Visual Generation Without Guidance
作者: Huayu Chen, Kai Jiang, Kaiwen Zheng, Jianfei Chen, Hang Su, Jun Zhu
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-01-26 (更新: 2025-08-25)
备注: Accepted to ICML 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出 Guidance-Free Training (GFT),无需引导即可实现高性能视觉生成,降低计算成本。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion)
关键词: 视觉生成 无引导训练 Classifier-Free Guidance 扩散模型 自回归模型
📋 核心要点
- Classifier-Free Guidance (CFG) 虽然有效,但采样时需要同时运行条件和无条件模型,计算成本高。
- 提出 Guidance-Free Training (GFT),通过改进条件模型的参数化方式,实现无需引导的视觉生成。
- 实验表明,GFT 在多个视觉模型上达到与 CFG 相当甚至更好的性能,同时显著降低了计算成本。
📝 摘要(中文)
Classifier-Free Guidance (CFG) 是各种视觉生成模型中的默认技术,但它需要在采样期间从条件模型和无条件模型进行推断。本文提出构建无需引导采样的视觉模型。由此产生的算法 Guidance-Free Training (GFT) 在将采样简化为单个模型的同时,匹配 CFG 的性能,从而将计算成本减半。与之前依赖于预训练 CFG 网络的基于蒸馏的方法不同,GFT 能够直接从头开始训练。GFT 易于实现,它保留了与 CFG 相同的最大似然目标,并且主要在条件模型的参数化方面有所不同。实施 GFT 只需要对现有代码库进行最小的修改,因为大多数设计选择和超参数都直接继承自 CFG。在五个不同的视觉模型上的大量实验证明了 GFT 的有效性和多功能性。在扩散、自回归和掩码预测建模领域,与 CFG 基线相比,GFT 始终如一地实现了相当甚至更低的 FID 分数,以及相似的多样性-保真度权衡,同时无需引导。
🔬 方法详解
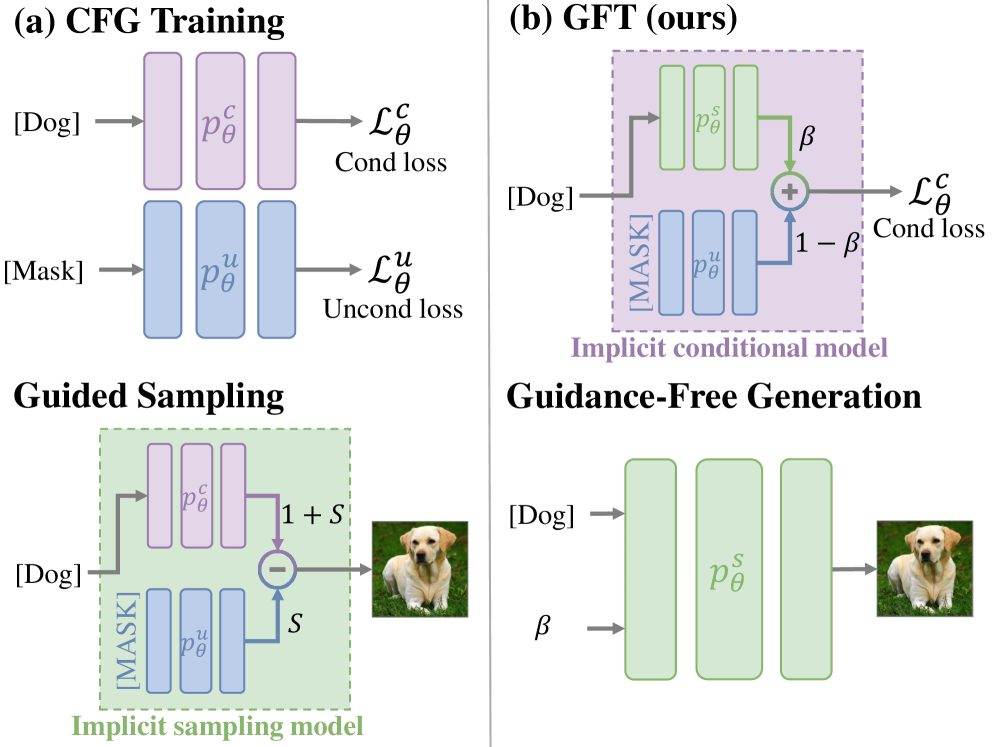
问题定义:现有视觉生成模型,特别是基于扩散模型的模型,广泛采用 Classifier-Free Guidance (CFG) 技术来提升生成质量。然而,CFG 的一个主要痛点在于其采样过程需要同时运行条件模型和无条件模型,这导致计算成本翻倍,限制了其在资源受限场景下的应用。因此,如何在不牺牲生成质量的前提下,降低采样过程的计算复杂度,是本文要解决的核心问题。
核心思路:本文的核心思路是设计一种 Guidance-Free Training (GFT) 方法,该方法通过改进条件模型的参数化方式,使得模型在训练时学习到如何隐式地进行引导,从而在采样阶段无需额外的无条件模型。这样,采样过程只需要运行一次条件模型,即可达到与 CFG 相当甚至更好的生成效果。这种设计旨在将引导信息融入到模型参数中,从而避免了采样时的额外计算开销。
技术框架:GFT 的整体框架与传统的 CFG 训练框架类似,仍然采用最大似然估计作为训练目标。主要的区别在于条件模型的参数化方式。具体来说,GFT 修改了条件模型的输入,使其能够同时接收条件信息和无条件信息,并通过学习到的权重来平衡这两部分信息。在采样阶段,GFT 只需要输入条件信息,模型即可自动生成高质量的图像。
关键创新:GFT 最重要的技术创新点在于其无需引导的训练方式。与以往依赖于预训练 CFG 网络的蒸馏方法不同,GFT 能够直接从头开始训练,避免了对预训练模型的依赖。此外,GFT 通过修改条件模型的参数化方式,将引导信息融入到模型参数中,从而在采样阶段无需额外的计算开销。
