BAG: Body-Aligned 3D Wearable Asset Generation
作者: Zhongjin Luo, Yang Li, Mingrui Zhang, Senbo Wang, Han Yan, Xibin Song, Taizhang Shang, Wei Mao, Hongdong Li, Xiaoguang Han, Pan Ji
分类: cs.CV, cs.AI, cs.GR
发布日期: 2025-01-27
备注: video: https://youtu.be/XJtG82LjQKc
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出BAG:一种身体对齐的3D可穿戴资产生成方法,实现自动穿戴。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 3D资产生成 可穿戴设备 扩散模型 ControlNet 身体对齐 多视角图像 虚拟试穿
📋 核心要点
- 现有3D形状生成模型难以自动生成可穿戴3D资产,缺乏对人体形状和姿态的有效利用。
- BAG方法利用ControlNet引导多视角扩散模型生成与人体对齐的图像,再通过3D扩散模型生成最终资产。
- 实验表明,BAG在图像提示跟随、形状多样性和质量上均优于现有方法,实现了更好的可穿戴资产生成效果。
📝 摘要(中文)
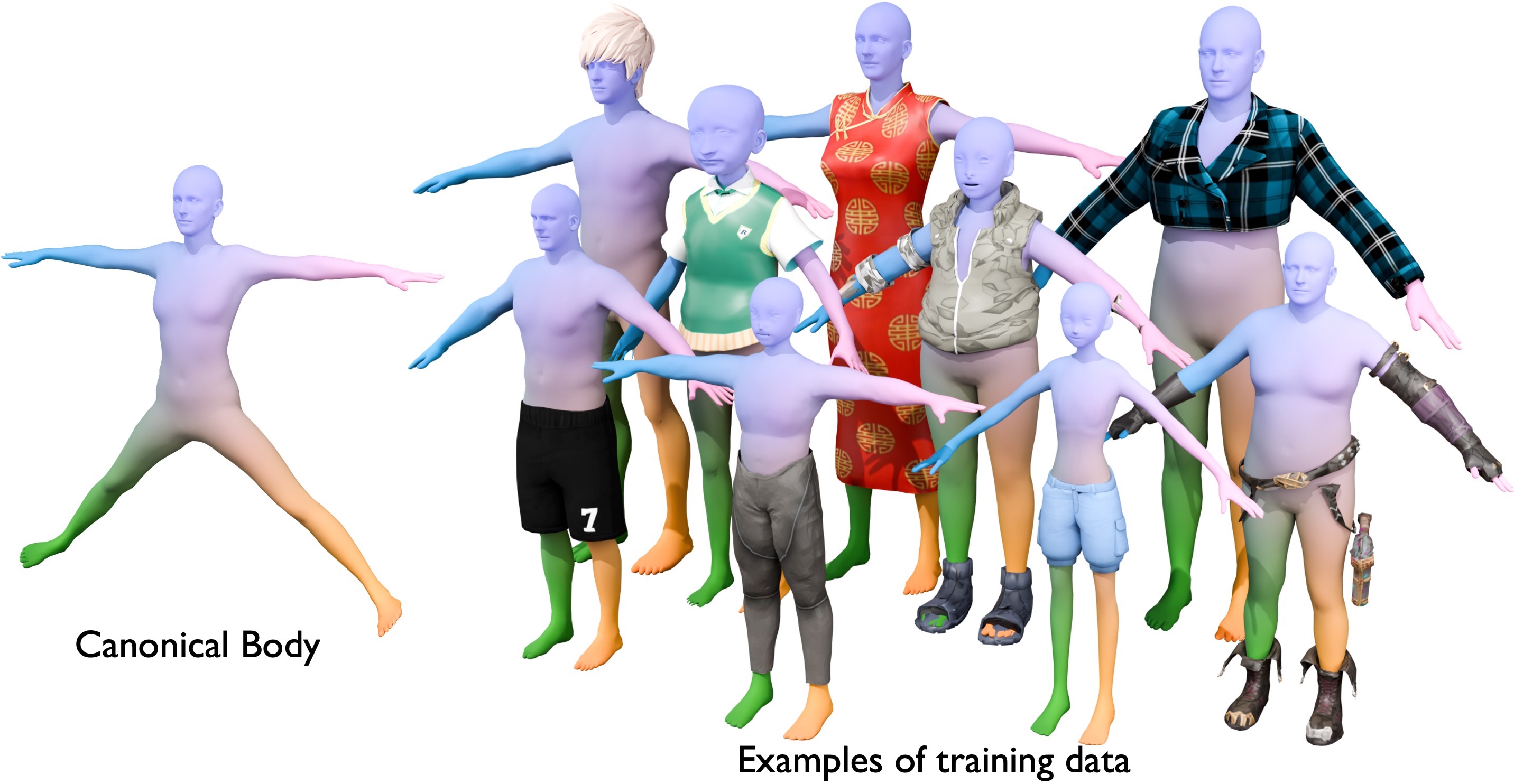
本文提出了一种身体对齐的资产生成方法(BAG),用于自动生成可穿戴的3D资产,并将其自动穿戴到给定的3D人体模型上。该方法通过人体形状和姿态信息来控制3D生成过程。具体而言,首先构建一个通用的单图像到一致多视角图像扩散模型,并在大型Objaverse数据集上进行训练,以实现多样性和泛化性。然后,训练一个ControlNet来引导多视角生成器生成身体对齐的多视角图像。控制信号利用目标人体模型的2D多视角投影,其中像素值表示规范空间中人体表面XYZ坐标。身体条件下的多视角扩散生成身体对齐的多视角图像,然后将其输入到原生3D扩散模型中,以生成资产的3D形状。最后,通过多视角轮廓监督恢复相似变换,并使用物理模拟器解决资产与身体的穿透问题,从而将3D资产精确地拟合到目标人体上。实验结果表明,该方法在图像提示跟随能力、形状多样性和形状质量方面优于现有方法。
🔬 方法详解
问题定义:现有方法难以利用通用的3D形状生成模型自动生成可穿戴的3D资产。主要痛点在于如何将生成过程与人体形状和姿态信息有效结合,保证生成资产与人体模型的适配性,避免穿透等问题。
核心思路:核心思路是利用人体形状和姿态信息作为控制信号,引导多视角图像扩散模型生成与人体对齐的多视角图像,再通过3D扩散模型将这些图像转化为3D资产。这样可以保证生成的资产在形状上与人体相匹配。
技术框架:整体框架包含以下几个主要阶段:1) 单图像到多视角图像扩散模型训练:在Objaverse数据集上训练一个通用的多视角图像扩散模型。2) ControlNet训练:训练一个ControlNet,以人体模型的2D多视角投影作为控制信号,引导多视角图像生成器生成身体对齐的图像。3) 3D资产生成:将生成的身体对齐的多视角图像输入到3D扩散模型中,生成3D资产的形状。4) 资产拟合:通过多视角轮廓监督恢复相似变换,并使用物理模拟器解决资产与身体的穿透问题,最终将3D资产精确地拟合到目标人体上。
关键创新:关键创新在于利用ControlNet将人体形状和姿态信息融入到多视角图像生成过程中,实现了身体对齐的3D资产生成。与现有方法相比,该方法能够更好地利用人体信息,生成更符合人体结构的资产。
关键设计:ControlNet的输入是人体模型的2D多视角投影,像素值代表规范空间中人体表面的XYZ坐标。损失函数包括多视角图像扩散模型的标准损失函数,以及用于恢复相似变换的多视角轮廓监督损失。物理模拟器用于检测和解决资产与身体的穿透问题,通过调整资产的形状和位置来避免穿透。
🖼️ 关键图片


📊 实验亮点
