Text-to-CAD Generation Through Infusing Visual Feedback in Large Language Models
作者: Ruiyu Wang, Yu Yuan, Shizhao Sun, Jiang Bian
分类: cs.CV, cs.LG
发布日期: 2025-01-31 (更新: 2025-06-05)
备注: ICML 2025 camera ready
💡 一句话要点
CADFusion:通过视觉反馈增强大语言模型,实现文本到CAD模型的生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到CAD 大语言模型 视觉反馈 多模态学习 参数化建模
📋 核心要点
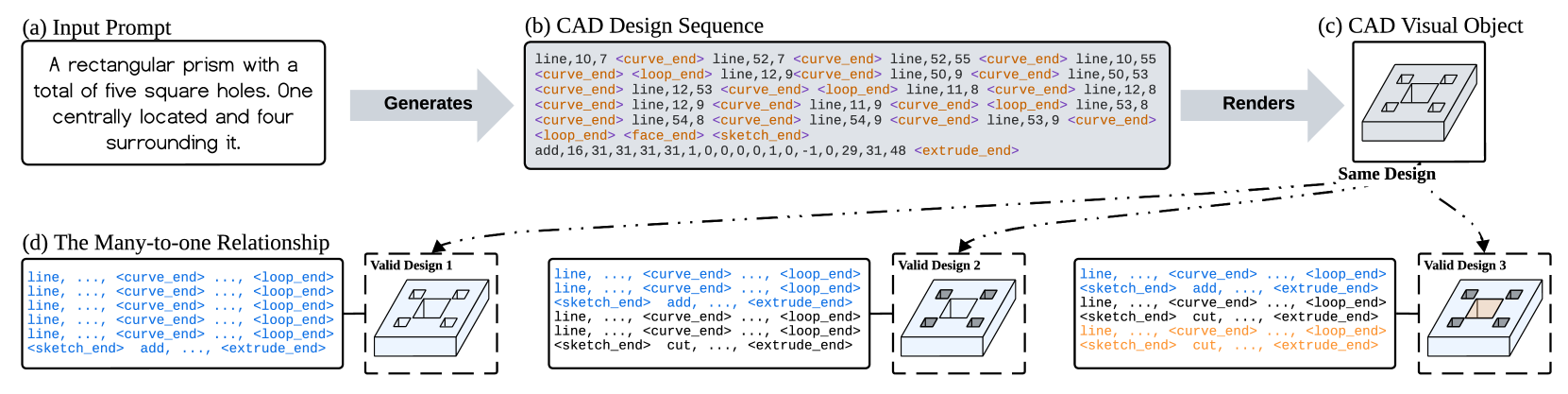
- 现有文本到CAD方法依赖于参数序列监督,忽略了CAD模型的多模态特性和视觉信息的重要性。
- CADFusion框架通过序列学习和视觉反馈交替训练,使LLM既能生成连贯的参数序列,又能理解视觉对象的感知和评估。
- 实验结果表明,CADFusion在文本到CAD生成任务中取得了显著的性能提升,验证了视觉反馈的有效性。
📝 摘要(中文)
创建计算机辅助设计(CAD)模型需要大量的专业知识和努力。文本到CAD的转换,即将文本描述转换为CAD参数序列,对于简化这一过程至关重要。最近的研究利用真实参数序列(称为序列信号)作为监督来实现这一目标。然而,CAD模型本质上是多模态的,包括参数序列和相应的渲染视觉对象。此外,从参数序列到视觉对象的渲染过程是多对一的。因此,序列和视觉信号对于有效的训练都至关重要。本文提出了CADFusion,一个使用大型语言模型(LLM)作为主干的框架,并在两个训练阶段之间交替进行:序列学习(SL)阶段和视觉反馈(VF)阶段。在SL阶段,我们使用真实参数序列训练LLM,使其能够生成逻辑上连贯的参数序列。在VF阶段,我们奖励渲染成视觉上更优对象的参数序列,并惩罚那些没有渲染成视觉上更优对象的参数序列,从而使LLM能够学习如何感知和评估渲染的视觉对象。这两个阶段在整个训练过程中交替进行,确保平衡学习并保留两种信号的优势。实验表明,CADFusion在质量和数量上都显著提高了性能。
🔬 方法详解
问题定义:现有文本到CAD生成方法主要依赖于参数序列的监督学习,忽略了CAD模型固有的多模态特性,特别是渲染后的视觉信息。由于从参数序列到视觉对象的渲染是多对一的映射关系,仅使用参数序列作为监督信号会丢失大量有价值的信息,导致生成的CAD模型在视觉上可能不理想。因此,如何有效地利用视觉信息来指导文本到CAD的生成是一个关键问题。
核心思路:CADFusion的核心思路是通过引入视觉反馈机制,让LLM学习如何感知和评估渲染后的视觉对象。具体来说,CADFusion交替进行序列学习(SL)和视觉反馈(VF)两个阶段的训练。SL阶段利用参数序列进行监督学习,保证生成参数序列的逻辑连贯性;VF阶段则根据渲染后的视觉对象质量对参数序列进行奖励或惩罚,引导LLM生成视觉上更优的CAD模型。
技术框架:CADFusion框架以LLM作为主干网络,包含序列学习(SL)和视觉反馈(VF)两个主要阶段。在SL阶段,LLM接收文本描述作为输入,并生成参数序列。生成的参数序列与ground truth参数序列进行比较,计算损失并更新LLM的参数。在VF阶段,生成的参数序列被渲染成视觉对象,然后使用一个视觉评估器(例如CLIP)来评估渲染对象的质量。根据评估结果,对LLM生成的参数序列进行奖励或惩罚,从而引导LLM生成视觉上更优的CAD模型。这两个阶段交替进行,直至模型收敛。
关键创新:CADFusion的关键创新在于引入了视觉反馈机制,将视觉信息融入到文本到CAD的生成过程中。与以往仅依赖参数序列监督的方法不同,CADFusion通过奖励和惩罚机制,使LLM能够学习如何感知和评估渲染后的视觉对象,从而生成视觉上更符合要求的CAD模型。这种视觉反馈机制弥补了参数序列监督的不足,提高了生成CAD模型的质量。
