Laser: Efficient Language-Guided Segmentation in Neural Radiance Fields
作者: Xingyu Miao, Haoran Duan, Yang Bai, Tejal Shah, Jun Song, Yang Long, Rajiv Ranjan, Ling Shao
分类: cs.CV
发布日期: 2025-01-31
备注: Accepted by IEEE Transactions on Pattern Analysis and Machine Intelligence
DOI: 10.1109/TPAMI.2025.3535916
🔗 代码/项目: GITHUB
💡 一句话要点
提出Laser,通过CLIP特征蒸馏实现神经辐射场中高效的语言引导分割。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 神经辐射场 语言引导分割 CLIP特征蒸馏 自交叉训练 低秩注意力
📋 核心要点
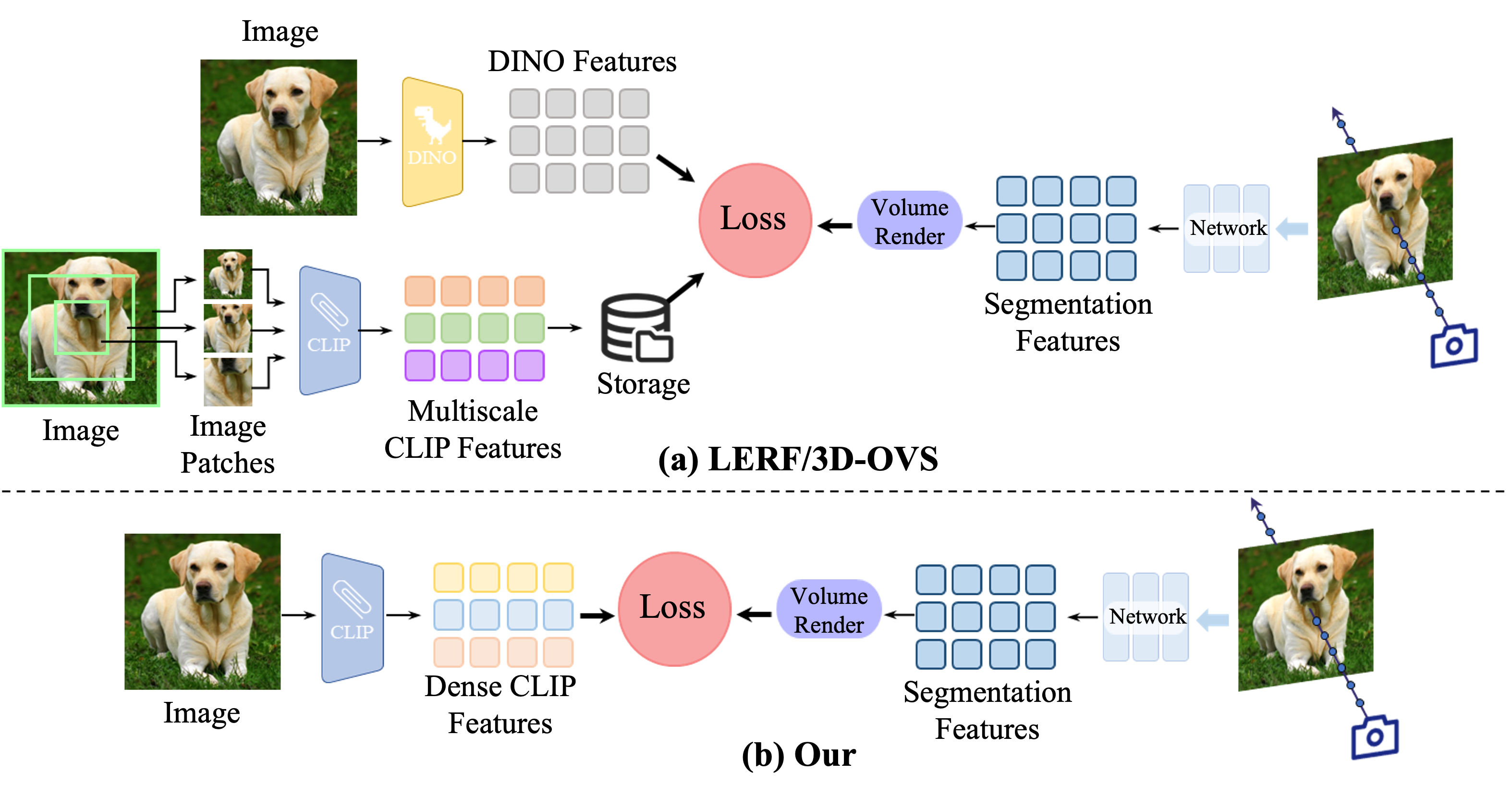
- 现有方法依赖多尺度CLIP特征,计算成本高,存储需求大,限制了3D场景语言引导分割的效率。
- 通过CLIP特征蒸馏,引入适配器模块和自交叉训练策略,有效提取密集CLIP特征,提升分割精度。
- 提出低秩瞬态查询注意力机制增强边缘分割,并采用标签体分类和文本增强策略提升分割一致性。
📝 摘要(中文)
本文提出了一种利用CLIP特征蒸馏的方法,通过语言引导实现高效的3D分割。与之前依赖多尺度CLIP特征、受限于处理速度和存储需求的方法不同,我们的方法旨在通过直接有效地蒸馏密集CLIP特征来简化工作流程,从而使用文本实现3D场景的精确分割。为此,我们引入了一个适配器模块,并通过自交叉训练策略缓解密集CLIP特征蒸馏过程中的噪声问题。此外,为了提高分割边缘的准确性,本文提出了一种低秩瞬态查询注意力机制。为了确保不同视角下相似颜色的分割一致性,我们通过标签体将分割任务转换为分类任务,从而显著提高了颜色相似区域的分割一致性。我们还提出了一种简化的文本增强策略,以缓解CLIP特征和文本之间对应关系的模糊性问题。大量的实验结果表明,我们的方法在训练速度和性能方面都超过了当前最先进的技术。
🔬 方法详解
问题定义:现有基于神经辐射场(NeRF)的语言引导分割方法,通常依赖于多尺度的CLIP特征,这导致了较高的计算复杂度和存储需求,限制了其在实际应用中的效率。此外,直接使用CLIP特征进行分割时,容易受到噪声的影响,导致分割精度下降。同时,在不同视角下,颜色相似区域的分割一致性难以保证。
核心思路:本文的核心思路是通过CLIP特征蒸馏,将CLIP的知识迁移到NeRF中,从而避免直接使用多尺度CLIP特征带来的计算负担。通过引入适配器模块和自交叉训练策略,可以有效地提取和提纯CLIP特征,降低噪声的影响。此外,通过将分割任务转化为标签体分类任务,可以提高不同视角下颜色相似区域的分割一致性。
技术框架:该方法主要包含以下几个模块:1) CLIP特征蒸馏模块,用于将CLIP的视觉和文本特征提取出来,并进行蒸馏;2) 适配器模块,用于将CLIP特征与NeRF的特征进行对齐;3) 自交叉训练模块,用于降低CLIP特征中的噪声;4) 低秩瞬态查询注意力模块,用于提高分割边缘的准确性;5) 标签体分类模块,用于提高分割一致性。整体流程是,首先使用CLIP提取图像和文本特征,然后通过适配器模块进行特征对齐,接着使用自交叉训练模块降低噪声,再利用低秩瞬态查询注意力模块优化边缘,最后通过标签体分类模块进行分割。
关键创新:该方法最重要的创新点在于CLIP特征的有效蒸馏和提纯。通过适配器模块和自交叉训练策略,可以有效地提取和提纯CLIP特征,从而避免了直接使用多尺度CLIP特征带来的计算负担和噪声影响。此外,低秩瞬态查询注意力机制和标签体分类模块也分别在边缘分割和分割一致性方面做出了贡献。
