Leveraging Motion Estimation for Efficient Bayer-Domain Computer Vision
作者: Haichao Wang, Xinyue Xi, Jiangtao Wen, Yuxing Han
分类: cs.CV, eess.IV
发布日期: 2025-01-25 (更新: 2025-08-14)
💡 一句话要点
提出基于运动估计的Bayer域视频卷积,加速视频视觉任务。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: Bayer域处理 运动估计 视频卷积 低功耗 视频加速
📋 核心要点
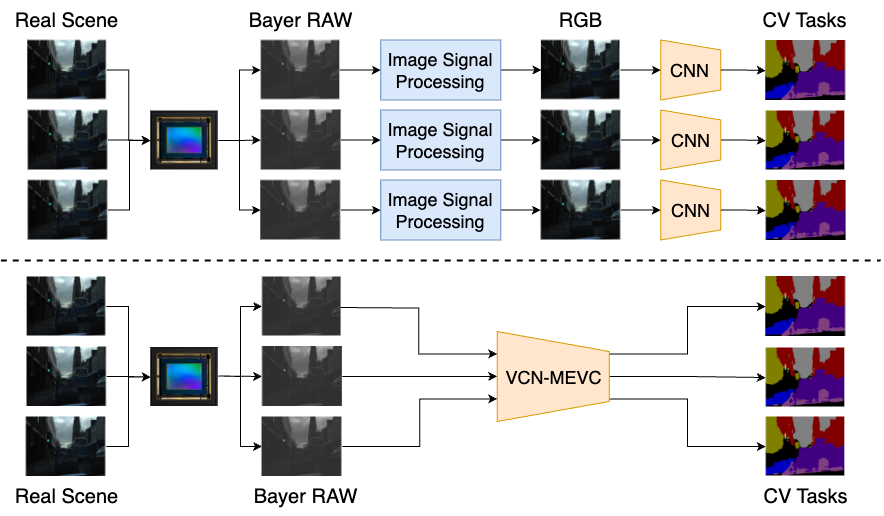
- 传统视频视觉流水线依赖ISP进行Bayer到RGB的转换,以及后续的VCN处理,计算开销大,功耗高,延迟高。
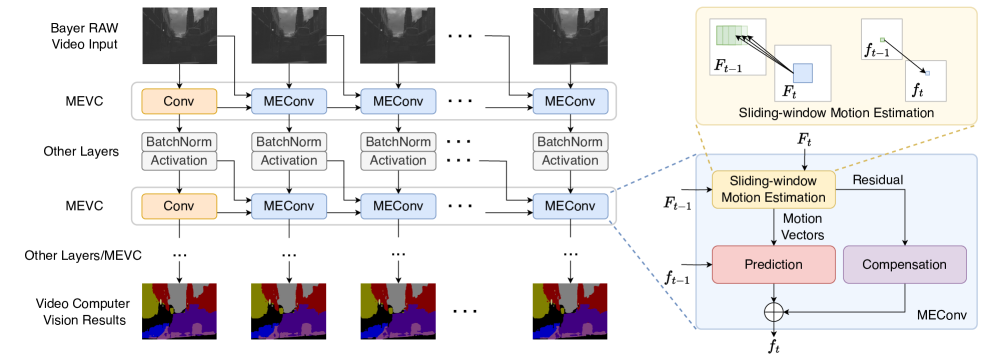
- 论文提出MEVC,将运动估计融入卷积层,通过预测和残差细化减少帧间冗余计算,直接在Bayer域进行处理。
- 实验表明,该方法在视频语义分割、深度估计和目标检测任务中,能显著降低FLOPs,同时保持精度。
📝 摘要(中文)
本文提出了一种新颖的框架,旨在消除图像信号处理器(ISP),并利用运动估计直接在Bayer域中加速视频视觉任务。我们引入了基于运动估计的视频卷积(MEVC),它将滑动窗口运动估计集成到每个卷积层中,从而实现基于预测和残差的细化,减少了跨帧的冗余计算。这种设计弥合了基于块的运动估计和空间卷积之间的结构差距,实现了准确且低成本的处理。我们的端到端流水线支持原始Bayer输入,并在视频语义分割、深度估计和目标检测基准测试中实现了超过70%的FLOPs减少,同时精度损失极小,使用了合成Bayer转换和真实Bayer视频数据集。该框架可推广到基于卷积的模型,并标志着首次有效利用运动估计来直接从原始传感器数据加速视频计算机视觉。
🔬 方法详解
问题定义:现有视频计算机视觉流水线通常需要先将Bayer格式的原始图像数据通过图像信号处理器(ISP)转换为RGB格式,然后再进行后续的视频卷积网络(VCN)处理。ISP和VCN都是计算密集型任务,导致高功耗和高延迟。因此,如何在保证精度的前提下,降低视频视觉任务的计算复杂度是一个关键问题。
核心思路:本文的核心思路是消除ISP,直接在Bayer域上进行视频处理,并利用运动估计来减少帧间的冗余计算。通过将运动估计集成到卷积层中,可以预测当前帧的内容,并仅对预测残差进行处理,从而显著降低计算量。
技术框架:该框架是一个端到端的流水线,直接接收原始Bayer格式的图像数据作为输入。核心模块是Motion Estimation-based Video Convolution (MEVC),它将滑动窗口运动估计集成到每个卷积层中。MEVC首先使用运动估计模块预测当前帧,然后计算预测残差,最后使用卷积层对残差进行处理。整个框架可以应用于各种基于卷积的视频视觉任务,如语义分割、深度估计和目标检测。
关键创新:最重要的技术创新点是将运动估计和卷积操作有机结合,从而实现了在Bayer域上的高效视频处理。与传统的先进行图像重建再进行视觉处理的方法不同,该方法直接在原始数据上进行操作,避免了ISP带来的计算开销和信息损失。此外,MEVC的设计弥合了基于块的运动估计和空间卷积之间的结构差距,使得运动估计能够有效地指导卷积操作。
关键设计:MEVC的关键设计包括滑动窗口运动估计的窗口大小、运动矢量的搜索范围、残差的计算方式以及卷积层的参数设置。具体的参数设置需要根据不同的任务和数据集进行调整。损失函数通常包括预测损失和任务相关的损失,例如语义分割的交叉熵损失、深度估计的L1损失等。网络结构可以采用各种现有的卷积神经网络,如ResNet、U-Net等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在视频语义分割、深度估计和目标检测任务中,与传统方法相比,能够减少超过70%的FLOPs,同时保持了可比的精度。在合成Bayer转换和真实Bayer视频数据集上都取得了显著的性能提升,验证了该方法的有效性和泛化能力。例如,在某个语义分割任务上,FLOPs从100G减少到30G,精度仅下降了1%。
