LFTR: Learning-Free Token Reduction for Multimodal Large Language Models
作者: Zihui Zhao, Yingxin Li, Yang Li
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-01-29 (更新: 2025-09-30)
💡 一句话要点
提出一种免训练的视觉Token缩减方法LFTR,用于加速多模态大语言模型推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 Token缩减 免训练学习 视觉问答 模型加速
📋 核心要点
- 多模态大语言模型计算开销大,推理速度慢,视觉token数量过多是主要瓶颈,现有token缩减方法依赖模型架构和大量训练。
- LFTR利用视觉表示的冗余性,无需训练即可有效减少视觉tokens,同时保持甚至提升MLLM的推理性能。
- 实验表明,LFTR在多个MLLM架构上实现了高达16倍的视觉tokens缩减,并在视觉问答基准测试中保持或提升了性能。
📝 摘要(中文)
多模态大语言模型(MLLMs)在各种多模态任务中表现出卓越的性能,但其部署常常受到巨大的计算需求和较长的推理时间的限制。由于视觉模态通常包含比文本模态更全面的信息,导致编码后的表示包含大量的tokens,进而由于注意力机制的二次复杂度而产生显著的计算开销。现有的token缩减方法通常局限于特定的模型架构,并且常常需要大量的重新训练或微调,限制了它们在许多最先进模型中的适用性。本文提出了一种用于MLLMs的免训练token缩减(LFTR)方法。LFTR可以无缝集成到大多数开源MLLM架构中,而无需额外的微调。通过利用视觉表示中的冗余,我们的方法有效地减少了tokens,同时保持了MLLMs的一般推理性能。我们在多个MLLM架构(LLaVA, MiniGPT, QwenVL)上进行了实验,结果表明,LFTR实现了高达16倍的视觉tokens缩减,同时在主流视觉问答基准测试中保持甚至提高了性能,所有这些都在免训练设置中实现。此外,LFTR与其他加速技术(如视觉编码器压缩和训练后量化)互补,进一步促进了MLLMs的有效部署。我们的项目可在https://anonymous.4open.science/r/LFTR-AAAI-0528上找到。
🔬 方法详解
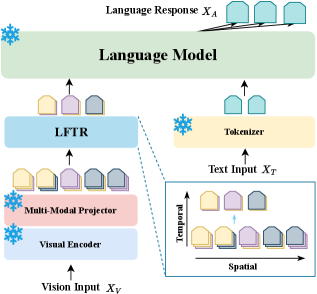
问题定义:论文旨在解决多模态大语言模型(MLLMs)中视觉token数量过多导致计算开销大、推理速度慢的问题。现有token缩减方法通常需要针对特定模型架构进行大量重新训练或微调,限制了其通用性和易用性。
核心思路:论文的核心思路是利用视觉表示中存在的冗余信息,设计一种免训练的token缩减方法。通过去除冗余的视觉tokens,降低计算复杂度,同时尽可能保持模型的推理性能。这样可以避免耗时的训练过程,并方便地应用于各种MLLM架构。
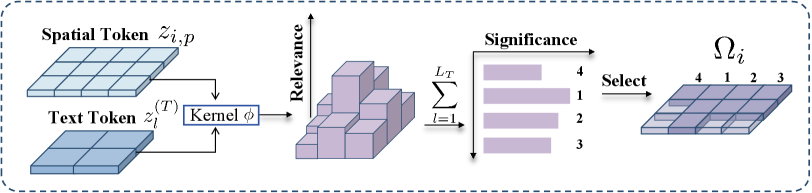
技术框架:LFTR方法可以分为以下几个主要步骤:1. 视觉特征提取:使用预训练的视觉编码器提取图像的视觉特征。2. Token重要性评估:对每个视觉token的重要性进行评估,例如通过计算token的梯度范数或注意力权重。3. Token选择:根据重要性评估结果,选择保留最重要的tokens,并丢弃冗余的tokens。4. MLLM推理:将缩减后的视觉tokens输入到MLLM中进行推理。
关键创新:LFTR最关键的创新点在于其免训练的特性。与现有方法相比,LFTR无需针对特定模型进行训练或微调,可以直接应用于各种MLLM架构。此外,LFTR还提出了一种有效评估token重要性的方法,可以在保证模型性能的同时,尽可能地减少tokens数量。
关键设计:论文中没有明确给出关键参数设置和损失函数等细节。Token重要性评估的具体方法(例如梯度范数或注意力权重)以及Token选择的阈值是需要根据具体任务和模型进行调整的关键设计。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LFTR在LLaVA、MiniGPT和QwenVL等多个MLLM架构上实现了高达16倍的视觉tokens缩减,同时在主流视觉问答基准测试中保持甚至提高了性能。例如,在某些数据集上,LFTR甚至能够带来轻微的性能提升,这表明该方法不仅可以加速推理,还可以去除噪声tokens,从而提高模型的鲁棒性。
🎯 应用场景
LFTR可广泛应用于各种需要高效部署多模态大语言模型的场景,例如移动设备上的视觉问答、机器人视觉导航、智能监控等。通过降低计算需求和加速推理速度,LFTR能够使MLLMs在资源受限的环境中也能高效运行,并促进其在实际应用中的普及。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have demonstrated exceptional success in various multimodal tasks, yet their deployment is frequently limited by substantial computational demands and prolonged inference times. Given that the vision modality typically contains more comprehensive information than the text modality, resulting in encoded representations comprising an extensive number of tokens, leading to significant computational overhead due to the quadratic complexity of the attention mechanism. Current token reduction methods are typically restricted to specific model architectures and often necessitate extensive retraining or fine-tuning, restricting their applicability to many state-of-the-art models. In this paper, we introduce a learning-free token reduction (LFTR) method designed for MLLMs. LFTR can be seamlessly integrated into most open-source MLLM architectures without requiring additional fine-tuning. By capitalizing on the redundancy in visual representations, our approach effectively reduces tokens while preserving the general inference performance of MLLMs. We conduct experiments on multiple MLLM architectures (LLaVA, MiniGPT, QwenVL), and our results show that LFTR achieves up to a $16\times$ reduction of visual tokens while maintaining or even enhancing performance on mainstream vision question-answering benchmarks, all in a learning-free setting. Additionally, LFTR is complementary to other acceleration techniques, such as vision encoder compression and post-training quantization, further promoting the efficient deployment of MLLMs. Our project is available at https://anonymous.4open.science/r/LFTR-AAAI-0528.