HOMER: Homography-Based Efficient Multi-view 3D Object Removal
作者: Jingcheng Ni, Weiguang Zhao, Daniel Wang, Ziyao Zeng, Chenyu You, Alex Wong, Kaizhu Huang
分类: cs.CV
发布日期: 2025-01-29 (更新: 2025-04-14)
💡 一句话要点
HOMER:基于单应性的高效多视角3D物体移除方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D物体移除 多视角重建 单应性 辐射场 图像修复 场景编辑 神经渲染 掩码传播
📋 核心要点
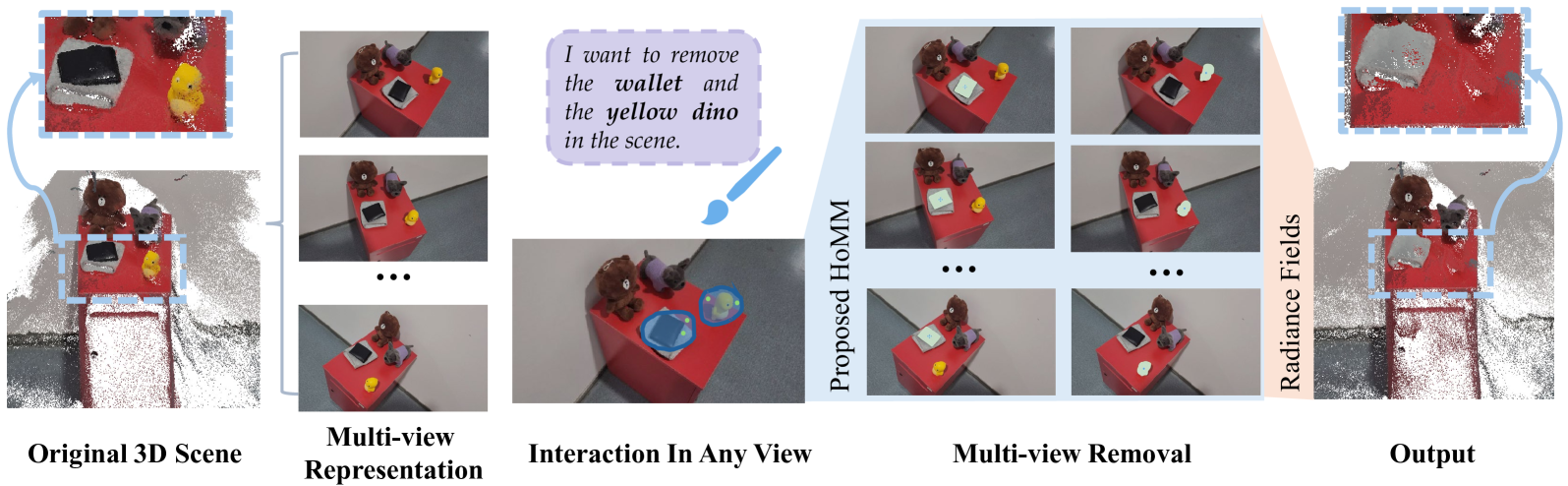
- 现有3D物体移除方法在多视角场景中,难以兼顾一致性、可用性和计算效率,用户交互不直观,掩码生成效率低,修复计算成本高。
- HOMER通过直观的区域交互、高效的HoMM模块进行掩码传播,并结合单应性映射的关键视图修复,实现了高效高质量的物体移除。
- 实验表明,HOMER在公共基准和新提出的数据集上均取得了SOTA性能,运行时间仅为现有方法的五分之一,且具有良好的泛化性。
📝 摘要(中文)
3D物体移除是3D场景编辑中的重要子任务,在场景理解、增强现实和机器人技术等领域有着广泛的应用。然而,现有的方法在多视角设置中难以在一致性、可用性和计算效率之间取得理想的平衡。这些限制主要是由于源视图中不直观的用户交互、低效的多视角物体掩码生成、计算成本高昂的图像修复过程以及缺乏跨不同辐射场表示的适用性。为了应对这些挑战,我们提出了一种新的流程,提高了多视角物体掩码生成和图像修复的质量和效率。我们的方法在源视图中引入了一种直观的基于区域的交互机制,并消除了对相机姿态或额外模型训练的需求。我们采用轻量级的HoMM模块来实现高质量、高效率的多视角掩码传播。在图像修复阶段,我们通过仅在选定的关键视图上执行修复,并通过基于单应性的映射将结果传播到其他视图,从而进一步降低了计算成本。我们的流程与各种辐射场框架兼容,包括NeRF和3D高斯溅射,展示了在实际场景中改进的通用性和实用性。此外,我们提出了一个新的3D多物体移除数据集,与现有数据集相比,具有更大的物体多样性和视角变化。在公共基准和我们提出的数据集上的实验表明,我们的方法实现了最先进的性能,同时将运行时间减少到领先基线所需时间的五分之一。
🔬 方法详解
问题定义:论文旨在解决多视角3D场景中高效、高质量的物体移除问题。现有方法存在用户交互不直观、多视角掩码生成效率低、图像修复计算成本高以及对不同辐射场表示的兼容性差等痛点。这些问题限制了3D物体移除技术在实际场景中的应用。
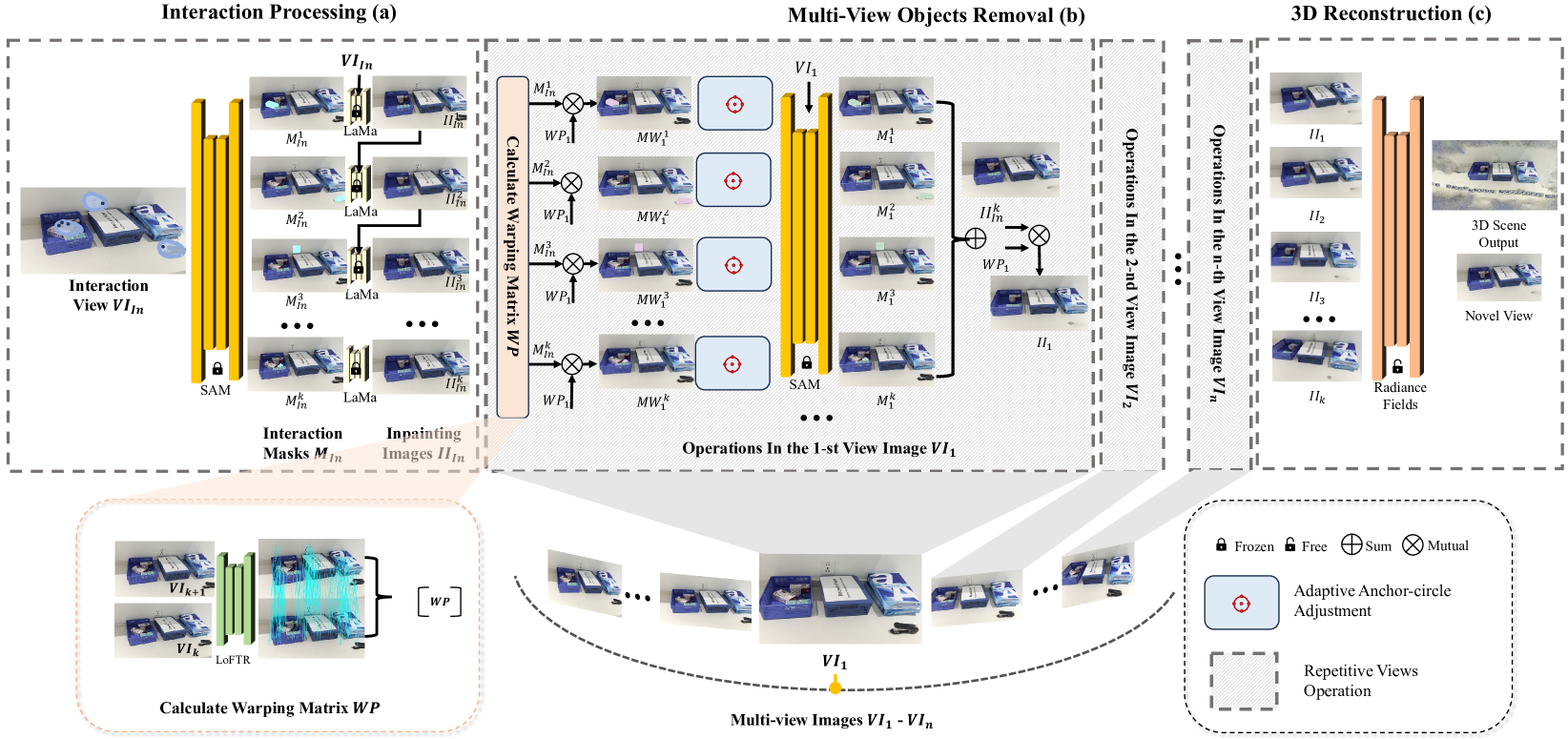
