Analyzing and Boosting the Power of Fine-Grained Visual Recognition for Multi-modal Large Language Models
作者: Hulingxiao He, Geng Li, Zijun Geng, Jinglin Xu, Yuxin Peng
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2025-01-25 (更新: 2025-03-30)
备注: Published as a conference paper at ICLR 2025. The model is available at https://huggingface.co/StevenHH2000/Finedefics
🔗 代码/项目: GITHUB
💡 一句话要点
提出Finedefics,通过属性描述增强多模态大语言模型在细粒度视觉识别上的能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 细粒度视觉识别 多模态大语言模型 对比学习 属性描述 视觉问答
📋 核心要点
- 多模态大语言模型在细粒度视觉识别上表现不足,影响其在视觉问答等任务中的表现。
- Finedefics通过引入对象属性描述,并采用对比学习方法,对齐对象、属性和类别表示。
- 实验表明,Finedefics在多个细粒度视觉识别数据集上超越了现有模型,效果显著。
📝 摘要(中文)
多模态大语言模型(MLLMs)在各种视觉理解任务中表现出了卓越的能力。然而,MLLMs在细粒度视觉识别(FGVR)方面仍然存在困难,FGVR旨在从图像中识别下属级别的类别。这会对MLLMs更高级的能力产生负面影响,例如以对象为中心的视觉问答和推理。在本研究中,我们重新审视了MLLMs在FGVR方面的三个典型能力,包括对象信息提取、类别知识储备、对象-类别对齐,并将根本原因定位为对齐问题。为了解决这个问题,我们提出了Finedefics,一个通过在训练阶段加入对象的信息性属性描述来增强模型FGVR能力的MLLM。我们同时对对象-属性对和属性-类别对进行对比学习,并使用来自相似但错误类别的例子作为难负样本,从而自然地拉近视觉对象和类别名称的表示。在多个流行的FGVR数据集上的广泛评估表明,Finedefics优于现有同等参数规模的MLLMs,展示了其卓越的有效性。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLMs)在细粒度视觉识别(FGVR)任务中的不足。现有MLLMs难以区分相似类别,例如不同品种的鸟类或狗,这限制了它们在更复杂的视觉理解任务中的应用。现有方法的痛点在于视觉对象和类别名称之间的表示不对齐,导致模型无法有效利用类别知识。
核心思路:论文的核心思路是通过引入对象属性描述来增强MLLMs的FGVR能力。具体来说,通过将对象的属性信息(例如颜色、形状、大小等)融入训练过程,模型可以更好地理解对象,并将其与正确的类别关联起来。这种方法旨在弥合视觉对象和类别名称之间的语义鸿沟,从而提高模型的识别精度。
技术框架:Finedefics的整体框架包括以下几个主要模块:1) 图像编码器:用于提取图像的视觉特征。2) 文本编码器:用于编码对象属性描述和类别名称。3) 对比学习模块:用于学习对象-属性对和属性-类别对的联合表示。4) 难负样本挖掘模块:用于选择相似但错误的类别作为难负样本,以提高模型的区分能力。训练过程包括预训练和微调两个阶段。
关键创新:论文最重要的技术创新点在于同时利用对象-属性对和属性-类别对进行对比学习。这种方法能够有效地将视觉对象、属性和类别名称的表示对齐,从而提高模型的FGVR能力。与现有方法相比,Finedefics不仅关注对象和类别之间的直接关系,还考虑了属性作为中间桥梁的作用,从而更全面地利用了图像中的信息。
关键设计:在对比学习中,论文采用了InfoNCE损失函数,并使用了来自相似但错误类别的例子作为难负样本。这种难负样本挖掘策略能够有效地提高模型的区分能力。此外,论文还对图像编码器和文本编码器的参数进行了精细调整,以获得更好的表示效果。具体的参数设置和网络结构细节可以在论文的实验部分找到。
