UP-VLA: A Unified Understanding and Prediction Model for Embodied Agent
作者: Jianke Zhang, Yanjiang Guo, Yucheng Hu, Xiaoyu Chen, Xiang Zhu, Jianyu Chen
分类: cs.CV, cs.AI
发布日期: 2025-01-31 (更新: 2025-06-26)
备注: Accepted to ICML2025
💡 一句话要点
提出UP-VLA模型,通过统一理解与预测目标提升具身智能体的性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 视觉-语言-动作模型 多模态学习 未来预测 机器人操作
📋 核心要点
- 现有VLA模型依赖的VLM侧重高层语义,忽略了具身智能体所需的低层空间信息和物理动态。
- UP-VLA模型通过统一多模态理解和未来预测目标,同时提升模型的高层语义和低层空间理解能力。
- 实验表明,UP-VLA在Calvin ABC-D基准测试中提升33%,并在真实操作任务中表现出更高的成功率。
📝 摘要(中文)
近年来,视觉-语言-动作(VLA)模型利用预训练的视觉-语言模型(VLM)来提高泛化能力。VLM通常在视觉-语言理解任务上进行预训练,提供了丰富的语义知识和推理能力。然而,先前的研究表明,VLM通常侧重于高层语义内容,而忽略了低层特征,限制了它们捕获详细空间信息和理解物理动态的能力。这些对于具身控制任务至关重要的方面在现有的预训练范式中仍未得到充分探索。本文研究了VLA的训练范式,并提出了UP-VLA,一个统一的VLA模型,它通过多模态理解和未来预测目标进行训练,从而增强了高层语义理解和低层空间理解。实验结果表明,与之前的最先进方法相比,UP-VLA在Calvin ABC-D基准测试中实现了33%的改进。