关键设计:在VF阶段,视觉评估器的选择至关重要。论文中可能使用了CLIP等预训练的视觉语言模型来评估渲染对象的质量。奖励和惩罚的设计也需要仔细考虑,例如可以使用强化学习中的策略梯度方法来更新LLM的参数。此外,SL和VF阶段的交替频率也需要进行调整,以平衡序列学习和视觉反馈的效果。
🖼️ 关键图片


📊 实验亮点
CADFusion通过引入视觉反馈机制,显著提高了文本到CAD生成的性能。实验结果表明,CADFusion在多个指标上优于现有方法,尤其是在视觉质量方面有显著提升。具体的性能数据和对比基线需要在论文中查找,但总体而言,CADFusion的性能提升证明了视觉反馈在文本到CAD生成中的重要性。
🎯 应用场景
CADFusion具有广泛的应用前景,例如自动化产品设计、定制化零件生成、建筑设计辅助等。它可以降低CAD建模的门槛,使非专业人士也能轻松创建复杂的3D模型。此外,该技术还可以应用于游戏开发、虚拟现实等领域,加速3D内容的生成。
📄 摘要(原文)
Creating Computer-Aided Design (CAD) models requires significant expertise and effort. Text-to-CAD, which converts textual descriptions into CAD parametric sequences, is crucial in streamlining this process. Recent studies have utilized ground-truth parametric sequences, known as sequential signals, as supervision to achieve this goal. However, CAD models are inherently multimodal, comprising parametric sequences and corresponding rendered visual objects. Besides,the rendering process from parametric sequences to visual objects is many-to-one. Therefore, both sequential and visual signals are critical for effective training. In this work, we introduce CADFusion, a framework that uses Large Language Models (LLMs) as the backbone and alternates between two training stages: the sequential learning (SL) stage and the visual feedback (VF) stage. In the SL stage, we train LLMs using ground-truth parametric sequences, enabling the generation of logically coherent parametric sequences. In the VF stage, we reward parametric sequences that render into visually preferred objects and penalize those that do not, allowing LLMs to learn how rendered visual objects are perceived and evaluated. These two stages alternate throughout the training, ensuring balanced learning and preserving benefits of both signals. Experiments demonstrate that CADFusion significantly improves performance, both qualitatively and quantitatively.