Improving vision-language alignment with graph spiking hybrid Networks
作者: Siyu Zhang, Wenzhe Liu, Yeming Chen, Yiming Wu, Heming Zheng, Cheng Cheng
分类: cs.CV, cs.AI
发布日期: 2025-01-31 (更新: 2025-03-02)
💡 一句话要点
提出图脉冲混合网络GSHN,提升视觉-语言对齐效果,增强语义表征能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 视觉-语言对齐 图神经网络 脉冲神经网络 全景分割 对比学习
📋 核心要点
- 现有视觉-语言对齐方法难以充分捕捉对象间细微的上下文关系,导致语义表示不足。
- 提出图脉冲混合网络GSHN,结合SNN和GAT优势,编码离散和连续变量,捕捉局部和全局特征。
- 通过对比学习增强嵌入表示,并设计脉冲文本学习STL预训练方法,提升模型性能。
📝 摘要(中文)
为了弥合视觉和语言(VL)之间的语义鸿沟,需要开发一种良好的对齐策略,包括处理语义多样性、视觉信息的抽象表示和模型的泛化能力。目前的方法使用基于检测器的边界框或具有规则分割的图像块来表示视觉语义,但不足以充分捕捉对象之间的细微上下文关系。本文提出了一种综合的视觉语义表示模块,利用全景分割生成连贯的细粒度语义特征。此外,提出了一种新的图脉冲混合网络(GSHN),它集成了脉冲神经网络(SNN)和图注意力网络(GAT)的互补优势来编码视觉语义信息。该模型不仅编码实例的离散和连续潜在变量,而且能够巧妙地捕捉局部和全局上下文特征,从而显著增强语义表示的丰富性和多样性。利用SNN中固有的时空特性,采用对比学习(CL)来增强基于相似性的嵌入表示。通过构建正负样本对,减轻了模型的计算开销,并丰富了有意义的视觉表示。设计了一种创新的预训练方法,即脉冲文本学习(STL),它使用文本特征来提高离散语义的编码能力。实验表明,所提出的GSHN在多个VL下游任务上表现出良好的结果。
🔬 方法详解
问题定义:论文旨在解决视觉-语言对齐中,现有方法无法充分捕捉视觉对象之间细微上下文关系的问题。现有方法主要依赖于基于检测器的边界框或规则分割的图像块,这些方法忽略了对象之间的复杂关联,导致视觉语义表示不够丰富和准确,进而影响下游任务的性能。
核心思路:论文的核心思路是利用全景分割生成细粒度的视觉语义特征,并结合脉冲神经网络(SNN)和图注意力网络(GAT)的优势,构建一个能够有效编码视觉语义信息的混合网络。通过SNN处理时空信息,GAT捕捉全局上下文关系,从而提升语义表示的丰富性和多样性。
技术框架:GSHN的整体框架包含以下几个主要模块:1) 全景分割模块:用于生成细粒度的视觉语义特征。2) 图脉冲混合网络(GSHN):由SNN和GAT组成,用于编码视觉语义信息,捕捉局部和全局上下文特征。3) 对比学习模块:利用SNN的时空特性,通过对比学习增强嵌入表示。4) 脉冲文本学习(STL)预训练模块:利用文本特征提高离散语义的编码能力。整个流程是先通过全景分割提取视觉特征,然后输入GSHN进行编码,再通过对比学习进行优化,最后使用STL进行预训练。
关键创新:论文的关键创新在于提出了图脉冲混合网络(GSHN),它将SNN和GAT结合起来,充分利用了SNN处理时空信息和GAT捕捉全局上下文关系的优势。与现有方法相比,GSHN能够更有效地编码视觉语义信息,提升语义表示的丰富性和多样性。此外,提出的脉冲文本学习(STL)预训练方法也是一个创新点,它利用文本特征来提高离散语义的编码能力。
关键设计:GSHN的关键设计包括:1) SNN的结构和参数设置,例如神经元的类型、连接方式等。2) GAT的结构和注意力机制的设计,例如注意力头的数量、注意力权重的计算方式等。3) 对比学习的损失函数设计,例如正负样本的选择策略、损失函数的权重等。4) STL预训练方法的具体实现,例如文本特征的提取方式、预训练的目标函数等。这些设计细节直接影响着GSHN的性能。
🖼️ 关键图片
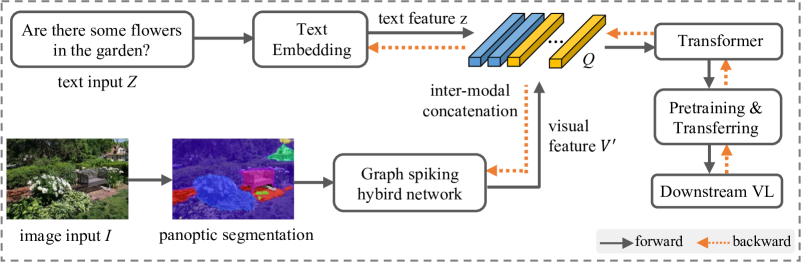
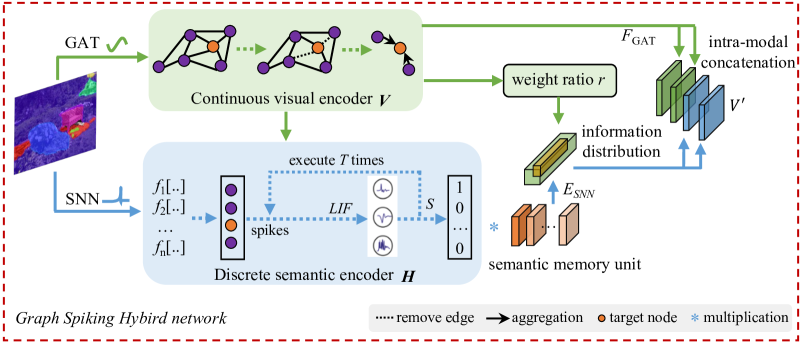

📊 实验亮点
实验结果表明,所提出的GSHN在多个视觉-语言下游任务上取得了显著的性能提升。具体的性能数据和对比基线在论文中给出,证明了GSHN在视觉-语言对齐方面的有效性。STL预训练方法也进一步提升了模型的性能。
