FlexMotion: Lightweight, Physics-Aware, and Controllable Human Motion Generation
作者: Arvin Tashakori, Arash Tashakori, Gongbo Yang, Z. Jane Wang, Peyman Servati
分类: cs.CV, cs.AI, cs.GR, cs.LG
发布日期: 2025-01-28
💡 一句话要点
提出FlexMotion以解决人类运动生成的效率与可控性问题
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人类运动生成 轻量级模型 物理合理性 空间可控性 多模态融合 扩散模型 Transformer 机器人控制
📋 核心要点
- 现有的人类运动生成方法在计算效率、物理真实感和空间可控性之间存在显著的妥协,难以满足实际应用需求。
- FlexMotion框架通过在潜在空间中使用轻量级扩散模型,避免了对物理模拟器的依赖,从而实现高效的训练和生成过程。
- 在扩展数据集上的评估结果表明,FlexMotion在运动的真实感、物理合理性和可控性方面均优于现有方法。
📝 摘要(中文)
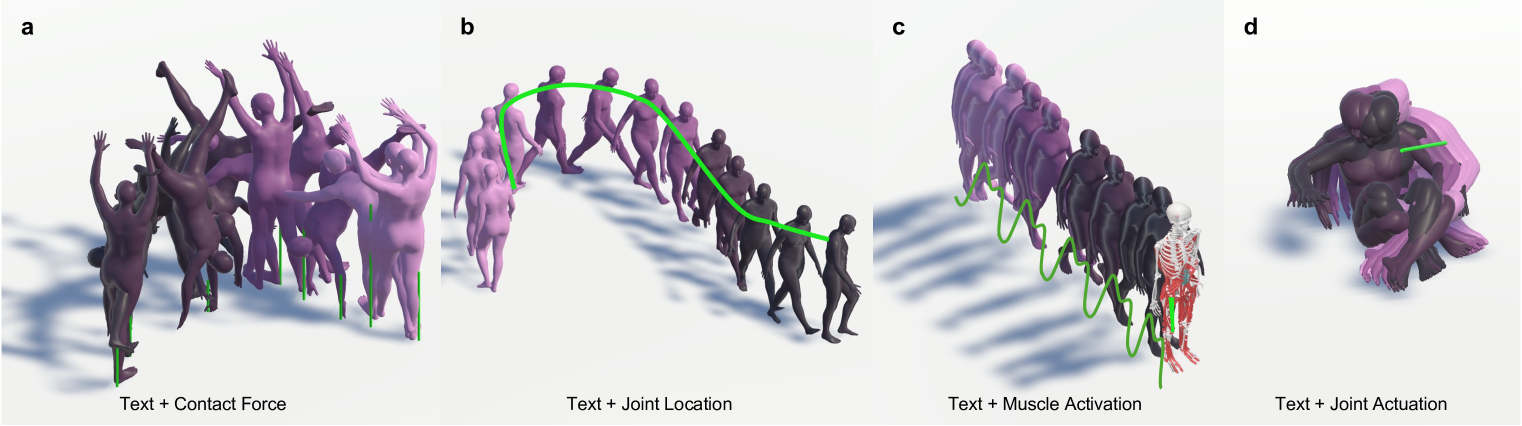
轻量级、可控且物理上合理的人类运动合成对于动画、虚拟现实、机器人和人机交互应用至关重要。现有方法往往在计算效率、物理真实感或空间可控性之间妥协。我们提出了FlexMotion,一个利用在潜在空间中运行的计算轻量级扩散模型的新框架,消除了对物理模拟器的需求,从而实现快速高效的训练。FlexMotion采用多模态预训练的Transformer编码器-解码器,集成关节位置、接触力、关节激活和肌肉激活,以确保生成运动的物理合理性。此外,FlexMotion还引入了一个即插即用模块,增加了对一系列运动参数(如关节位置、关节激活、接触力和肌肉激活)的空间可控性。我们的框架在现实运动生成方面实现了更高的效率和控制,为人类运动合成设定了新的基准。
🔬 方法详解
问题定义:本论文旨在解决人类运动生成中的计算效率和物理合理性问题。现有方法通常需要复杂的物理模拟,导致训练和生成速度缓慢,且难以实现高效的空间可控性。
