Free-T2M: Robust Text-to-Motion Generation for Humanoid Robots via Frequency-Domain
作者: Wenshuo Chen, Haozhe Jia, Songning Lai, Lei Wang, Yuqi Lin, Hongru Xiao, Lijie Hu, Yutao Yue
分类: cs.CV
发布日期: 2025-01-30 (更新: 2025-11-10)
💡 一句话要点
Free-T2M:通过频域增强,实现人形机器人鲁棒的文本到动作生成
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱四:生成式动作 (Generative Motion)
关键词: 文本到动作生成 人形机器人 频域分析 扩散模型 自然语言控制 运动合成 人机交互
📋 核心要点
- 现有文本到动作生成方法难以生成语义正确且稳定的机器人动作,限制了其在实际场景中的应用。
- Free-T2M从频域角度出发,将动作生成分解为语义规划(低频)和精细执行(高频)两个阶段,并分别进行优化。
- 实验表明,Free-T2M显著提升了动作质量和语义正确性,在StableMoFusion基线上将FID指标从0.152降低至0.060。
📝 摘要(中文)
本文旨在解决人形机器人从自然语言指令生成复杂、物理上连贯的动作这一难题。现有基于扩散模型的方法常生成语义错误或不稳定的动作,限制了其在实际机器人中的应用。本文从频域角度重新审视文本到动作(T2M)问题,揭示生成过程类似于分层控制范式。研究识别出两个关键阶段:低频分量建立全局运动轨迹的语义规划阶段,以及高频细节优化运动的精细执行阶段。为此,本文提出了频域增强的文本到动作框架(Free-T2M),该框架结合了特定阶段的频域一致性对齐。设计了一种频域时序自适应模块,以调节不同频段的对齐效果。这些设计增强了基础语义计划的鲁棒性,并提高了详细执行的准确性。大量实验表明,该方法显著提高了运动质量和语义正确性。值得注意的是,当应用于StableMoFusion基线时,Free-T2M将FID从0.152降低到0.060,在扩散架构中建立了新的最先进水平。这些发现强调了频域洞察力对于生成鲁棒和可靠运动的关键作用,为更直观的机器人自然语言控制铺平了道路。
🔬 方法详解
问题定义:论文旨在解决人形机器人文本到动作生成任务中,现有方法生成的动作在语义上不准确或物理上不稳定的问题。现有方法难以保证生成动作的语义一致性和物理可行性,限制了其在真实机器人控制中的应用。
核心思路:论文的核心思路是将文本到动作的生成过程视为一个分层控制过程,并将其映射到频域。低频分量对应于全局的语义规划,高频分量对应于精细的动作执行。通过在频域中对不同频率分量进行针对性的处理,可以提高生成动作的鲁棒性和准确性。
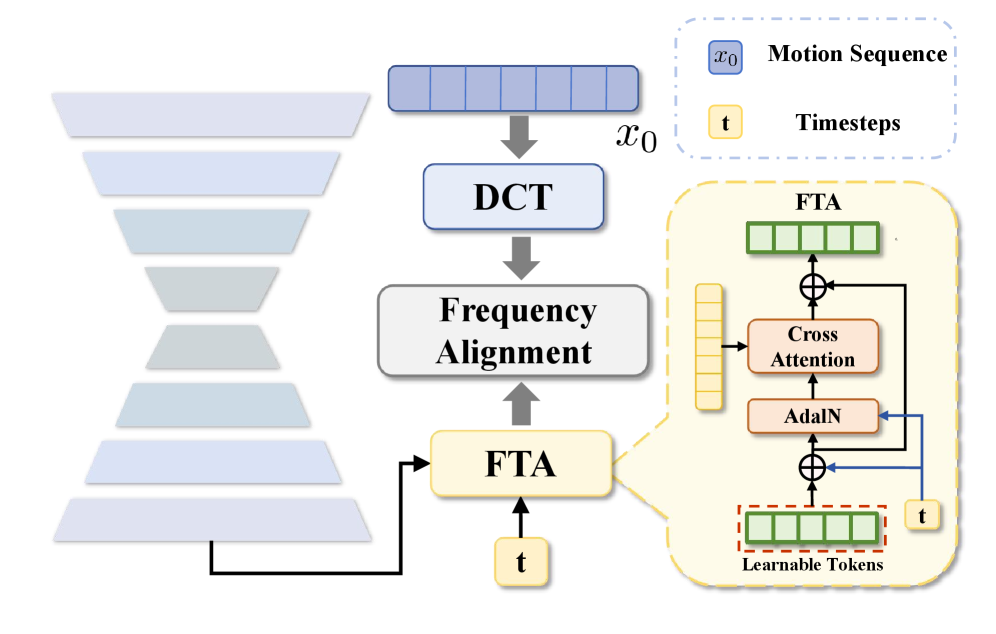
技术框架:Free-T2M框架主要包含以下几个模块:1) 文本编码器:将输入的自然语言指令编码为语义向量。2) 运动解码器:基于语义向量生成运动序列。3) 频域分析模块:将运动序列转换到频域,提取不同频率分量。4) 频域一致性对齐模块:对不同频率分量进行一致性约束,保证语义规划和精细执行的一致性。5) 频域时序自适应模块:根据时间步动态调整不同频率分量的对齐效果。
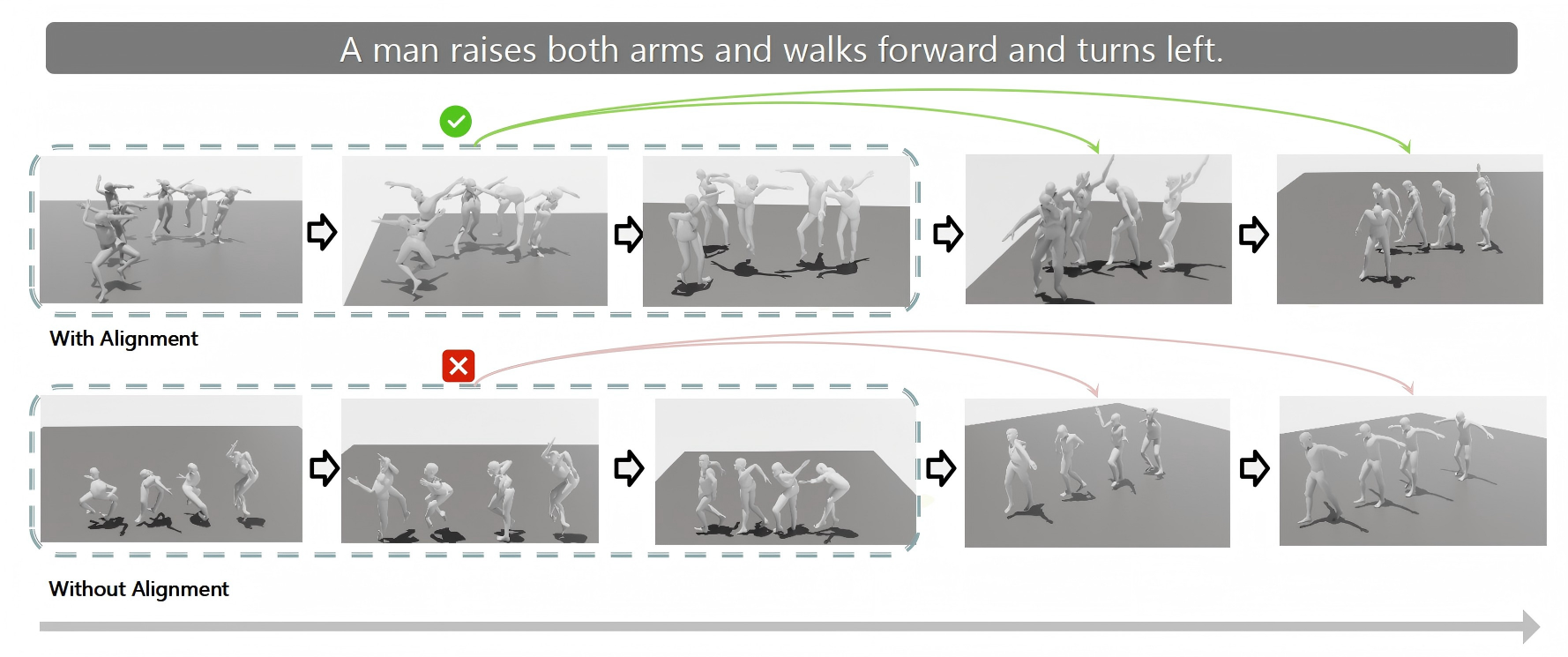
关键创新:论文最重要的技术创新点在于从频域角度重新审视文本到动作生成问题,并提出了频域一致性对齐方法。与现有方法直接在时域进行生成不同,Free-T2M在频域中对不同频率分量进行约束,从而更好地控制生成动作的全局结构和局部细节。
关键设计:频域时序自适应模块是关键设计之一,它允许模型根据时间步动态调整不同频率分量的对齐效果。具体来说,该模块使用一个可学习的权重向量来控制不同频率分量的贡献。此外,论文还设计了特定的损失函数来约束频域一致性,例如,最小化生成动作和目标动作在低频分量上的差异。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Free-T2M显著提高了文本到动作生成的质量和语义正确性。在HumanML3D数据集上,Free-T2M在多个指标上取得了state-of-the-art的结果。特别是在StableMoFusion基线上,Free-T2M将FID指标从0.152降低到0.060,证明了该方法在生成高质量动作方面的优越性。消融实验也验证了频域一致性对齐和频域时序自适应模块的有效性。
