GDO:Gradual Domain Osmosis
作者: Zixi Wang, Yubo Huang
分类: cs.CV
发布日期: 2025-01-31 (更新: 2025-10-13)
备注: restoring v1 because of an incorrect replacement
💡 一句话要点
提出渐进域渗透(GDO)方法,解决渐进领域自适应中的知识迁移问题。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 渐进领域自适应 领域自适应 知识迁移 自训练 领域渗透
📋 核心要点
- 传统GDA方法依赖中间域和自训练,但面临知识迁移效率低和中间域数据缺失的挑战。
- GDO方法通过动态调整源域和目标域的损失权重,实现知识迁移强度的渐进调整。
- 实验结果表明,GDO在多个数据集上优于现有方法,验证了其有效性和优越性。
📝 摘要(中文)
本文提出了一种名为渐进域渗透(GDO)的新方法,旨在解决渐进领域自适应(GDA)中从源域到目标域的平滑知识迁移问题。传统的渐进领域自适应方法通过引入中间域和自训练策略来缓解领域偏差,但通常面临知识迁移效率低下或中间域数据缺失的挑战。本文设计了一个基于超参数λ的优化框架,通过动态平衡源域和目标域的损失权重,使模型能够在训练过程中逐步调整知识迁移的强度(λ从0增加到1),从而更有效地实现跨域泛化。具体来说,该方法结合了自训练来生成伪标签,并通过最小化加权损失函数迭代更新模型,以确保在中间域中渐进适应过程中的稳定性和鲁棒性。实验部分验证了该方法在旋转MNIST、颜色偏移MNIST、人像数据集和森林覆盖类型数据集上的有效性,结果表明该方法优于现有的基线方法。本文进一步通过消融实验分析了超参数λ的动态调整策略对性能的影响,证实了渐进域渗透在缓解领域偏差和增强模型泛化能力方面的优势。该研究为渐近领域自适应提供了理论支持和实践框架,并扩展了其在动态环境中的应用潜力。
🔬 方法详解
问题定义:论文旨在解决渐进领域自适应(GDA)中,知识从源域平滑迁移到目标域的问题。现有方法,如基于中间域和自训练的方法,存在知识迁移效率低下,或者中间域数据缺失的问题,导致模型泛化能力受限。
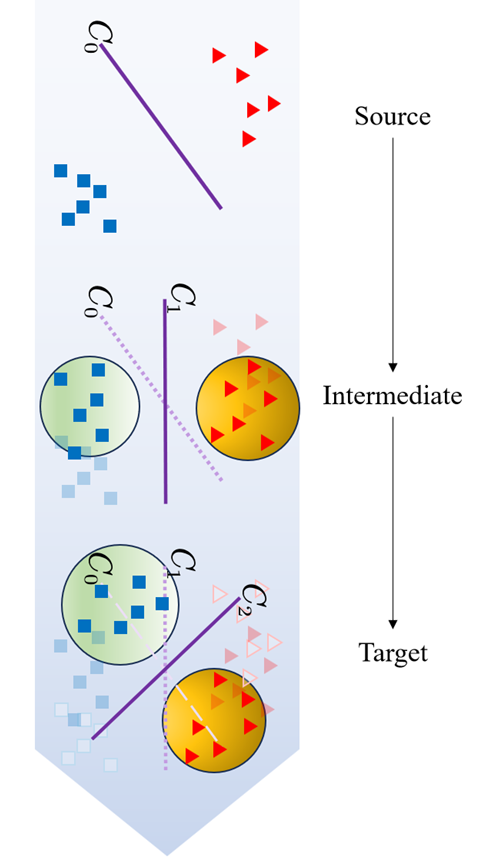
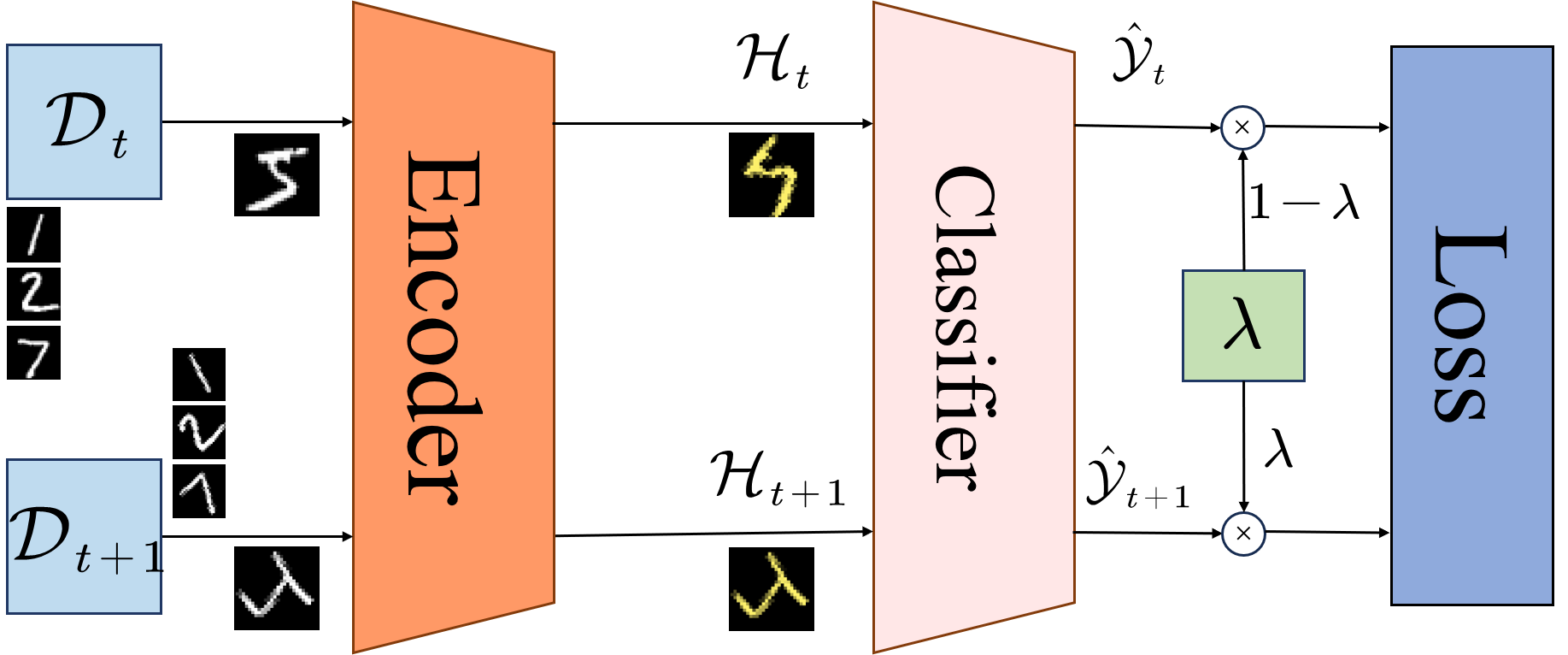
核心思路:论文的核心思路是模拟渗透过程,通过超参数λ动态平衡源域和目标域的损失权重,使模型逐步从源域知识渗透到目标域知识。λ从0到1的递增过程,代表了知识迁移强度的渐进调整,从而实现更高效的跨域泛化。
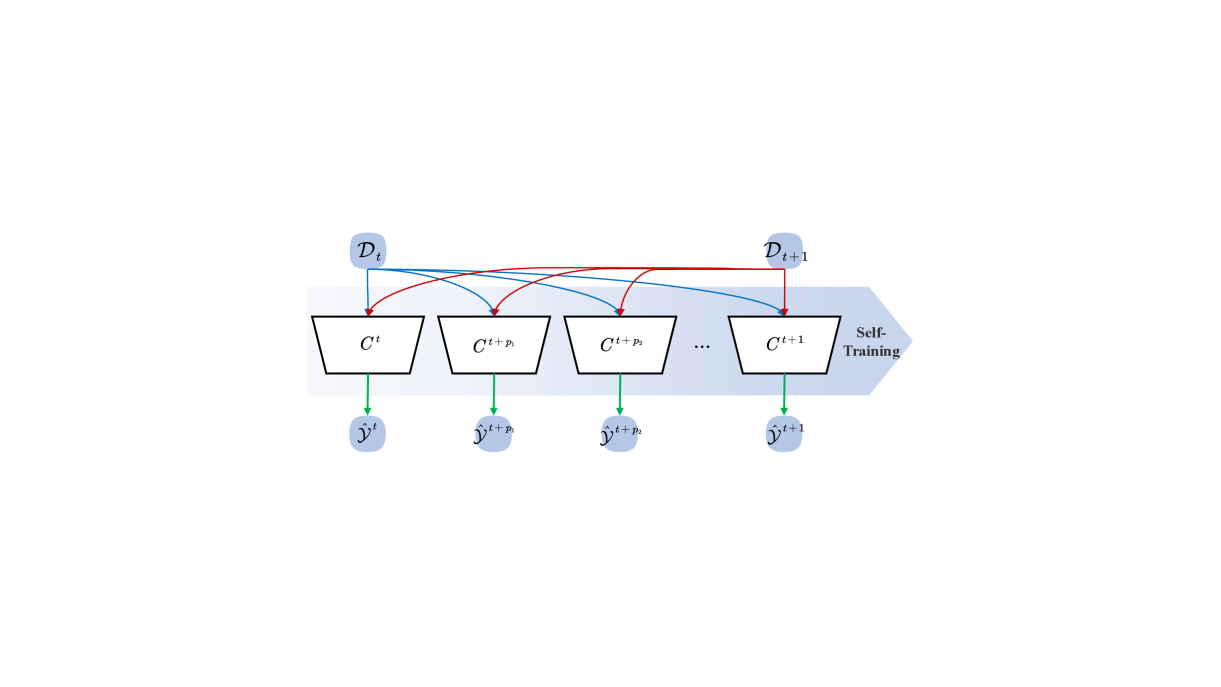