🎯 应用场景
该研究成果可应用于多种视觉-语言任务,如图像描述、视觉问答、跨模态检索等。通过提升视觉语义表示的质量,可以提高这些任务的准确性和效率。未来,该方法有望应用于机器人导航、智能监控等领域,实现更智能的人机交互。
📄 摘要(原文)
To bridge the semantic gap between vision and language (VL), it is necessary to develop a good alignment strategy, which includes handling semantic diversity, abstract representation of visual information, and generalization ability of models. Recent works use detector-based bounding boxes or patches with regular partitions to represent visual semantics. While current paradigms have made strides, they are still insufficient for fully capturing the nuanced contextual relations among various objects. This paper proposes a comprehensive visual semantic representation module, necessitating the utilization of panoptic segmentation to generate coherent fine-grained semantic features. Furthermore, we propose a novel Graph Spiking Hybrid Network (GSHN) that integrates the complementary advantages of Spiking Neural Networks (SNNs) and Graph Attention Networks (GATs) to encode visual semantic information. Intriguingly, the model not only encodes the discrete and continuous latent variables of instances but also adeptly captures both local and global contextual features, thereby significantly enhancing the richness and diversity of semantic representations. Leveraging the spatiotemporal properties inherent in SNNs, we employ contrastive learning (CL) to enhance the similarity-based representation of embeddings. This strategy alleviates the computational overhead of the model and enriches meaningful visual representations by constructing positive and negative sample pairs. We design an innovative pre-training method, Spiked Text Learning (STL), which uses text features to improve the encoding ability of discrete semantics. Experiments show that the proposed GSHN exhibits promising results on multiple VL downstream tasks.