Multimodal Large Language Models for Image, Text, and Speech Data Augmentation: A Survey
作者: Ranjan Sapkota, Shaina Raza, Maged Shoman, Achyut Paudel, Manoj Karkee
分类: cs.CV
发布日期: 2025-01-29 (更新: 2025-03-21)
备注: 52 pages
🔗 代码/项目: GITHUB
💡 一句话要点
综述:多模态大语言模型在图像、文本和语音数据增强中的应用
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大语言模型 数据增强 图像增强 文本增强 语音增强 深度学习 迁移学习
📋 核心要点
- 现有数据增强综述主要关注传统机器学习和深度学习方法,或仅限于文本或图像模态,缺乏对多模态LLM数据增强的全面分析。
- 该综述旨在通过调研最新的文献,概述多模态LLM在图像、文本和语音数据增强中的应用方法,并分析其局限性。
- 该综述还探讨了解决现有方法局限性的潜在方案,为未来利用多模态LLM提升数据集质量和多样性的研究奠定基础。
📝 摘要(中文)
过去五年,研究方向已从传统的机器学习(ML)和深度学习(DL)方法转向利用大型语言模型(LLM),包括多模态,进行数据增强,以增强深度卷积神经网络训练的泛化能力并对抗过拟合。然而,现有的综述主要集中于ML和DL技术或有限的模态(文本或图像),在解决基于LLM方法的最新进展和多模态应用方面仍然存在差距。本综述填补了这一空白,通过探索最近利用多模态LLM来增强图像、文本和音频数据的文献,提供了对这些过程的全面理解。我们概述了基于LLM的图像、文本和语音增强中使用的各种方法,并讨论了当前方法中发现的局限性。此外,我们从文献中确定了解决这些局限性的潜在方案,以提高使用多模态LLM进行数据增强实践的有效性。本综述为未来的研究奠定了基础,旨在改进和扩展多模态LLM的使用,以增强深度学习应用的数据集质量和多样性。
🔬 方法详解
