Contextual Self-paced Learning for Weakly Supervised Spatio-Temporal Video Grounding
作者: Akash Kumar, Zsolt Kira, Yogesh Singh Rawat
分类: cs.CV
发布日期: 2025-01-28 (更新: 2025-03-16)
备注: ICLR'25 Main Conference. Project Page: https://akash2907.github.io/cospal_webpage
💡 一句话要点
提出CoSPaL,解决弱监督时空视频定位中复杂查询理解和时序一致性问题。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 弱监督学习 时空视频定位 多模态融合 上下文建模 自步学习
📋 核心要点
- 现有方法在弱监督时空视频定位中,对复杂查询的理解不足,且时序预测一致性较差,难以适应复杂场景。
- CoSPaL通过Tubelet Phrase Grounding、Contextual Referral Grounding和Self-Paced Scene Understanding三个模块,提升模型性能。
- CoSPaL利用自步学习策略,逐步增加训练难度,使模型能够从粗到细地理解视频内容,从而适应复杂场景。
📝 摘要(中文)
本文关注弱监督时空视频定位(WSTVG)任务,旨在仅利用文本查询在时空上定位特定对象,无需边界框监督。受多模态基础模型在定位任务中取得进展的启发,我们首先探索了最先进的目标检测模型在WSTVG中的潜力。尽管它们具有强大的零样本能力,但我们的实验表明其存在显著局限性,包括不一致的时序预测、对复杂查询理解不足以及难以适应困难场景。为此,我们提出了一种名为CoSPaL(Contextual Self-Paced Learning)的新方法,旨在克服这些限制。CoSPaL集成了三个核心组件:(1)Tubelet Phrase Grounding (TPG),通过将文本查询链接到tubelet引入时空预测;(2)Contextual Referral Grounding (CRG),通过提取上下文信息来细化对象识别,从而提高对复杂查询的理解;(3)Self-Paced Scene Understanding (SPS),一种渐进式增加任务难度的训练范式,使模型能够通过从粗到细的理解过渡来适应复杂场景。
🔬 方法详解
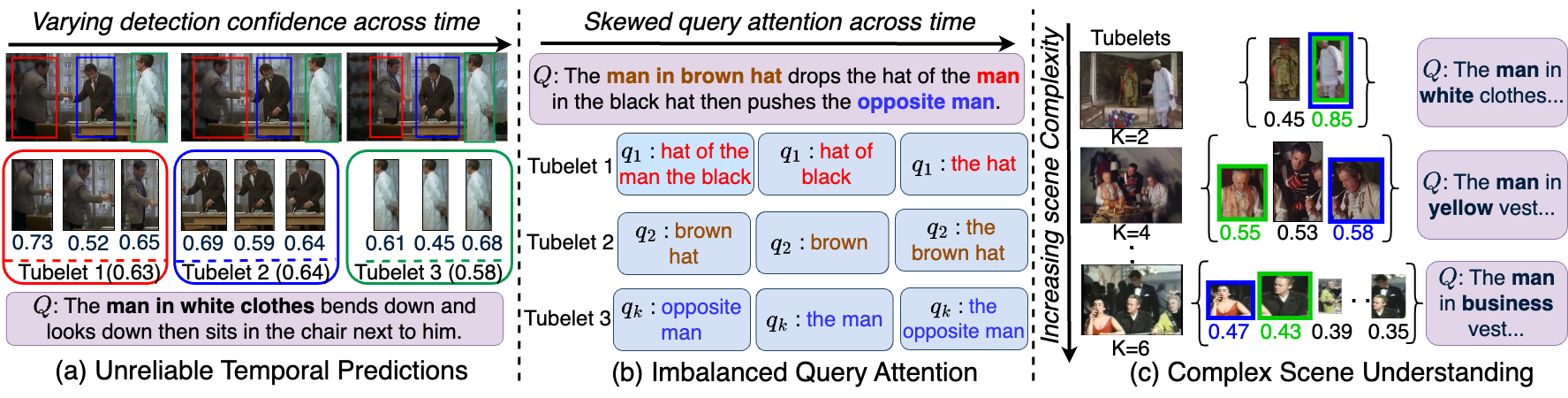
问题定义:论文旨在解决弱监督时空视频定位(WSTVG)问题。现有方法,特别是直接应用预训练目标检测模型时,在处理复杂文本查询、保持时序预测一致性以及适应困难场景方面存在不足。这些痛点限制了模型在实际应用中的性能和泛化能力。
核心思路:论文的核心思路是利用上下文信息和自步学习策略,逐步提升模型对视频内容的理解能力。通过将文本查询与视频中的tubelet关联,并利用上下文信息细化对象识别,模型能够更准确地定位目标对象。自步学习则帮助模型从简单到复杂地学习,从而更好地适应各种场景。
技术框架:CoSPaL包含三个主要模块:Tubelet Phrase Grounding (TPG)、Contextual Referral Grounding (CRG)和Self-Paced Scene Understanding (SPS)。TPG负责将文本查询与视频中的tubelet关联,实现时空预测。CRG通过提取上下文信息来细化对象识别,提高对复杂查询的理解。SPS则采用自步学习策略,逐步增加训练难度,使模型能够适应复杂场景。整体流程是从视频中提取tubelet特征,然后利用TPG和CRG进行定位,最后通过SPS进行训练优化。
关键创新:论文的关键创新在于将上下文信息和自步学习策略相结合,用于弱监督时空视频定位。与现有方法相比,CoSPaL能够更好地理解复杂查询,保持时序预测一致性,并适应各种场景。自步学习策略使得模型能够从简单到复杂地学习,从而更好地泛化到新的视频和查询。