🎯 应用场景
该研究成果可应用于人形机器人的自然语言控制,使其能够根据人类指令生成各种复杂的动作,例如行走、跳跃、搬运物品等。这对于提升人机交互的自然性和效率,以及拓展机器人在服务、娱乐、医疗等领域的应用具有重要意义。未来,该技术有望应用于更广泛的机器人类型,并与其他感知和决策模块相结合,实现更智能化的机器人系统。
📄 摘要(原文)
Enabling humanoid robots to synthesize complex, physically coherent motions from natural language commands is a cornerstone of autonomous robotics and human-robot interaction. While diffusion models have shown promise in this text-to-motion (T2M) task, they often generate semantically flawed or unstable motions, limiting their applicability to real-world robots. This paper reframes the T2M problem from a frequency-domain perspective, revealing that the generative process mirrors a hierarchical control paradigm. We identify two critical phases: a semantic planning stage, where low-frequency components establish the global motion trajectory, and a fine-grained execution stage, where high-frequency details refine the movement. To address the distinct challenges of each phase, we introduce Frequency enhanced text-to-motion (Free-T2M), a framework incorporating stage-specific frequency-domain consistency alignment. We design a frequency-domain temporal-adaptive module to modulate the alignment effects of different frequency bands. These designs enforce robustness in the foundational semantic plan and enhance the accuracy of detailed execution. Extensive experiments show our method dramatically improves motion quality and semantic correctness. Notably, when applied to the StableMoFusion baseline, Free-T2M reduces the FID from 0.152 to 0.060, establishing a new state-of-the-art within diffusion architectures. These findings underscore the critical role of frequency-domain insights for generating robust and reliable motions, paving the way for more intuitive natural language control of robots.