技术框架:GDO方法包含以下主要阶段:1) 初始化模型;2) 在每个训练迭代中,根据超参数λ计算源域和目标域的加权损失;3) 使用自训练生成目标域的伪标签;4) 通过最小化加权损失函数,迭代更新模型参数。整个过程旨在确保模型在中间域渐进适应过程中的稳定性和鲁棒性。
关键创新:GDO的关键创新在于动态调整超参数λ,实现知识迁移强度的渐进控制。与传统方法中固定或手动调整的迁移策略不同,GDO能够根据训练过程自适应地调整迁移强度,从而更有效地缓解领域偏差。
关键设计:GDO的关键设计包括:1) 超参数λ的动态调整策略,例如线性递增或基于性能的自适应调整;2) 加权损失函数的设计,用于平衡源域和目标域的损失;3) 自训练策略的选择,例如使用置信度阈值过滤伪标签。这些设计共同保证了知识迁移的平滑性和有效性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GDO在旋转MNIST、颜色偏移MNIST、人像数据集和森林覆盖类型数据集上均优于现有基线方法。消融实验进一步验证了超参数λ的动态调整策略对性能的积极影响,证实了渐进域渗透在缓解领域偏差和增强模型泛化能力方面的优势。具体性能提升数据未知。
🎯 应用场景
GDO方法适用于需要逐步适应新环境或新任务的场景,例如机器人导航、自动驾驶、医疗诊断等。在这些场景中,模型需要不断地从已有的数据和经验中学习,并适应新的数据和环境变化。GDO提供了一种有效的知识迁移框架,可以帮助模型更快、更稳定地适应新的环境,提高模型的泛化能力和鲁棒性。
📄 摘要(原文)
In this paper, we propose a new method called Gradual Domain Osmosis, which aims to solve the problem of smooth knowledge migration from source domain to target domain in Gradual Domain Adaptation (GDA). Traditional Gradual Domain Adaptation methods mitigate domain bias by introducing intermediate domains and self-training strategies, but often face the challenges of inefficient knowledge migration or missing data in intermediate domains. In this paper, we design an optimisation framework based on the hyperparameter $λ$ by dynamically balancing the loss weights of the source and target domains, which enables the model to progressively adjust the strength of knowledge migration ($λ$ incrementing from 0 to 1) during the training process, thus achieving cross-domain generalisation more efficiently. Specifically, the method incorporates self-training to generate pseudo-labels and iteratively updates the model by minimising a weighted loss function to ensure stability and robustness during progressive adaptation in the intermediate domain. The experimental part validates the effectiveness of the method on rotated MNIST, colour-shifted MNIST, portrait dataset and forest cover type dataset, and the results show that it outperforms existing baseline methods. The paper further analyses the impact of the dynamic tuning strategy of the hyperparameter $λ$ on the performance through ablation experiments, confirming the advantages of progressive domain penetration in mitigating the domain bias and enhancing the model generalisation capability. The study provides a theoretical support and practical framework for asymptotic domain adaptation and expands its application potential in dynamic environments.