The Linear Attention Resurrection in Vision Transformer
作者: Chuanyang Zheng
分类: cs.CV, cs.AI
发布日期: 2025-01-27
💡 一句话要点
提出L$^2$ViT,结合线性注意力与局部注意力,实现高效全局表征学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Vision Transformer 线性注意力 全局表征 局部注意力 图像分类 目标检测 语义分割 计算效率
📋 核心要点
- 传统ViT的softmax注意力机制计算复杂度高,限制了其在高分辨率图像上的应用。
- L$^2$ViT结合线性全局注意力和局部窗口注意力,在保证全局信息捕获的同时降低计算复杂度。
- L$^2$ViT在ImageNet-1K上达到84.4%的Top-1准确率,并在目标检测和语义分割等下游任务中表现出色。
📝 摘要(中文)
Vision Transformer (ViT) 在计算机视觉领域取得了显著进展。然而,ViT 中使用的 softmax 注意力机制在时间和内存上具有二次复杂度,限制了 ViT 在高分辨率图像上的应用。本文重新审视了注意力机制的设计,并提出了一种线性注意力方法来解决这一限制,该方法不会像现有方法(例如 Swin 的局部窗口注意力)那样牺牲 ViT 捕获全局表征的核心优势。进一步研究了线性注意力和 softmax 注意力之间的关键差异。实验结果表明,线性注意力缺乏集中注意力矩阵分布的基本属性。受此启发,引入了一个局部集中模块来增强线性注意力。通过结合增强的线性全局注意力和局部窗口注意力,提出了一种新的 ViT 架构,称为 L$^2$ViT。值得注意的是,L$^2$ViT 可以有效地捕获全局交互和局部表征,同时享受线性计算复杂度。大量实验证明了 L$^2$ViT 的强大性能。在图像分类方面,L$^2$ViT 在 ImageNet-1K 上实现了 84.4% 的 Top-1 准确率,无需任何额外的训练数据或标签。通过在 ImageNet-22k 上进一步预训练,在分辨率为 384$^2$ 时微调后,达到了 87.0% 的准确率。对于下游任务,L$^2$ViT 作为骨干网络在目标检测和语义分割方面表现出良好的性能。
🔬 方法详解
问题定义:ViT模型中的softmax注意力机制,其计算复杂度随输入图像分辨率呈平方增长,这使得ViT难以应用于高分辨率图像或长序列数据。现有方法,如Swin Transformer,虽然通过局部窗口注意力降低了计算复杂度,但牺牲了全局感受野,限制了模型对全局信息的建模能力。
核心思路:本文的核心思路是利用线性注意力机制来近似softmax注意力,从而将计算复杂度降低到线性级别。同时,为了弥补线性注意力在集中注意力分布方面的不足,引入局部集中模块,增强模型对局部信息的建模能力。通过结合线性全局注意力和局部窗口注意力,L$^2$ViT旨在在计算效率和全局表征能力之间取得平衡。
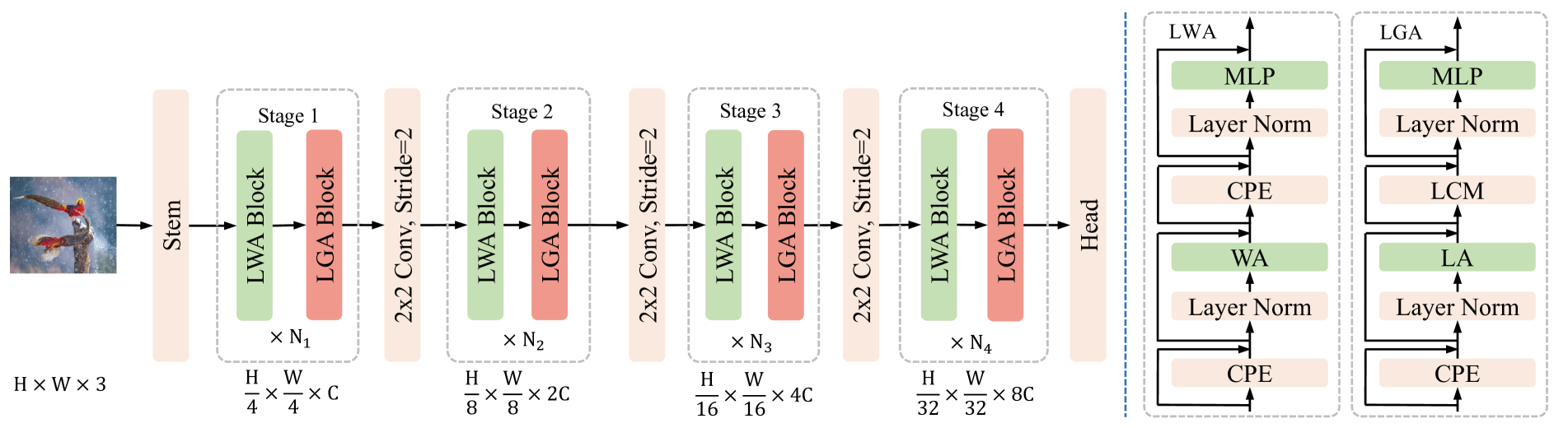
技术框架:L$^2$ViT的整体架构基于Transformer结构,主要包含以下模块:线性全局注意力模块、局部窗口注意力模块和局部集中模块。线性全局注意力模块负责捕获图像的全局信息,局部窗口注意力模块负责增强局部细节的建模,局部集中模块则用于提高线性注意力的集中度。这些模块交替堆叠,形成L$^2$ViT的整体网络结构。
关键创新:L$^2$ViT的关键创新在于结合了线性全局注意力和局部窗口注意力,并引入了局部集中模块。线性注意力降低了计算复杂度,局部窗口注意力增强了局部建模能力,而局部集中模块则弥补了线性注意力的不足,使得模型能够在计算效率和表征能力之间取得更好的平衡。与传统ViT相比,L$^2$ViT具有更高的计算效率,可以应用于高分辨率图像。与Swin Transformer相比,L$^2$ViT具有更强的全局表征能力。
关键设计:局部集中模块的具体实现方式未知,论文中可能没有详细描述。线性注意力的具体实现方式也需要参考论文细节。损失函数和优化器的选择可能与标准ViT类似,但可能针对线性注意力进行了调整。网络结构的具体参数设置,如Transformer层数、注意力头数等,需要参考论文中的实验设置。
