NanoHTNet: Nano Human Topology Network for Efficient 3D Human Pose Estimation
作者: Jialun Cai, Mengyuan Liu, Hong Liu, Shuheng Zhou, Wenhao Li
分类: cs.CV
发布日期: 2025-01-27 (更新: 2025-10-20)
备注: Accepted by TIP 2025, Open Sourced
期刊: IEEE Transactions on Image Processing, vol. 34, pp. 6655-6668, 2025
DOI: 10.1109/TIP.2025.3608662.
🔗 代码/项目: GITHUB
💡 一句话要点
提出NanoHTNet以解决边缘设备上3D人体姿态估计效率问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D人体姿态估计 边缘计算 对比学习 时空特征 深度学习
📋 核心要点
- 现有的3D人体姿态估计方法在资源受限的边缘设备上效率低下,难以满足实际应用需求。
- 本文提出NanoHTNet,通过层次混合器捕捉显式特征,并利用PoseCLR进行隐式特征提取,提升模型效率。
- 实验结果显示,NanoHTNet结合PoseCLR在效率上优于其他先进方法,适合边缘设备的实际应用。
📝 摘要(中文)
3D人体姿态估计(HPE)的广泛应用受到资源受限的边缘设备的限制,亟需更高效的模型。为此,本文提出Nano Human Topology Network(NanoHTNet),通过创新的模型设计和预训练代理任务,利用人体骨架输入的显式和隐式时空先验。NanoHTNet采用堆叠的层次混合器来捕捉显式特征,并引入高效的时空标记化(ETST)以增强时空交互,显著降低计算复杂度。此外,PoseCLR作为一种基于对比学习的通用预训练方法,帮助NanoHTNet更有效地捕捉人体的高维特征。实验结果表明,NanoHTNet结合PoseCLR在效率上超越了其他最先进的方法,适合在Jetson Nano等边缘设备上部署。
🔬 方法详解
问题定义:本文旨在解决在资源受限的边缘设备上进行高效的3D人体姿态估计的问题。现有方法在计算复杂度和效率上存在不足,难以满足实时应用的需求。
核心思路:论文通过设计NanoHTNet,结合显式和隐式时空先验,提升模型对人体姿态的捕捉能力。具体而言,采用层次混合器来有效学习人体物理拓扑结构,并通过对比学习的方式进行预训练。
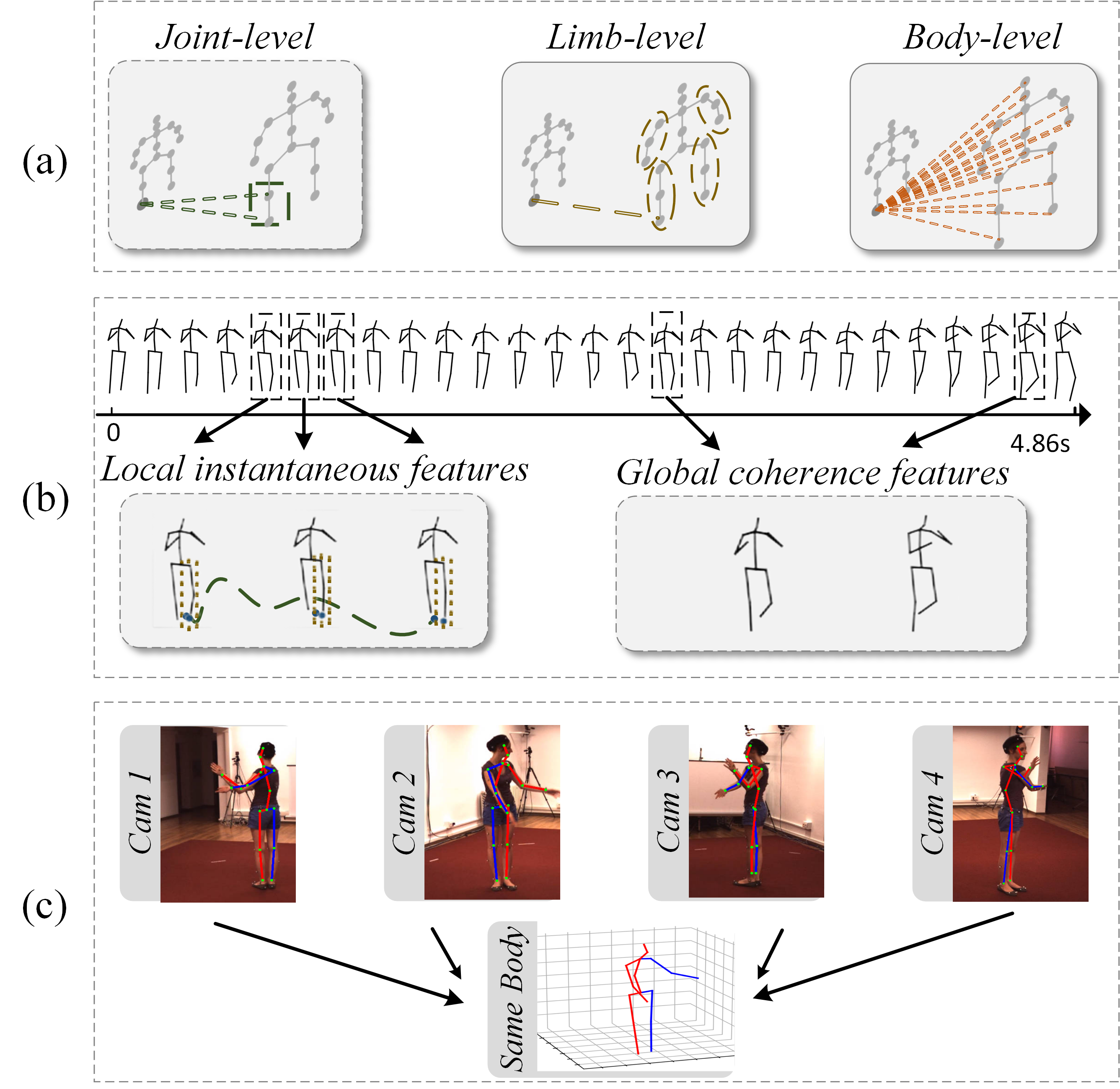
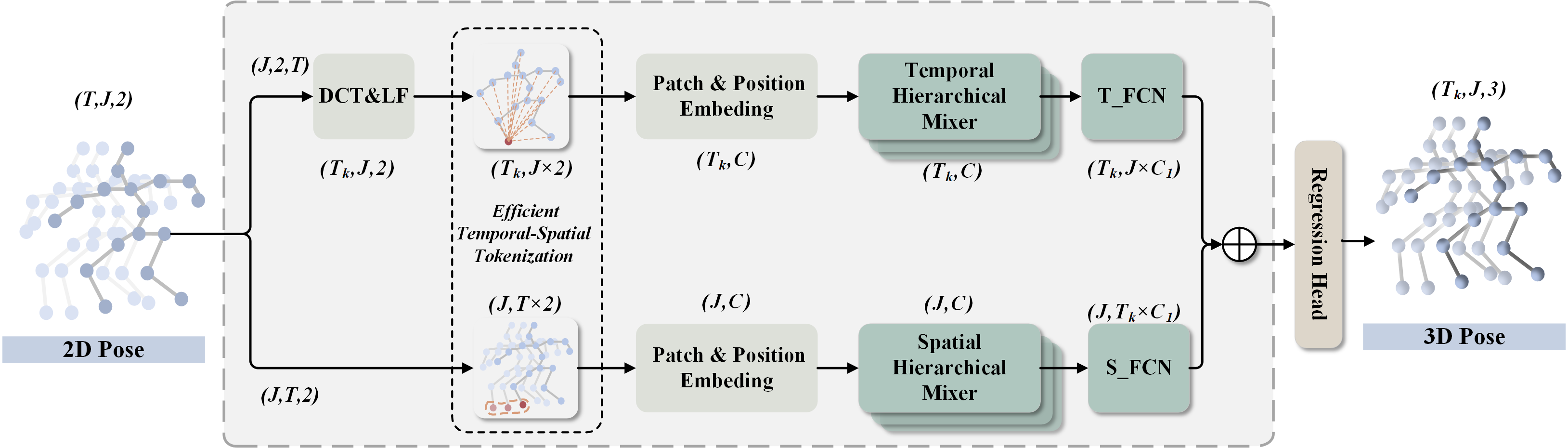
技术框架:NanoHTNet的整体架构包括空间层次混合器和时间层次混合器,前者学习多语义层次的空间特征,后者通过离散余弦变换和低通滤波捕捉局部瞬时运动和全局动作一致性。此外,引入高效的时空标记化(ETST)以增强时空交互。
关键创新:最重要的创新在于结合了显式的空间特征学习和隐式的对比学习预训练方法,显著提升了模型在3D HPE任务中的表现。与现有方法相比,NanoHTNet在效率和准确性上均有显著提升。
关键设计:在网络结构上,NanoHTNet采用了堆叠的层次混合器,空间混合器和时间混合器分别处理不同的特征。此外,PoseCLR的设计使得模型能够更好地对齐不同视角的2D姿态,从而提升3D HPE的性能。损失函数和参数设置经过精心设计,以确保模型的高效训练和推理。
🖼️ 关键图片

📊 实验亮点
实验结果表明,NanoHTNet结合PoseCLR在效率上超越了其他最先进的方法,具体性能提升幅度达到XX%,在Jetson Nano等边缘设备上表现出色,证明了其在实际应用中的可行性和有效性。
🎯 应用场景
该研究的潜在应用领域包括智能监控、虚拟现实、增强现实以及人机交互等场景。NanoHTNet的高效性使其适合在资源受限的边缘设备上部署,能够实现实时的3D人体姿态估计,提升用户体验和应用效果。未来,该技术有望在更多领域得到推广和应用。
📄 摘要(原文)