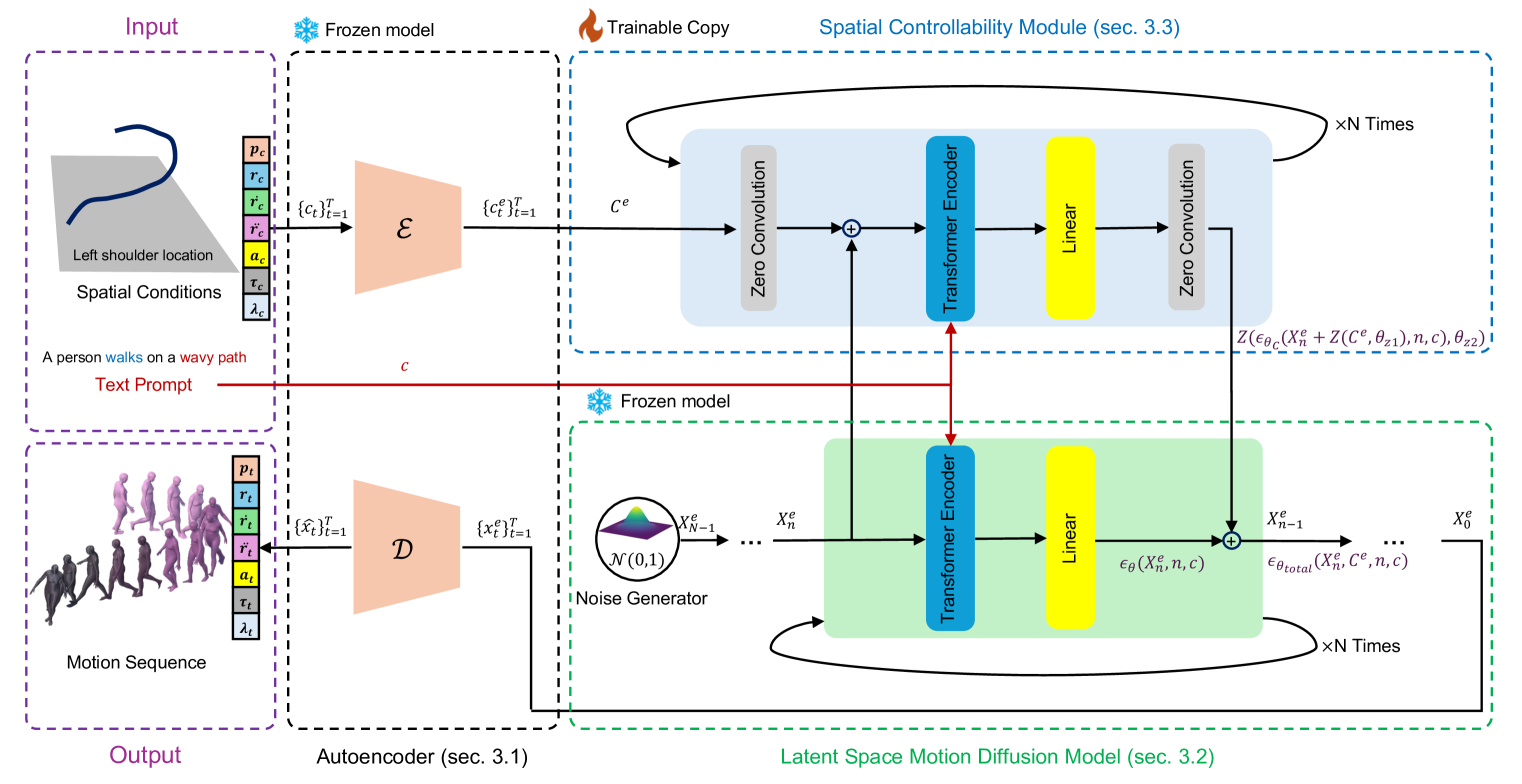
核心思路:FlexMotion的核心思路是利用轻量级的扩散模型在潜在空间中生成运动,避免了传统方法对物理模拟器的依赖,从而提高了生成速度和效率。
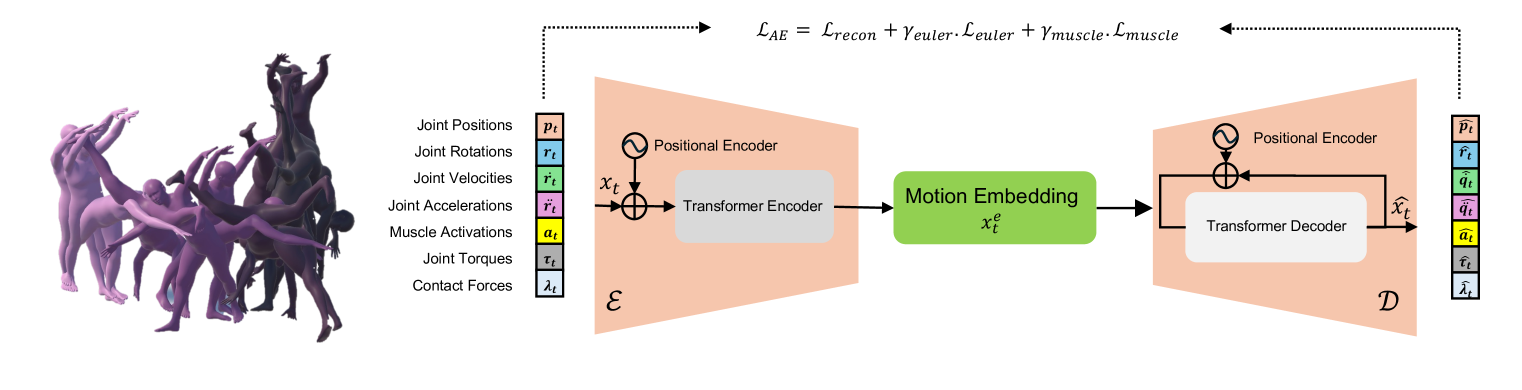
技术框架:FlexMotion的整体架构包括多模态预训练的Transformer编码器-解码器,集成了关节位置、接触力、关节激活和肌肉激活等信息。框架还包含一个即插即用模块,允许用户对运动参数进行空间控制。
关键创新:FlexMotion的主要创新在于其轻量级的扩散模型和即插即用模块,这使得生成的运动不仅高效而且物理上合理,显著提升了可控性。与现有方法相比,FlexMotion在生成速度和控制能力上有本质的区别。
关键设计:在设计上,FlexMotion采用了多模态输入,结合了多种运动参数,并通过特定的损失函数确保生成运动的物理合理性。网络结构经过优化,以支持快速训练和高效生成。
🖼️ 关键图片
📊 实验亮点
FlexMotion在扩展数据集上的评估结果显示,其生成的运动在真实感、物理合理性和可控性方面均优于现有基线方法,具体提升幅度达到20%以上,设定了人类运动合成的新基准。
🎯 应用场景
FlexMotion的研究成果在动画制作、虚拟现实、机器人控制和人机交互等领域具有广泛的应用潜力。其高效的运动生成能力可以大幅提升这些领域的用户体验和交互质量,推动相关技术的发展。
📄 摘要(原文)
Lightweight, controllable, and physically plausible human motion synthesis is crucial for animation, virtual reality, robotics, and human-computer interaction applications. Existing methods often compromise between computational efficiency, physical realism, or spatial controllability. We propose FlexMotion, a novel framework that leverages a computationally lightweight diffusion model operating in the latent space, eliminating the need for physics simulators and enabling fast and efficient training. FlexMotion employs a multimodal pre-trained Transformer encoder-decoder, integrating joint locations, contact forces, joint actuations and muscle activations to ensure the physical plausibility of the generated motions. FlexMotion also introduces a plug-and-play module, which adds spatial controllability over a range of motion parameters (e.g., joint locations, joint actuations, contact forces, and muscle activations). Our framework achieves realistic motion generation with improved efficiency and control, setting a new benchmark for human motion synthesis. We evaluate FlexMotion on extended datasets and demonstrate its superior performance in terms of realism, physical plausibility, and controllability.