PixelWorld: How Far Are We from Perceiving Everything as Pixels?
作者: Zhiheng Lyu, Xueguang Ma, Wenhu Chen
分类: cs.CV, cs.CL
发布日期: 2025-01-31 (更新: 2025-10-21)
💡 一句话要点
提出PixelWorld基准,探索“万物皆像素”的统一感知范式,用于评估视觉-语言模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉-语言模型 统一感知 像素表示 Transformer Agentic模型 PixelWorld 思维链提示
📋 核心要点
- 现有Agentic语言模型在处理视觉和文本紧密结合的真实世界环境时,缺乏统一的感知范式。
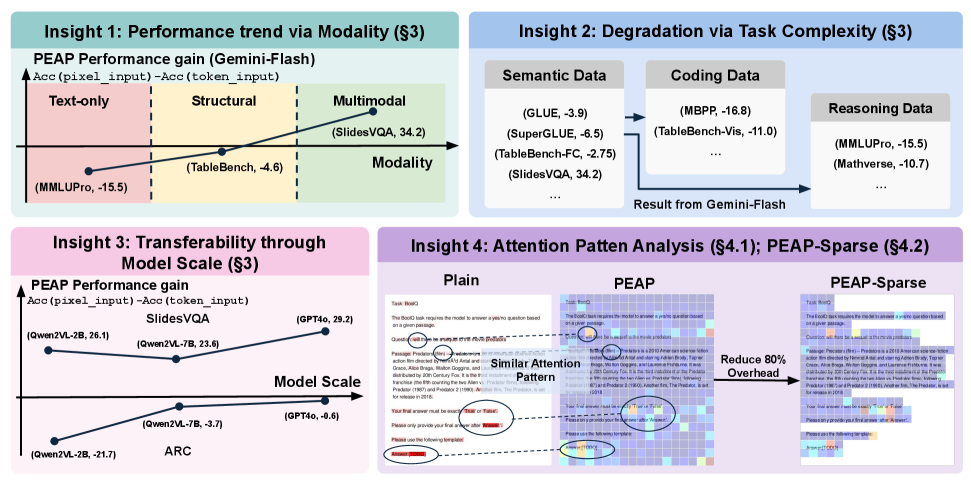
- 论文提出“万物皆像素”(PEAP)概念,将不同模态信息渲染到共享像素空间,并构建PixelWorld基准。
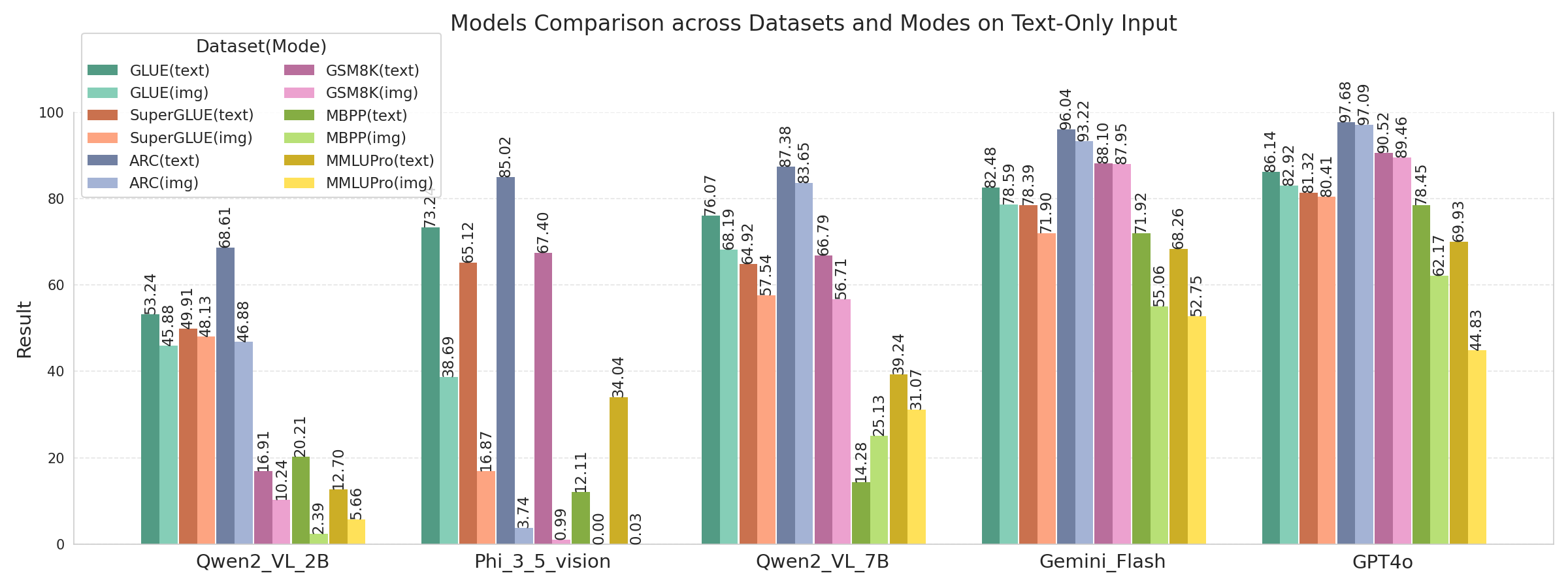
- 实验表明,PEAP在语义理解任务上表现可与token方法媲美,但在推理任务上性能下降,可通过思维链提示缓解。
📝 摘要(中文)
随着Agentic语言模型越来越多地与包含紧密交织的视觉和文本信息的真实世界环境交互(通常通过原始相机像素而非单独处理的图像和分词文本),统一的感知范式变得至关重要。为了研究这一思想,本文探索了“万物皆像素”(Perceive Everything as Pixels, PEAP)的概念,并提出了PixelWorld基准,该基准将自然语言、表格、数学和图表输入渲染到共享的像素空间中。在多个基准测试上的实验表明,PEAP在语义理解任务上实现了与基于token的方法相当的性能,表明视觉Transformer可以在没有显式分词的情况下部分捕获全局文本语义。相比之下,数学和代码等推理密集型任务的性能显著下降,但思维链提示(Chain-of-Thought prompting)有助于弥补这一差距,因为它补偿了缺失的符号结构。此外,研究发现,当视觉和文本信息紧密集成时,将所有内容表示为像素可以简化预处理并避免跨模态错位。因此,PixelWorld为评估统一的视觉-语言模型提供了一个系统而实用的框架,并促进了对基于像素的多模态学习的进一步探索。
🔬 方法详解
问题定义:现有Agentic语言模型需要处理包含紧密交织的视觉和文本信息的真实世界环境,但传统方法通常分别处理图像和文本,导致跨模态对齐困难,且预处理复杂。因此,需要一种统一的感知范式,能够直接从原始像素输入中理解和推理。
核心思路:论文的核心思路是将所有输入(包括文本、表格、数学公式、图表等)都渲染成像素,从而实现统一的视觉表示。这样,模型就可以直接从像素级别理解和处理多模态信息,避免了复杂的预处理和跨模态对齐问题。这种方法简化了输入流程,并允许模型学习不同模态之间的内在联系。
技术框架:PixelWorld基准包含多个任务,涵盖语义理解和推理。输入数据被渲染成像素图像,然后输入到视觉Transformer模型中进行处理。模型输出用于执行各种任务,例如文本分类、表格理解、数学问题求解等。为了提高推理能力,论文还采用了思维链提示(Chain-of-Thought prompting)技术,引导模型逐步推理。
关键创新:最重要的创新点在于提出了“万物皆像素”(PEAP)的统一感知范式,并构建了PixelWorld基准。与传统方法相比,PEAP避免了显式的分词和跨模态对齐,简化了输入流程,并允许模型直接从像素级别学习多模态信息。PixelWorld基准提供了一个系统而实用的框架,用于评估统一的视觉-语言模型。
