, among which the experiment of the Direct Adaptation paradigm is replicated. Providing insights into recent developments and practical uses, this survey is a vital guide for researchers and practitioners navigating the efficient integration of vision modalities into LLMs.