问题定义:论文旨在解决深度学习模型训练中数据增强的问题,特别是如何利用多模态大语言模型(LLM)来提升图像、文本和语音数据的质量和多样性。现有方法要么局限于传统的数据增强技术,要么只关注单一模态的数据增强,无法充分利用多模态LLM的强大能力。
核心思路:论文的核心思路是系统性地调研和分析近年来利用多模态LLM进行数据增强的研究,总结各种方法的技术特点、优势和局限性,并探讨未来的发展方向。通过对现有方法的梳理和归纳,为研究人员提供一个全面的参考框架,从而促进多模态LLM在数据增强领域的应用。
技术框架:该综述没有提出新的技术框架,而是对现有文献进行整理和分析。其主要流程包括:1) 确定研究范围,即多模态LLM在图像、文本和语音数据增强中的应用;2) 收集相关文献,包括学术论文、技术报告等;3) 对文献进行分类和整理,按照不同的模态和方法进行归纳;4) 分析各种方法的优缺点,并探讨未来的发展方向。
关键创新:该综述的创新之处在于其全面性和及时性。它首次系统性地总结了多模态LLM在图像、文本和语音数据增强中的应用,涵盖了最新的研究进展。此外,该综述还指出了现有方法的局限性,并提出了潜在的解决方案,为未来的研究提供了有价值的参考。
关键设计:该综述的关键设计在于其分类体系和分析框架。它将现有方法按照不同的模态(图像、文本、语音)和技术特点进行分类,并对每种方法的优缺点进行详细分析。此外,该综述还探讨了多模态LLM在数据增强中的应用前景,并提出了未来的研究方向。
🖼️ 关键图片
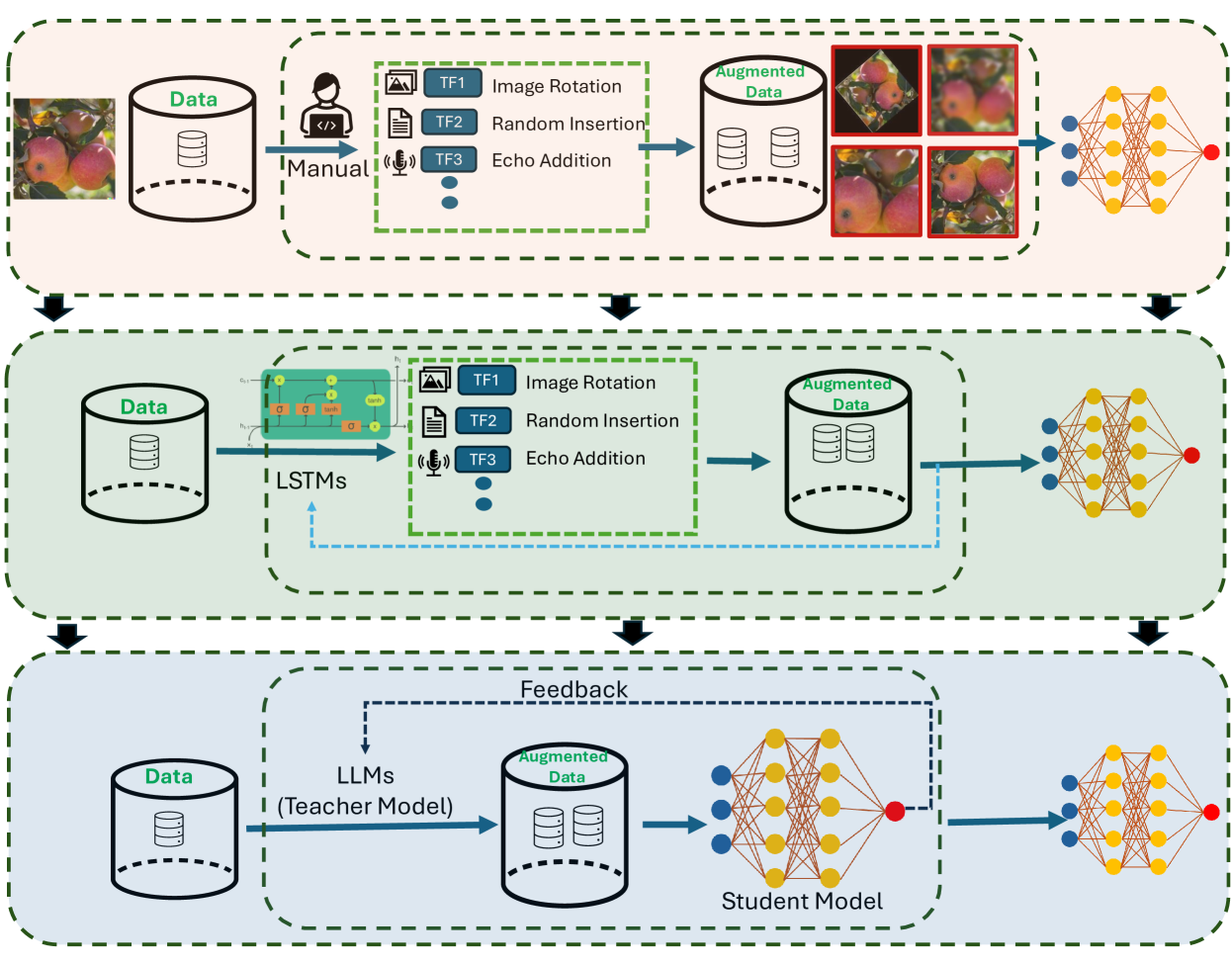
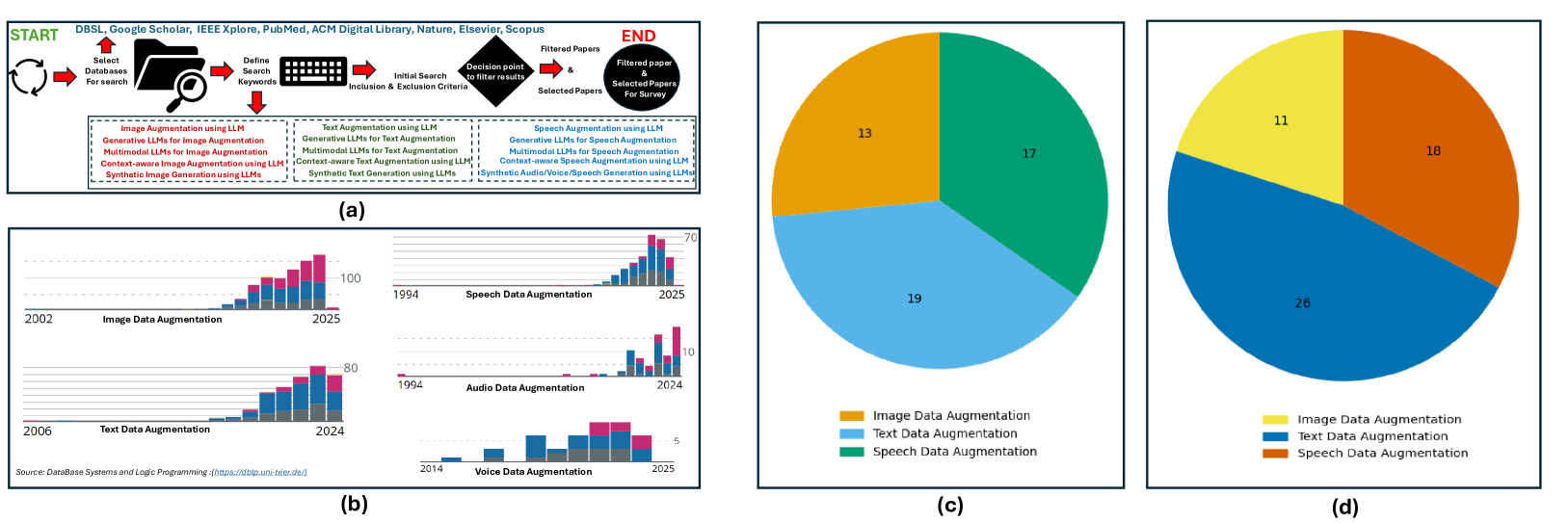
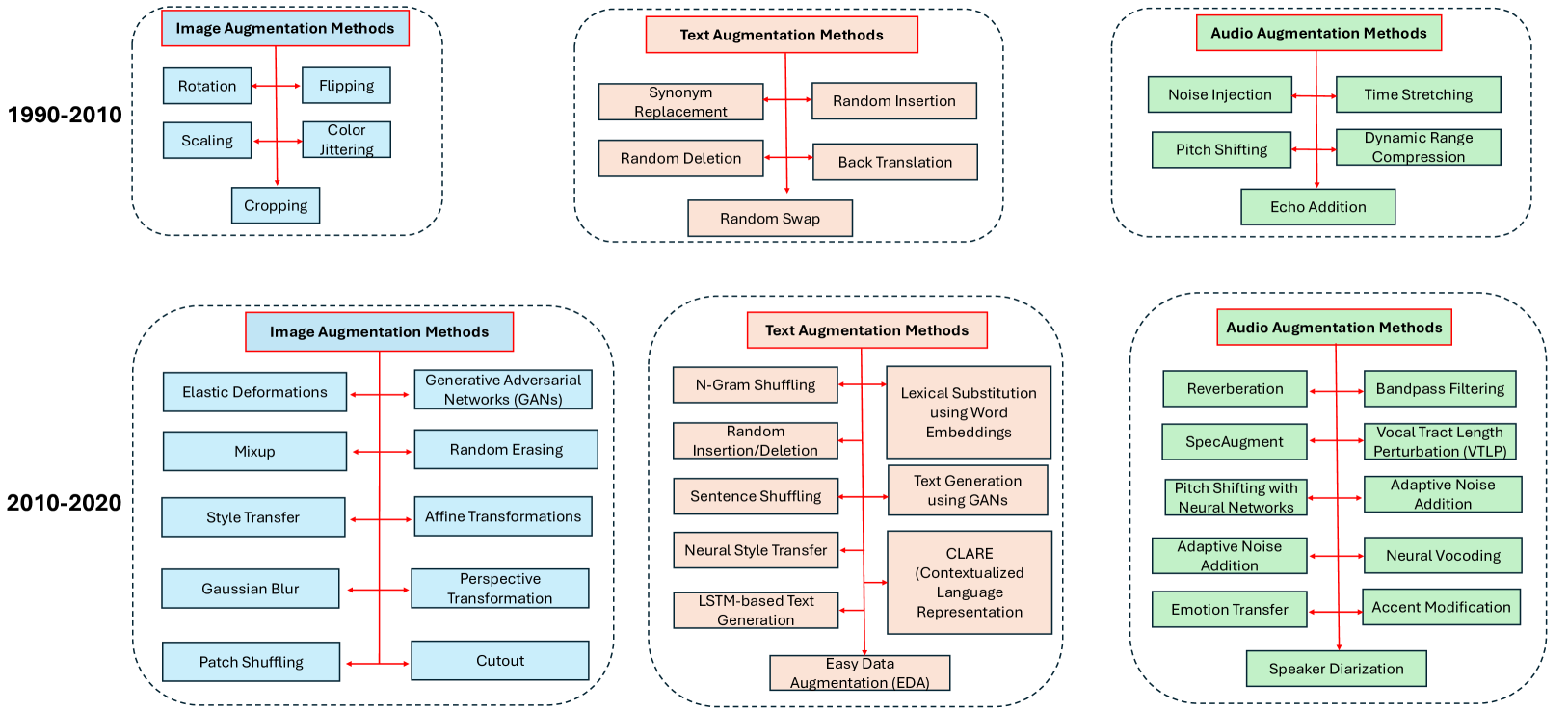
📊 实验亮点
该综述全面总结了多模态LLM在图像、文本和语音数据增强中的应用,涵盖了最新的研究进展。它不仅概述了各种方法的优缺点,还指出了现有方法的局限性,并提出了潜在的解决方案。该综述为研究人员提供了一个有价值的参考框架,有助于推动多模态LLM在数据增强领域的进一步发展。
🎯 应用场景
