Tuning Vision Foundation Model via Test-Time Prompt-Guided Training for VFSS Segmentations
作者: Chengxi Zeng, David Smithard, Alberto M Gambaruto, Tilo Burghardt
分类: cs.CV
发布日期: 2025-01-30
💡 一句话要点
提出测试时提示引导训练方法,提升视觉基础模型在VFSS分割任务上的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉基础模型 测试时训练 点提示 半自监督学习 医学图像分割 VFSS数据集 实例分割
📋 核心要点
- 现有视觉基础模型在分割任务中泛化性强,但与特定任务模型仍有差距,且下游数据全标注成本高昂。
- 提出测试时提示引导训练方法,利用点提示和数据增强进行半自监督学习,提升模型性能。
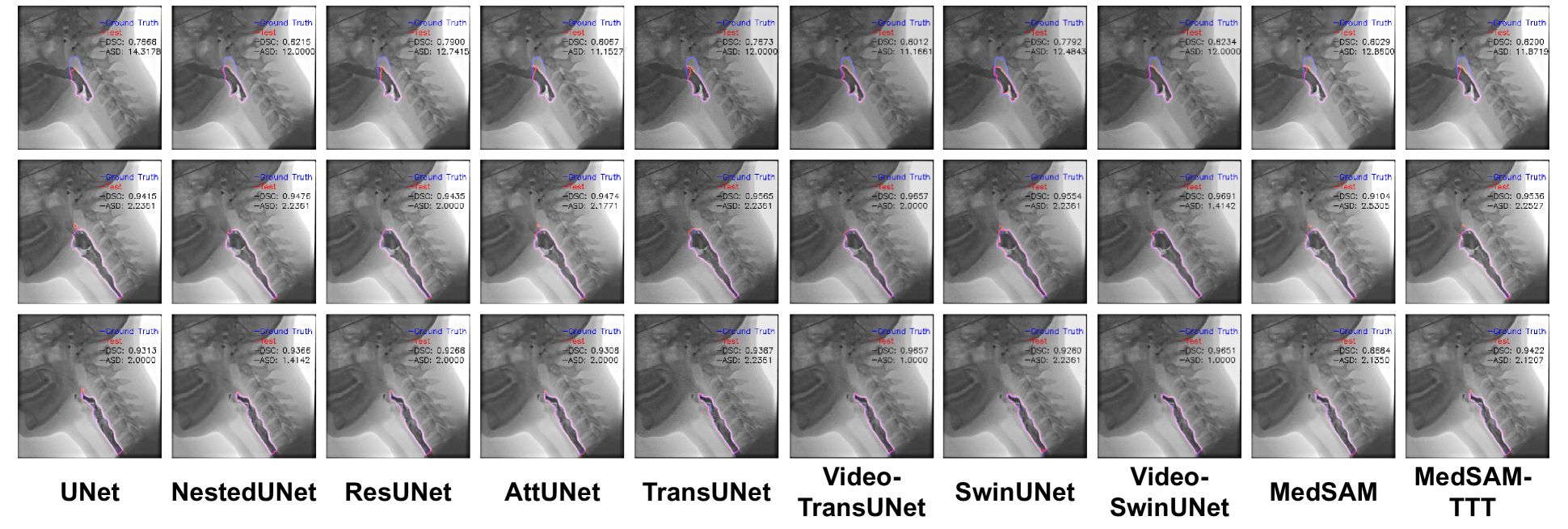
- 在VFSS-5k数据集上进行实例分割实验,单模型在12个解剖结构上Dice系数达到0.868。
📝 摘要(中文)
视觉基础模型在通用和专业图像的分割任务中表现出卓越的泛化能力。然而,基础模型与特定任务的专业模型之间仍然存在性能差距。通常需要在下游数据集上微调基础模型以弥合这一差距。不幸的是,获取下游数据集的完整标注ground truth既具有挑战性又成本高昂。为了解决这个限制,我们提出了一种新颖的测试时训练范式,该范式增强了基础模型在下游数据集上的性能,而无需完整标注。具体来说,我们的方法采用简单的点提示来指导测试时半自监督训练任务。模型通过解决各种增强的点提示的模糊性来学习。这种方法直接解决了医学成像领域的挑战,在该领域中,获取注释既耗时又昂贵。我们在新的Videofluoroscopy数据集(VFSS-5k)上进行了广泛的实例分割任务实验,使用单个模型在12个解剖结构上实现了0.868的平均Dice系数。
🔬 方法详解
问题定义:论文旨在解决视觉基础模型在特定任务(如医学图像分割)中,因缺乏充分标注数据而导致的性能瓶颈问题。现有方法通常依赖于在下游数据集上进行微调,但获取高质量、全标注的医学图像数据成本高昂且耗时,限制了基础模型在实际应用中的潜力。
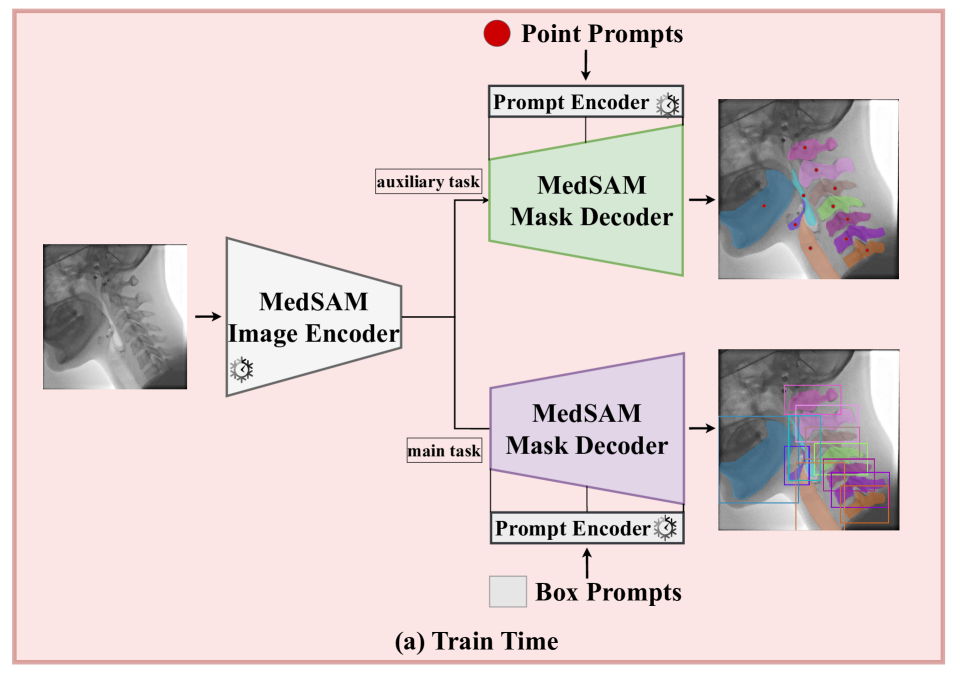
核心思路:论文的核心思路是利用测试时训练(Test-Time Training, TTT)范式,结合简单的点提示(Point Prompts)和半自监督学习,在没有完整标注的情况下提升模型性能。通过在测试阶段对模型进行适应性调整,使其更好地适应特定任务的数据分布。
技术框架:该方法主要包含以下几个阶段:1) 初始化:使用预训练的视觉基础模型作为初始模型。2) 点提示生成:在测试图像上随机或根据先验知识生成少量点提示。3) 数据增强:对测试图像进行各种数据增强操作,生成多个增强后的图像。4) 半自监督训练:利用点提示和增强后的图像,构建半自监督学习任务,例如,通过最小化点提示区域内像素的一致性损失来训练模型。5) 推理:使用训练后的模型进行分割推理。
关键创新:该方法的核心创新在于将测试时训练与点提示相结合,实现了一种无需完整标注的半自监督学习框架。与传统的微调方法相比,该方法避免了对大量标注数据的依赖,降低了标注成本。同时,测试时训练能够使模型更好地适应特定任务的数据分布,提升泛化性能。
关键设计:关键设计包括:1) 点提示的选择策略:论文可能探讨了不同点提示生成策略对模型性能的影响。2) 数据增强策略:论文可能采用了多种数据增强方法,例如旋转、缩放、平移等,以增加数据的多样性。3) 损失函数的设计:论文可能设计了特定的损失函数,例如一致性损失或交叉熵损失,以指导模型的训练。4) 训练迭代次数和学习率等超参数的设置。