🖼️ 关键图片


📊 实验亮点
L$^2$ViT在ImageNet-1K图像分类任务上取得了显著的成果,在没有额外数据或标签的情况下,达到了84.4%的Top-1准确率。通过在ImageNet-22k上进行预训练,并在384x384分辨率下进行微调,L$^2$ViT的准确率进一步提升至87.0%。此外,L$^2$ViT在目标检测和语义分割等下游任务中也表现出良好的性能,证明了其作为骨干网络的有效性。
🎯 应用场景
L$^2$ViT具有广泛的应用前景,可以作为图像分类、目标检测、语义分割等计算机视觉任务的骨干网络。其高效的计算性能使其能够应用于高分辨率图像处理、视频分析等领域。此外,L$^2$ViT的设计思想也可以推广到其他序列建模任务中,例如自然语言处理。
📄 摘要(原文)
Vision Transformers (ViTs) have recently taken computer vision by storm. However, the softmax attention underlying ViTs comes with a quadratic complexity in time and memory, hindering the application of ViTs to high-resolution images. We revisit the attention design and propose a linear attention method to address the limitation, which doesn't sacrifice ViT's core advantage of capturing global representation like existing methods (e.g. local window attention of Swin). We further investigate the key difference between linear attention and softmax attention. Our empirical results suggest that linear attention lacks a fundamental property of concentrating the distribution of the attention matrix. Inspired by this observation, we introduce a local concentration module to enhance linear attention. By incorporating enhanced linear global attention and local window attention, we propose a new ViT architecture, dubbed L$^2$ViT. Notably, L$^2$ViT can effectively capture both global interactions and local representations while enjoying linear computational complexity. Extensive experiments demonstrate the strong performance of L$^2$ViT. On image classification, L$^2$ViT achieves 84.4% Top-1 accuracy on ImageNet-1K without any extra training data or label. By further pre-training on ImageNet-22k, it attains 87.0% when fine-tuned with resolution 384$^2$. For downstream tasks, L$^2$ViT delivers favorable performance as a backbone on object detection as well as semantic segmentation.