实验结果表明,BAG方法在图像提示跟随能力、形状多样性和形状质量方面均优于现有方法。通过与现有方法的对比,证明了BAG在生成身体对齐的3D可穿戴资产方面的优势。项目主页提供了更多实验结果和可视化展示。
🎯 应用场景
该研究成果可应用于虚拟试穿、游戏角色定制、虚拟化身设计等领域。通过自动生成与人体匹配的可穿戴3D资产,可以大大提高相关应用的用户体验和效率。未来,该技术有望进一步扩展到服装设计、个性化定制等领域,实现更智能化的3D内容创作。
📄 摘要(原文)
While recent advancements have shown remarkable progress in general 3D shape generation models, the challenge of leveraging these approaches to automatically generate wearable 3D assets remains unexplored. To this end, we present BAG, a Body-aligned Asset Generation method to output 3D wearable asset that can be automatically dressed on given 3D human bodies. This is achived by controlling the 3D generation process using human body shape and pose information. Specifically, we first build a general single-image to consistent multiview image diffusion model, and train it on the large Objaverse dataset to achieve diversity and generalizability. Then we train a Controlnet to guide the multiview generator to produce body-aligned multiview images. The control signal utilizes the multiview 2D projections of the target human body, where pixel values represent the XYZ coordinates of the body surface in a canonical space. The body-conditioned multiview diffusion generates body-aligned multiview images, which are then fed into a native 3D diffusion model to produce the 3D shape of the asset. Finally, by recovering the similarity transformation using multiview silhouette supervision and addressing asset-body penetration with physics simulators, the 3D asset can be accurately fitted onto the target human body. Experimental results demonstrate significant advantages over existing methods in terms of image prompt-following capability, shape diversity, and shape quality. Our project page is available at https://bag-3d.github.io/.