🖼️ 关键图片
📊 实验亮点
该论文在VFSS-5k数据集上进行了实验,结果表明,使用该方法训练的单个模型在12个解剖结构上实现了0.868的平均Dice系数。这一结果表明,该方法能够有效地提升视觉基础模型在特定任务上的性能,并且具有良好的泛化能力。具体的性能提升幅度需要参考原文与基线方法的对比。
🎯 应用场景
该研究成果可广泛应用于医学图像分析领域,例如病灶分割、器官分割等。通过减少对大量标注数据的依赖,降低了医学图像分析的成本,加速了相关技术的落地应用。此外,该方法也可推广到其他领域,例如遥感图像分析、工业缺陷检测等,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Vision foundation models have demonstrated exceptional generalization capabilities in segmentation tasks for both generic and specialized images. However, a performance gap persists between foundation models and task-specific, specialized models. Fine-tuning foundation models on downstream datasets is often necessary to bridge this gap. Unfortunately, obtaining fully annotated ground truth for downstream datasets is both challenging and costly. To address this limitation, we propose a novel test-time training paradigm that enhances the performance of foundation models on downstream datasets without requiring full annotations. Specifically, our method employs simple point prompts to guide a test-time semi-self-supervised training task. The model learns by resolving the ambiguity of the point prompt through various augmentations. This approach directly tackles challenges in the medical imaging field, where acquiring annotations is both time-intensive and expensive. We conducted extensive experiments on our new Videofluoroscopy dataset (VFSS-5k) for the instance segmentation task, achieving an average Dice coefficient of 0.868 across 12 anatomies with a single model.