关键设计:GFT 的关键设计在于条件模型的输入参数化方式。具体来说,GFT 将条件信息和无条件信息拼接在一起,然后通过一个可学习的权重来平衡这两部分信息。这个权重可以通过反向传播进行优化,从而使得模型能够自动学习到如何隐式地进行引导。此外,GFT 还保留了与 CFG 相同的最大似然目标函数,以及大多数设计选择和超参数,从而使得 GFT 易于实现和部署。
🖼️ 关键图片

📊 实验亮点
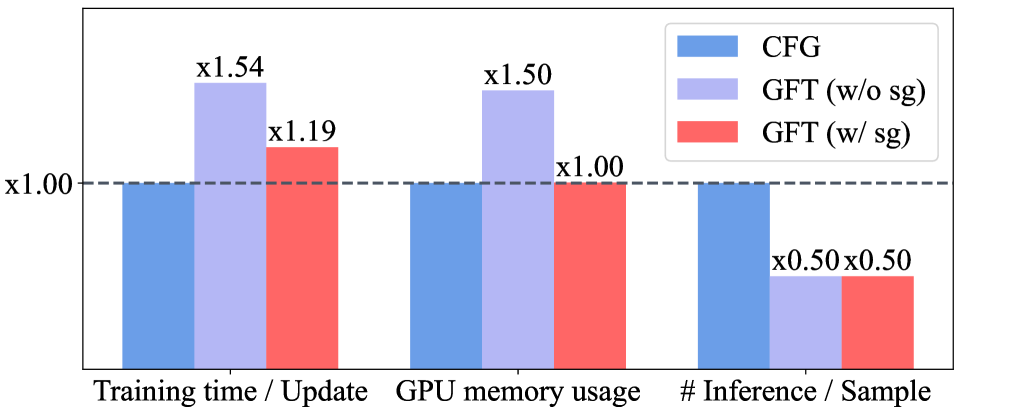
实验结果表明,GFT 在五个不同的视觉模型上,包括扩散模型、自回归模型和掩码预测模型,均取得了与 CFG 相当甚至更好的性能。具体来说,GFT 能够实现与 CFG 相当甚至更低的 FID 分数,同时保持相似的多样性-保真度权衡。最重要的是,GFT 将采样过程的计算成本减半,使其更具实用性。
🎯 应用场景
GFT 具有广泛的应用前景,可应用于图像生成、视频生成、3D 模型生成等领域。由于其降低了采样过程的计算成本,因此特别适用于资源受限的场景,例如移动设备上的图像生成、实时视频编辑等。未来,GFT 有望成为视觉生成模型的一种新的标准训练方法,推动视觉生成技术的发展。
📄 摘要(原文)
Classifier-Free Guidance (CFG) has been a default technique in various visual generative models, yet it requires inference from both conditional and unconditional models during sampling. We propose to build visual models that are free from guided sampling. The resulting algorithm, Guidance-Free Training (GFT), matches the performance of CFG while reducing sampling to a single model, halving the computational cost. Unlike previous distillation-based approaches that rely on pretrained CFG networks, GFT enables training directly from scratch. GFT is simple to implement. It retains the same maximum likelihood objective as CFG and differs mainly in the parameterization of conditional models. Implementing GFT requires only minimal modifications to existing codebases, as most design choices and hyperparameters are directly inherited from CFG. Our extensive experiments across five distinct visual models demonstrate the effectiveness and versatility of GFT. Across domains of diffusion, autoregressive, and masked-prediction modeling, GFT consistently achieves comparable or even lower FID scores, with similar diversity-fidelity trade-offs compared with CFG baselines, all while being guidance-free. Code will be available at https://github.com/thu-ml/GFT.