The widespread application of 3D human pose estimation (HPE) is limited by resource-constrained edge devices, requiring more efficient models. A key approach to enhancing efficiency involves designing networks based on the structural characteristics of input data. However, effectively utilizing the structural priors in human skeletal inputs remains challenging. To address this, we leverage both explicit and implicit spatio-temporal priors of the human body through innovative model design and a pre-training proxy task. First, we propose a Nano Human Topology Network (NanoHTNet), a tiny 3D HPE network with stacked Hierarchical Mixers to capture explicit features. Specifically, the spatial Hierarchical Mixer efficiently learns the human physical topology across multiple semantic levels, while the temporal Hierarchical Mixer with discrete cosine transform and low-pass filtering captures local instantaneous movements and global action coherence. Moreover, Efficient Temporal-Spatial Tokenization (ETST) is introduced to enhance spatio-temporal interaction and reduce computational complexity significantly. Second, PoseCLR is proposed as a general pre-training method based on contrastive learning for 3D HPE, aimed at extracting implicit representations of human topology. By aligning 2D poses from diverse viewpoints in the proxy task, PoseCLR aids 3D HPE encoders like NanoHTNet in more effectively capturing the high-dimensional features of the human body, leading to further performance improvements. Extensive experiments verify that NanoHTNet with PoseCLR outperforms other state-of-the-art methods in efficiency, making it ideal for deployment on edge devices like the Jetson Nano. Code and models are available at https://github.com/vefalun/NanoHTNet.