关键设计:PixelWorld基准包含多种类型的数据,例如自然语言、表格、数学公式、图表等。这些数据被渲染成像素图像,并用于训练和评估视觉Transformer模型。论文采用了标准的视觉Transformer架构,并使用交叉熵损失函数进行训练。思维链提示通过在输入中添加中间推理步骤来引导模型进行推理。具体参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在语义理解任务上,PEAP方法可以达到与基于token的方法相当的性能,证明了视觉Transformer在没有显式分词的情况下捕获全局文本语义的能力。虽然在推理任务上性能有所下降,但通过使用思维链提示,可以显著提高模型的推理能力,缩小与传统方法的差距。具体性能数据和提升幅度未在摘要中详细说明,属于未知信息。
🎯 应用场景
该研究成果可应用于各种需要处理多模态信息的场景,例如智能文档处理、视觉问答、机器人导航等。通过将所有信息表示为像素,可以简化系统的设计和部署,并提高模型的泛化能力。未来,该研究有望推动统一的视觉-语言模型的发展,并促进人工智能在更广泛领域的应用。
📄 摘要(原文)
Recent agentic language models increasingly need to interact with real-world environments that contain tightly intertwined visual and textual information, often through raw camera pixels rather than separately processed images and tokenized text. This shift highlights the need for a unified perception paradigm. To investigate this idea, we explore Perceive Everything as Pixels (PEAP) and introduce PixelWorld, a benchmark that renders natural-language, tabular, mathematical, and diagrammatic inputs into a shared pixel space. Experiments across multiple benchmarks show that PEAP achieves comparable performance to token-based approaches on semantic understanding tasks, suggesting that vision transformers can partially capture global textual semantics without explicit tokenization. In contrast, reasoning-intensive tasks such as mathematics and code show notable performance degradation, although Chain-of-Thought prompting helps mitigate this gap by compensating for missing symbolic structure. We further find that when visual and textual information are closely integrated, representing everything as pixels simplifies preprocessing and avoids cross-modal misalignment. PixelWorld thus provides a systematic and practical framework for evaluating unified vision--language models and facilitates further exploration of pixel-based multimodal learning.