此外,UP-VLA在现实世界的操作任务中表现出更高的成功率,尤其是在那些需要精确空间信息的任务中。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型依赖于预训练的视觉-语言模型(VLM)。这些VLM虽然擅长高层语义理解,但在捕获具身智能体所需的低层空间信息和理解物理动态方面存在不足。这限制了它们在需要精细操作的任务中的表现。因此,需要一种能够同时理解高层语义和低层空间信息的VLA模型。
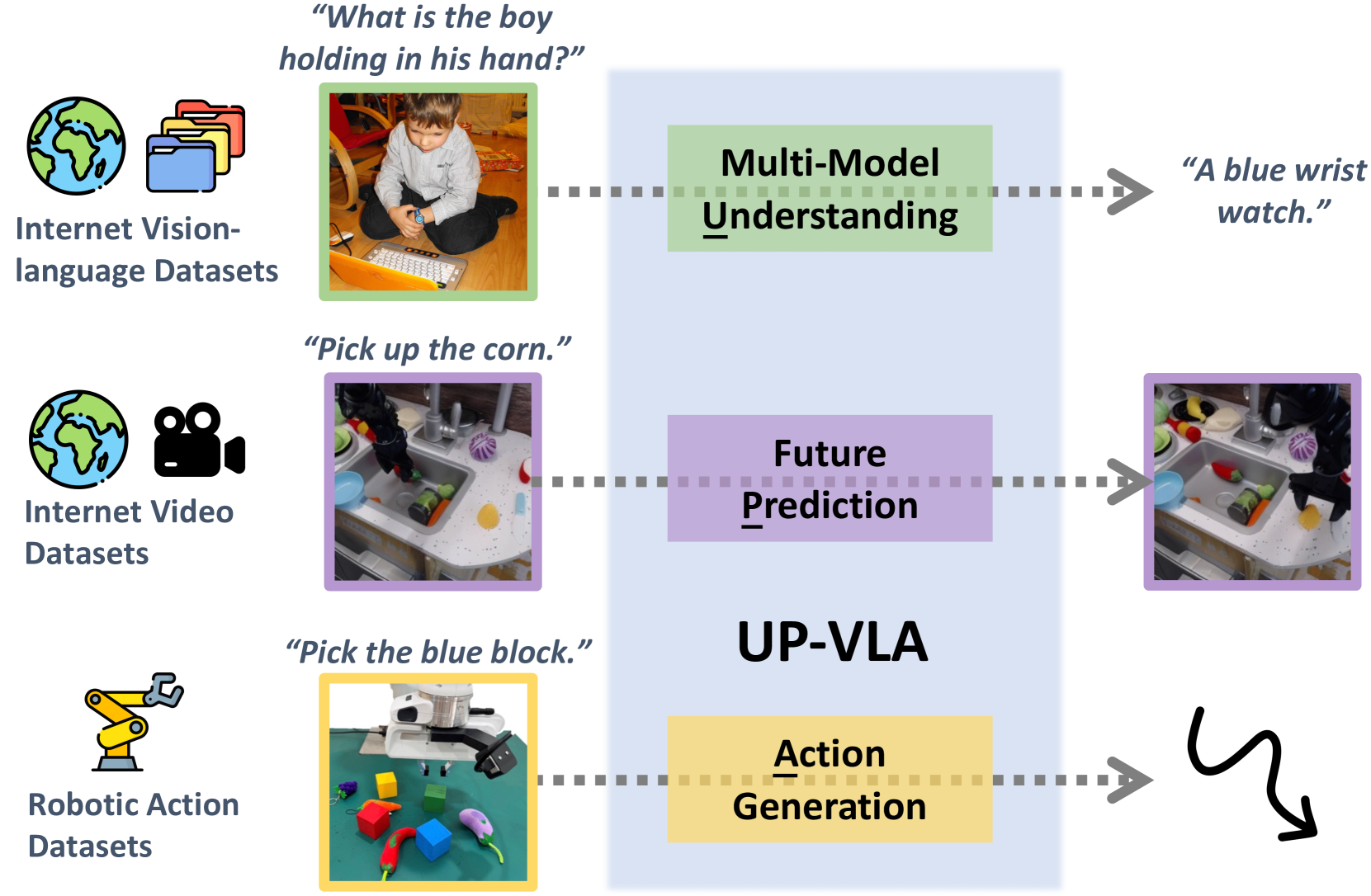
核心思路:UP-VLA的核心思路是通过统一多模态理解和未来预测这两个目标来训练VLA模型。多模态理解目标使模型能够学习高层语义信息,而未来预测目标则促使模型学习低层空间信息和物理动态。通过同时优化这两个目标,UP-VLA能够更好地理解环境并做出更准确的动作。
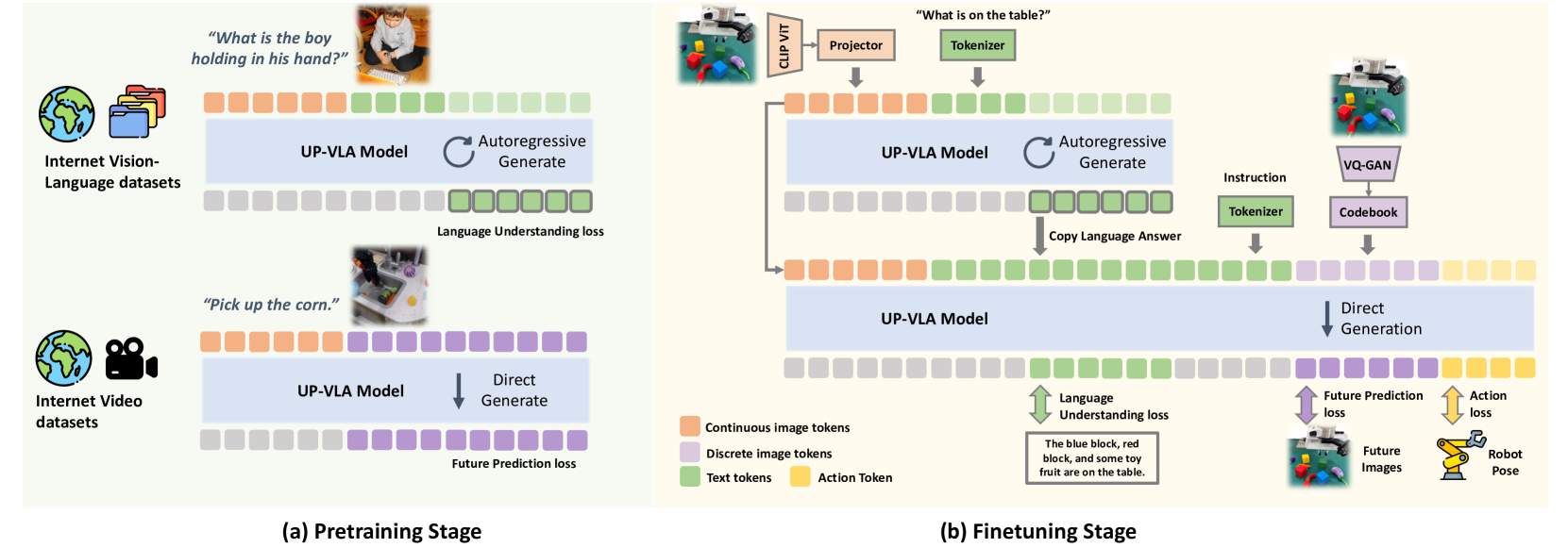
技术框架:UP-VLA的整体架构包含视觉编码器、语言编码器、动作预测模块和未来状态预测模块。视觉编码器将输入的图像转换为视觉特征,语言编码器将输入的指令转换为语言特征。动作预测模块根据视觉特征和语言特征预测下一步的动作。未来状态预测模块根据视觉特征、语言特征和预测的动作预测未来的环境状态。整个模型通过多模态理解损失和未来预测损失进行联合训练。
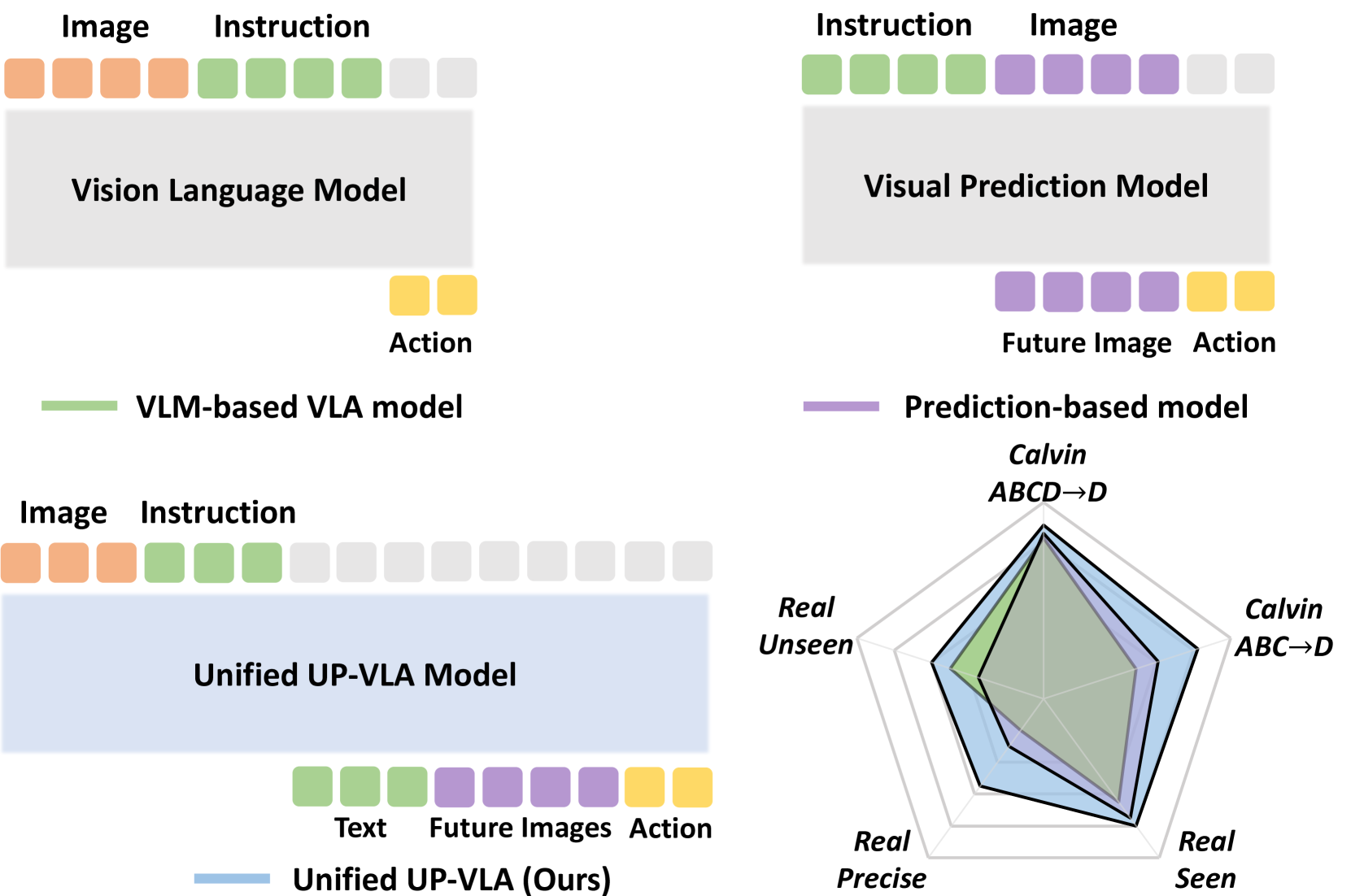
关键创新:UP-VLA的关键创新在于其统一的训练范式,它同时考虑了多模态理解和未来预测。与以往只关注高层语义理解的VLA模型不同,UP-VLA通过未来预测目标显式地学习低层空间信息和物理动态。这种统一的训练范式使得UP-VLA能够更好地理解环境并做出更准确的动作。
