Efficient Redundancy Reduction for Open-Vocabulary Semantic Segmentation
作者: Lin Chen, Qi Yang, Kun Ding, Zhihao Li, Gang Shen, Fei Li, Qiyuan Cao, Shiming Xiang
分类: cs.CV
发布日期: 2025-01-29 (更新: 2025-12-21)
DOI: 10.1016/j.neucom.2025.132229
💡 一句话要点
ERR-Seg:通过减少冗余信息,高效解决开放词汇语义分割问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇语义分割 冗余减少 分层代价图 代价聚合 高效推理 视觉语言模型 像素级预测
📋 核心要点
- 现有开放词汇语义分割方法计算成本高,推理速度慢,主要原因是代价图构建过程中的冗余信息和代价聚合过程中的低效序列建模。
- ERR-Seg通过引入冗余减少的分层代价图(RRHC)和冗余减少的代价聚合(RRCA)来解决上述问题,从而实现高效的开放词汇语义分割。
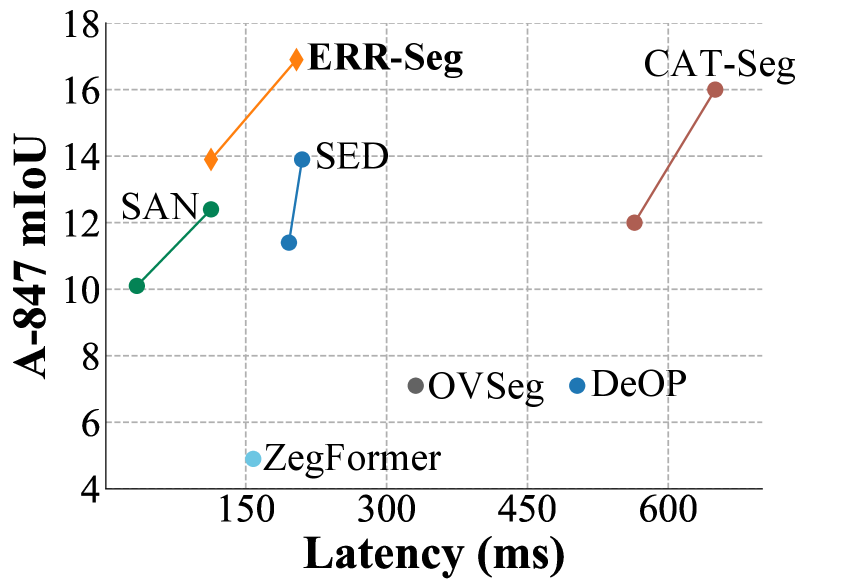
- 实验结果表明,ERR-Seg在ADE20K-847基准测试上,性能提升了5.6%,同时实现了3.1倍的加速,验证了其有效性。
📝 摘要(中文)
开放词汇语义分割(OVSS)是一项开放世界任务,旨在将图像中的每个像素分配给由任意文本描述定义的特定类别。虽然大规模视觉-语言模型已经展示了卓越的开放词汇能力,但其图像级别的预训练限制了其在像素级密集预测任务(如OVSS)上的有效性。最近基于代价的方法通过构建像素-文本代价图并通过代价聚合机制细化它们来缩小这种粒度差距。尽管取得了有希望的性能,但这些方法存在计算成本高和推理延迟长的问题。在本文中,我们确定了基于代价的OVSS框架中的两个主要冗余来源:代价图构建过程中引入的冗余信息以及代价聚合中低效的序列建模。为了解决这些问题,我们提出了一种高效的架构ERR-Seg,它结合了冗余减少的分层代价图(RRHC)和冗余减少的代价聚合(RRCA)。具体来说,RRHC通过为每个图像定制一个紧凑的类别词汇来减少冗余类别通道,并集成分层代价图来丰富语义表示。RRCA通过在聚合之前执行空间级别和类别级别的序列缩减来减轻计算负担。总的来说,ERR-Seg产生了一种用于OVSS的轻量级结构,其特点是在不影响准确性的情况下,显著节省了内存和计算量。与之前在ADE20K-847基准测试上的最先进方法相比,ERR-Seg提高了5.6%的性能,同时实现了3.1倍的加速。
🔬 方法详解
问题定义:开放词汇语义分割旨在将图像中的每个像素分配到由文本描述定义的类别。现有基于代价图的方法虽然性能不错,但计算量大,推理速度慢,难以实际应用。主要瓶颈在于代价图构建过程引入了大量冗余信息,以及代价聚合过程中的序列建模效率低下。
核心思路:ERR-Seg的核心思路是通过减少代价图构建和代价聚合过程中的冗余信息,从而降低计算复杂度,提高推理速度。具体来说,通过定制化的类别词汇和分层代价图来减少类别通道的冗余,并通过空间和类别级别的序列缩减来优化代价聚合过程。
技术框架:ERR-Seg的整体架构包含两个主要模块:冗余减少的分层代价图(RRHC)和冗余减少的代价聚合(RRCA)。首先,RRHC模块为每个图像构建定制化的类别词汇,并生成分层代价图。然后,RRCA模块对代价图进行空间和类别级别的序列缩减,并进行聚合,最终得到像素级别的语义分割结果。
关键创新:ERR-Seg的关键创新在于提出了冗余减少的分层代价图(RRHC)和冗余减少的代价聚合(RRCA)两个模块。RRHC通过定制化的类别词汇和分层代价图,有效减少了类别通道的冗余,提高了语义表示的效率。RRCA通过空间和类别级别的序列缩减,显著降低了代价聚合的计算复杂度。
关键设计:RRHC模块的关键设计包括:1) 使用预训练的文本编码器为每个图像生成定制化的类别词汇;2) 构建多尺度的代价图,以捕捉不同尺度的语义信息。RRCA模块的关键设计包括:1) 使用可学习的权重对空间和类别序列进行缩减;2) 使用高效的序列建模方法(如Transformer)进行代价聚合。
🖼️ 关键图片


📊 实验亮点
ERR-Seg在ADE20K-847基准测试上取得了显著的性能提升。与之前的state-of-the-art方法相比,ERR-Seg的性能提高了5.6%,同时实现了3.1倍的加速。这表明ERR-Seg在保证精度的前提下,显著降低了计算成本,提高了推理效率,具有很强的实用价值。
