Large Models in Dialogue for Active Perception and Anomaly Detection
作者: Tzoulio Chamiti, Nikolaos Passalis, Anastasios Tefas
分类: cs.CV, cs.AI
发布日期: 2025-01-27
备注: Accepted to International Conference of Pattern Recognition (ICPR 2024)
💡 一句话要点
提出基于LLM对话的主动感知框架,用于无人机自主监控中的异常检测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 主动感知 异常检测 无人机 视觉问答
📋 核心要点
- 现有自主空中监控方法难以从远处或在先前未遇到的场景中识别异常,限制了其应用范围。
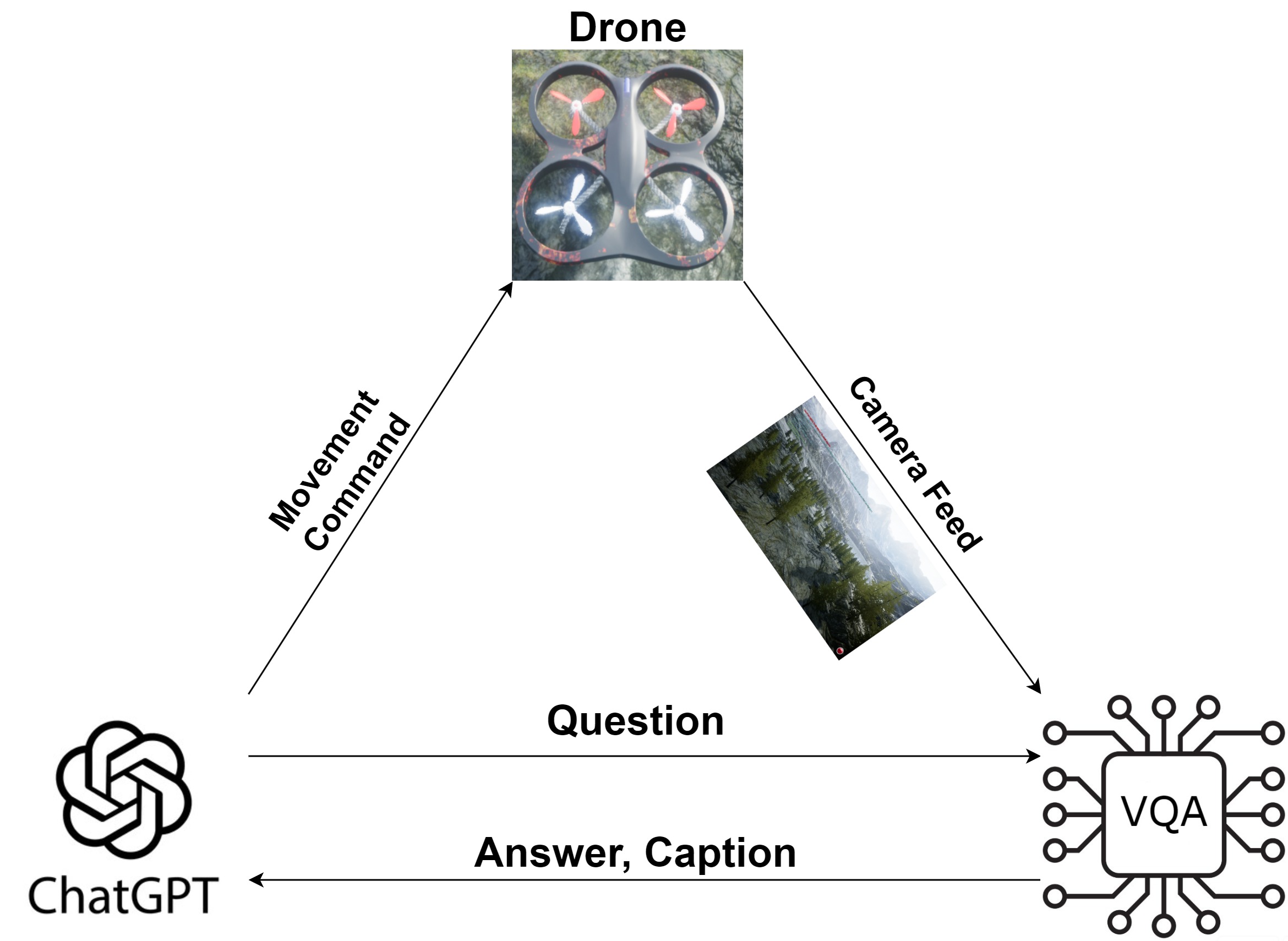
- 论文提出一种基于LLM对话的主动感知框架,通过LLM控制无人机并与VQA模型交互,主动探索环境并收集信息。
- 实验结果表明,该方法能够生成更详细的场景描述,并有效检测潜在危险,提升了异常检测的性能。
📝 摘要(中文)
本文提出了一种新颖的框架,利用大型语言模型(LLM)的先进能力,主动收集信息并在新场景中执行异常检测。该框架采用基于LLM的模型对话方法,其中两个深度学习模型进行对话,以主动控制无人机,从而提高感知和异常检测的准确性。实验在高保真模拟环境中进行,LLM被赋予一组预定的自然语言移动命令,这些命令被映射到可执行的代码函数。此外,部署了一个多模态视觉问答(VQA)模型,负责视觉问答和图像描述任务。通过让两个模型进行对话,LLM提出探索性问题,同时控制无人机飞向场景的不同部分,从而提供了一种实现主动感知的新方法。通过利用LLM的推理能力,可以输出对场景的改进的详细描述,超越了现有的静态感知方法。除了信息收集之外,该方法还用于异常检测,结果表明所提出的方法在告知和警告潜在危险方面的有效性。
🔬 方法详解
问题定义:自主空中监控需要从难以接近的区域收集信息,并且经常需要在远处或先前未遇到的场景中识别异常。现有的静态感知方法无法充分利用环境信息,导致异常检测的准确率较低。因此,需要一种能够主动探索环境并收集相关信息的感知方法。
核心思路:论文的核心思路是利用大型语言模型(LLM)的推理能力和自然语言理解能力,构建一个主动感知框架。通过让LLM与视觉问答(VQA)模型进行对话,LLM可以根据VQA模型提供的视觉信息,主动提出探索性问题,并控制无人机飞向场景的不同部分,从而收集更全面的信息,提高异常检测的准确率。