关键设计:UP-VLA的关键设计包括:1) 使用Transformer架构作为视觉和语言编码器,以捕获长程依赖关系;2) 使用对比学习损失来增强多模态特征的对齐;3) 使用像素级别的未来状态预测损失来促使模型学习低层空间信息;4) 通过调整多模态理解损失和未来预测损失的权重来平衡高层语义理解和低层空间理解。
🖼️ 关键图片
📊 实验亮点
UP-VLA在Calvin ABC-D基准测试中取得了显著的性能提升,相比之前的SOTA方法提升了33%。此外,在真实世界的操作任务中,UP-VLA也表现出更高的成功率,尤其是在需要精确空间信息的任务中。这些实验结果表明,UP-VLA能够有效地学习高层语义和低层空间信息,从而提升具身智能体的性能。
🎯 应用场景
UP-VLA模型具有广泛的应用前景,例如:机器人操作、自动驾驶、虚拟助手等。它可以应用于需要精确操作和环境理解的各种任务,例如:装配、导航、物体抓取等。该研究有助于提升机器人在复杂环境中的自主性和适应性,推动机器人技术的发展。
📄 摘要(原文)
Recent advancements in Vision-Language-Action (VLA) models have leveraged pre-trained Vision-Language Models (VLMs) to improve the generalization capabilities. VLMs, typically pre-trained on vision-language understanding tasks, provide rich semantic knowledge and reasoning abilities. However, prior research has shown that VLMs often focus on high-level semantic content and neglect low-level features, limiting their ability to capture detailed spatial information and understand physical dynamics. These aspects, which are crucial for embodied control tasks, remain underexplored in existing pre-training paradigms. In this paper, we investigate the training paradigm for VLAs, and introduce \textbf{UP-VLA}, a \textbf{U}nified VLA model training with both multi-modal \textbf{U}nderstanding and future \textbf{P}rediction objectives, enhancing both high-level semantic comprehension and low-level spatial understanding. Experimental results show that UP-VLA achieves a 33% improvement on the Calvin ABC-D benchmark compared to the previous state-of-the-art method. Additionally, UP-VLA demonstrates improved success rates in real-world manipulation tasks, particularly those requiring precise spatial information.