🎯 应用场景
ERR-Seg在机器人感知、自动驾驶、遥感图像分析等领域具有广泛的应用前景。它可以帮助机器人理解周围环境,实现更精确的导航和交互。在自动驾驶领域,可以用于识别道路上的各种物体和场景,提高驾驶安全性。在遥感图像分析中,可以用于土地利用分类、灾害监测等任务,为决策提供支持。该研究的未来影响在于推动开放世界场景下的语义理解能力,使计算机视觉系统能够处理更复杂、更动态的环境。
📄 摘要(原文)
Open-vocabulary semantic segmentation (OVSS) is an open-world task that aims to assign each pixel within an image to a specific class defined by arbitrary text descriptions. While large-scale vision-language models have shown remarkable open-vocabulary capabilities, their image-level pretraining limits effectiveness on pixel-wise dense prediction tasks like OVSS. Recent cost-based methods narrow this granularity gap by constructing pixel-text cost maps and refining them via cost aggregation mechanisms. Despite achieving promising performance, these approaches suffer from high computational costs and long inference latency. In this paper, we identify two major sources of redundancy in the cost-based OVSS framework: redundant information introduced during cost maps construction and inefficient sequence modeling in cost aggregation. To address these issues, we propose ERR-Seg, an efficient architecture that incorporates Redundancy-Reduced Hierarchical Cost maps (RRHC) and Redundancy-Reduced Cost Aggregation (RRCA). Specifically, RRHC reduces redundant class channels by customizing a compact class vocabulary for each image and integrates hierarchical cost maps to enrich semantic representation. RRCA alleviates computational burden by performing both spatial-level and class-level sequence reduction before aggregation. Overall, ERR-Seg results in a lightweight structure for OVSS, characterized by substantial memory and computational savings without compromising accuracy. Compared to previous state-of-the-art methods on the ADE20K-847 benchmark, ERR-Seg improves performance by $5.6\%$ while achieving a 3.1$\times$ speedup.