核心思路:论文的核心思路是通过结合基于单应性的几何约束和轻量级的神经网络模块,实现高效的多视角掩码传播和关键视图修复。利用单应性可以有效地将信息从一个视图传递到另一个视图,从而减少了计算量,并提高了修复的一致性。直观的区域交互方式简化了用户操作。
技术框架:HOMER的整体流程包括以下几个主要阶段:1) 用户在源视图中进行基于区域的交互,指定要移除的物体;2) 使用HoMM模块进行多视角掩码传播,生成其他视图中的物体掩码;3) 选择关键视图进行图像修复;4) 通过基于单应性的映射将修复结果传播到其他视图。该流程无需相机姿态信息或额外的模型训练,并且兼容不同的辐射场表示。
关键创新:论文的关键创新在于:1) 提出了轻量级的HoMM (Homography-based Mask Mapping) 模块,用于高效的多视角掩码传播;2) 采用基于单应性的映射,将关键视图的修复结果传播到其他视图,从而显著降低了计算成本;3) 提出了一个更具挑战性的3D多物体移除数据集,包含更大的物体多样性和视角变化。
关键设计:HoMM模块的具体结构未知,但其核心思想是利用单应性变换将源视图的掩码信息传递到其他视图。关键视图的选择策略未知,但其目标是选择能够代表场景几何结构和纹理信息的视图。损失函数和网络结构等技术细节在论文中未明确说明,需要进一步查阅论文原文。
🖼️ 关键图片

📊 实验亮点
实验结果表明,HOMER在公共基准和新提出的数据集上均取得了最先进的性能,并且运行时间仅为领先基线所需时间的五分之一。这表明HOMER在效率和质量方面都具有显著的优势。此外,HOMER还具有良好的泛化性,可以应用于不同的辐射场框架,如NeRF和3D高斯溅射。
🎯 应用场景
该研究成果可广泛应用于场景理解、增强现实、机器人技术等领域。例如,在增强现实应用中,可以用于移除场景中不需要的物体,从而改善用户体验。在机器人技术中,可以用于清理场景中的障碍物,从而提高机器人的导航能力。此外,该技术还可以应用于虚拟现实、游戏开发等领域。
📄 摘要(原文)
3D object removal is an important sub-task in 3D scene editing, with broad applications in scene understanding, augmented reality, and robotics. However, existing methods struggle to achieve a desirable balance among consistency, usability, and computational efficiency in multi-view settings. These limitations are primarily due to unintuitive user interaction in the source view, inefficient multi-view object mask generation, computationally expensive inpainting procedures, and a lack of applicability across different radiance field representations. To address these challenges, we propose a novel pipeline that improves the quality and efficiency of multi-view object mask generation and inpainting. Our method introduces an intuitive region-based interaction mechanism in the source view and eliminates the need for camera poses or extra model training. Our lightweight HoMM module is employed to achieve high-quality multi-view mask propagation with enhanced efficiency. In the inpainting stage, we further reduce computational costs by performing inpainting only on selected key views and propagating the results to other views via homography-based mapping. Our pipeline is compatible with a variety of radiance field frameworks, including NeRF and 3D Gaussian Splatting, demonstrating improved generalizability and practicality in real-world scenarios. Additionally, we present a new 3D multi-object removal dataset with greater object diversity and viewpoint variation than existing datasets. Experiments on public benchmarks and our proposed dataset show that our method achieves state-of-the-art performance while reducing runtime to one-fifth of that required by leading baselines.