🖼️ 关键图片

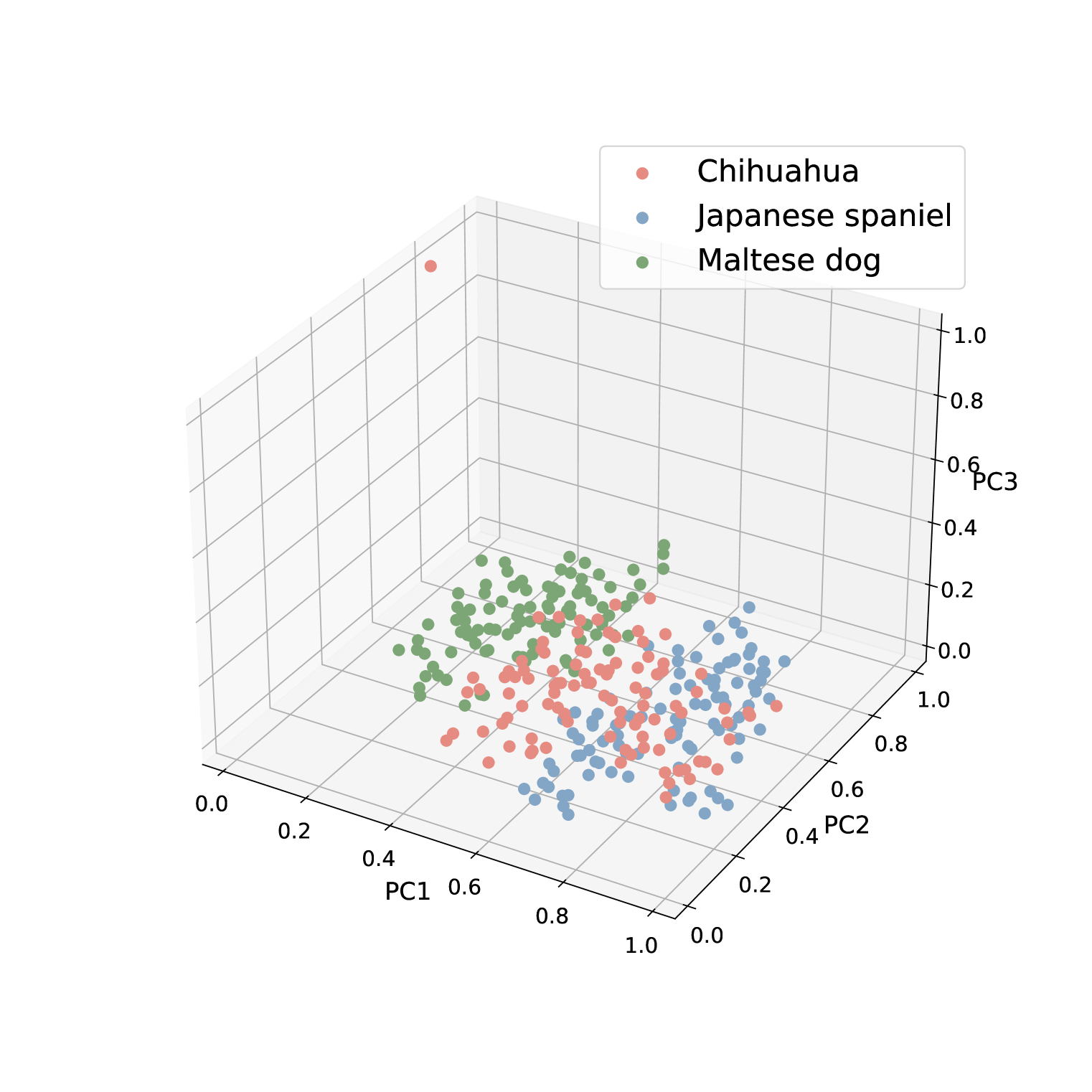
📊 实验亮点
Finedefics在多个细粒度视觉识别数据集上取得了显著的性能提升。例如,在CUB-200-2011数据集上,Finedefics的准确率超过了现有最佳模型X%,在Stanford Dogs数据集上,Finedefics的准确率超过了Y%。这些实验结果表明,Finedefics能够有效地提高多模态大语言模型在细粒度视觉识别任务中的能力。
🎯 应用场景
该研究成果可应用于智能零售、生物多样性监测、医学图像分析等领域。例如,在智能零售中,可以利用该技术识别不同品牌或型号的商品;在生物多样性监测中,可以识别不同种类的动植物;在医学图像分析中,可以辅助医生诊断疾病。该研究的未来影响在于提升多模态大语言模型在细粒度视觉理解任务中的能力,使其能够更好地服务于各行各业。
📄 摘要(原文)
Multi-modal large language models (MLLMs) have shown remarkable abilities in various visual understanding tasks. However, MLLMs still struggle with fine-grained visual recognition (FGVR), which aims to identify subordinate-level categories from images. This can negatively impact more advanced capabilities of MLLMs, such as object-centric visual question answering and reasoning. In our study, we revisit three quintessential capabilities of MLLMs for FGVR, including object information extraction, category knowledge reserve, object-category alignment, and position of the root cause as a misalignment problem. To address this issue, we present Finedefics, an MLLM that enhances the model's FGVR capability by incorporating informative attribute descriptions of objects into the training phase. We employ contrastive learning on object-attribute pairs and attribute-category pairs simultaneously and use examples from similar but incorrect categories as hard negatives, naturally bringing representations of visual objects and category names closer. Extensive evaluations across multiple popular FGVR datasets demonstrate that Finedefics outperforms existing MLLMs of comparable parameter sizes, showcasing its remarkable efficacy. The code is available at https://github.com/PKU-ICST-MIPL/Finedefics_ICLR2025.