关键设计:适配器模块的具体结构未知,但其作用是将CLIP特征与NeRF特征进行对齐。自交叉训练策略的具体实现方式未知,但其目的是降低CLIP特征中的噪声。低秩瞬态查询注意力机制的具体实现方式未知,但其目的是提高分割边缘的准确性。标签体分类模块将分割任务转化为分类任务,通过预测每个体素的标签来提高分割一致性。文本增强策略的具体实现方式未知,但其目的是缓解CLIP特征和文本之间对应关系的模糊性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在训练速度和分割性能上均优于当前最先进的技术。具体的性能数据和对比基线未知,但论文强调了其在效率和精度上的显著提升。代码已开源,方便研究人员进行复现和进一步研究。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、虚拟现实/增强现实等领域。例如,机器人可以根据自然语言指令分割场景中的物体,从而执行更复杂的任务。在自动驾驶中,可以利用该方法分割道路、车辆和行人等,提高驾驶安全性。在VR/AR中,可以实现更逼真的场景交互。
📄 摘要(原文)
In this work, we propose a method that leverages CLIP feature distillation, achieving efficient 3D segmentation through language guidance. Unlike previous methods that rely on multi-scale CLIP features and are limited by processing speed and storage requirements, our approach aims to streamline the workflow by directly and effectively distilling dense CLIP features, thereby achieving precise segmentation of 3D scenes using text. To achieve this, we introduce an adapter module and mitigate the noise issue in the dense CLIP feature distillation process through a self-cross-training strategy. Moreover, to enhance the accuracy of segmentation edges, this work presents a low-rank transient query attention mechanism. To ensure the consistency of segmentation for similar colors under different viewpoints, we convert the segmentation task into a classification task through label volume, which significantly improves the consistency of segmentation in color-similar areas. We also propose a simplified text augmentation strategy to alleviate the issue of ambiguity in the correspondence between CLIP features and text. Extensive experimental results show that our method surpasses current state-of-the-art technologies in both training speed and performance. Our code is available on: https://github.com/xingy038/Laser.git.