关键设计:TPG模块可能涉及使用Transformer或其他注意力机制来关联文本查询和tubelet特征。CRG模块可能使用图神经网络或其他上下文建模技术来提取上下文信息。SPS模块的关键在于设计合适的难度评估指标和学习策略,例如根据定位的置信度或查询的复杂度来调整训练样本的权重。损失函数可能包括定位损失、上下文一致性损失和自步学习损失。
🖼️ 关键图片


📊 实验亮点
论文提出了CoSPaL方法,通过集成Tubelet Phrase Grounding、Contextual Referral Grounding和Self-Paced Scene Understanding三个模块,有效提升了弱监督时空视频定位的性能。实验结果表明,CoSPaL在多个数据集上取得了显著的提升,尤其是在处理复杂查询和困难场景时,表现出更强的鲁棒性和准确性。具体性能数据未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于视频监控、智能安防、人机交互等领域。例如,在视频监控中,可以通过文本查询快速定位特定事件或人物。在人机交互中,可以实现基于自然语言的视频内容检索和编辑。该研究还有助于提升视频内容理解和分析的智能化水平。
📄 摘要(原文)
In this work, we focus on Weakly Supervised Spatio-Temporal Video Grounding (WSTVG). It is a multimodal task aimed at localizing specific subjects spatio-temporally based on textual queries without bounding box supervision. Motivated by recent advancements in multi-modal foundation models for grounding tasks, we first explore the potential of state-of-the-art object detection models for WSTVG. Despite their robust zero-shot capabilities, our adaptation reveals significant limitations, including inconsistent temporal predictions, inadequate understanding of complex queries, and challenges in adapting to difficult scenarios. We propose CoSPaL (Contextual Self-Paced Learning), a novel approach which is designed to overcome these limitations. CoSPaL integrates three core components: (1) Tubelet Phrase Grounding (TPG), which introduces spatio-temporal prediction by linking textual queries to tubelets; (2) Contextual Referral Grounding (CRG), which improves comprehension of complex queries by extracting contextual information to refine object identification over time; and (3) Self-Paced Scene Understanding (SPS), a training paradigm that progressively increases task difficulty, enabling the model to adapt to complex scenarios by transitioning from coarse to fine-grained understanding.