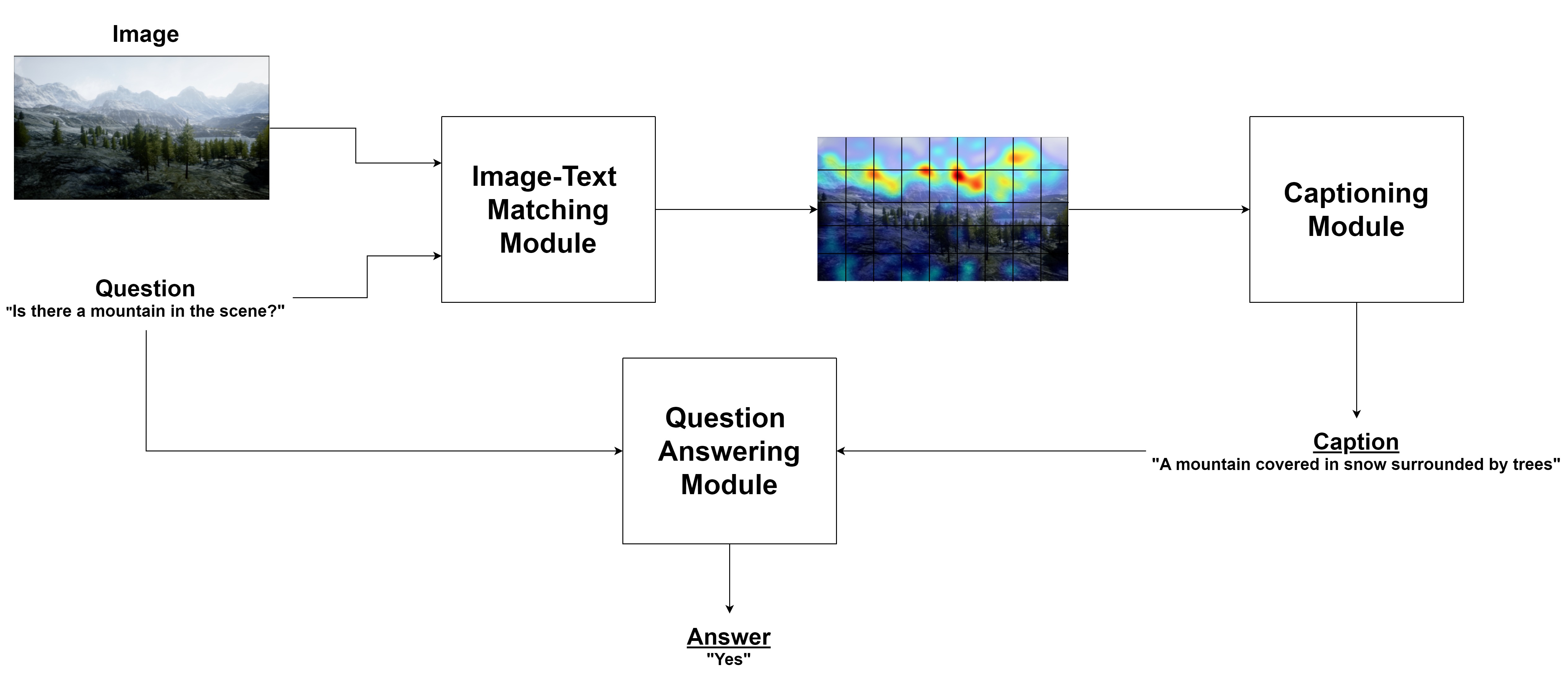
技术框架:该框架包含两个主要模块:LLM控制模块和VQA模块。LLM控制模块负责生成自然语言指令,控制无人机的运动。VQA模块负责回答LLM提出的问题,并提供场景的视觉描述。这两个模块通过对话进行交互,LLM根据VQA模块的反馈,不断调整无人机的运动轨迹,从而实现主动感知。
关键创新:该方法最重要的技术创新点在于将LLM应用于主动感知任务。与传统的静态感知方法相比,该方法能够利用LLM的推理能力和自然语言理解能力,主动探索环境并收集相关信息,从而提高异常检测的准确率。此外,该方法还提出了一种基于LLM对话的主动感知框架,为主动感知任务提供了一种新的解决方案。
关键设计:LLM被赋予一组预定的自然语言移动命令,这些命令被映射到可执行的代码函数,用于控制无人机的运动。VQA模型采用多模态融合的方法,将视觉信息和文本信息结合起来,从而提高问答的准确率。实验中,使用高保真模拟环境来评估该方法的性能。
🖼️ 关键图片

📊 实验亮点
该论文通过实验验证了所提出方法的有效性。实验结果表明,通过LLM对话进行主动感知,可以生成更详细的场景描述,并有效检测潜在危险。具体性能数据和对比基线信息在摘要中未明确给出,属于未知信息,需要在论文正文中查找。
🎯 应用场景
该研究成果可应用于多种场景,例如灾害救援、环境监测、安全巡逻等。通过主动感知和异常检测,可以及时发现潜在的危险,提高响应速度,减少损失。未来,该技术有望与更先进的无人机平台和传感器集成,实现更智能、更高效的自主监控。
📄 摘要(原文)
Autonomous aerial monitoring is an important task aimed at gathering information from areas that may not be easily accessible by humans. At the same time, this task often requires recognizing anomalies from a significant distance or not previously encountered in the past. In this paper, we propose a novel framework that leverages the advanced capabilities provided by Large Language Models (LLMs) to actively collect information and perform anomaly detection in novel scenes. To this end, we propose an LLM based model dialogue approach, in which two deep learning models engage in a dialogue to actively control a drone to increase perception and anomaly detection accuracy. We conduct our experiments in a high fidelity simulation environment where an LLM is provided with a predetermined set of natural language movement commands mapped into executable code functions. Additionally, we deploy a multimodal Visual Question Answering (VQA) model charged with the task of visual question answering and captioning. By engaging the two models in conversation, the LLM asks exploratory questions while simultaneously flying a drone into different parts of the scene, providing a novel way to implement active perception. By leveraging LLMs reasoning ability, we output an improved detailed description of the scene going beyond existing static perception approaches. In addition to information gathering, our approach is utilized for anomaly detection and our results demonstrate the proposed methods effectiveness in informing and alerting about potential hazards.