该研究成果可应用于各种需要数据增强的深度学习任务,例如图像识别、自然语言处理、语音识别等。通过利用多模态LLM生成更多样化和高质量的数据,可以有效提升模型的泛化能力和鲁棒性,从而提高模型在实际应用中的性能。未来,该研究有望推动多模态LLM在更多领域的应用。
📄 摘要(原文)
In the past five years, research has shifted from traditional Machine Learning (ML) and Deep Learning (DL) approaches to leveraging Large Language Models (LLMs) , including multimodality, for data augmentation to enhance generalization, and combat overfitting in training deep convolutional neural networks. However, while existing surveys predominantly focus on ML and DL techniques or limited modalities (text or images), a gap remains in addressing the latest advancements and multi-modal applications of LLM-based methods. This survey fills that gap by exploring recent literature utilizing multimodal LLMs to augment image, text, and audio data, offering a comprehensive understanding of these processes. We outlined various methods employed in the LLM-based image, text and speech augmentation, and discussed the limitations identified in current approaches. Additionally, we identified potential solutions to these limitations from the literature to enhance the efficacy of data augmentation practices using multimodal LLMs. This survey serves as a foundation for future research, aiming to refine and expand the use of multimodal LLMs in enhancing dataset quality and diversity for deep learning applications. (Surveyed Paper GitHub Repo: https://github.com/WSUAgRobotics/data-aug-multi-modal-llm. Keywords: LLM data augmentation, Grok text data augmentation, DeepSeek image data augmentation, Grok speech data augmentation, GPT audio augmentation, voice augmentation, DeepSeek for data augmentation, DeepSeek R1 text data augmentation, DeepSeek R1 image augmentation, Image Augmentation using LLM, Text Augmentation using LLM, LLM data augmentation for deep learning applications)