🎯 应用场景
该研究成果可广泛应用于各种需要低功耗、低延迟的视频处理场景,例如移动设备、自动驾驶、监控系统等。通过直接在Bayer域进行处理,可以减少对硬件资源的需求,降低功耗,提高处理速度,从而为这些应用带来显著的性能提升和成本降低。未来,该技术有望进一步推广到其他类型的传感器数据和视觉任务中。
📄 摘要(原文)
Existing computer vision processing pipeline acquires visual information using an image sensor that captures pixel information in the Bayer pattern. The raw sensor data are then processed using an image signal processor (ISP) that first converts Bayer pixel data to RGB on a pixel by pixel basis, followed by video convolutional network (VCN) processing on a frame by frame basis. Both ISP and VCN are computationally expensive with high power consumption and latency. In this paper, we propose a novel framework that eliminates the ISP and leverages motion estimation to accelerate video vision tasks directly in the Bayer domain. We introduce Motion Estimation-based Video Convolution (MEVC), which integrates sliding-window motion estimation into each convolutional layer, enabling prediction and residual-based refinement that reduces redundant computations across frames. This design bridges the structural gap between block-based motion estimation and spatial convolution, enabling accurate, low-cost processing. Our end-to-end pipeline supports raw Bayer input and achieves over 70\% reduction in FLOPs with minimal accuracy degradation across video semantic segmentation, depth estimation, and object detection benchmarks, using both synthetic Bayer-converted and real Bayer video datasets. This framework generalizes across convolution-based models and marks the first effective reuse of motion estimation for accelerating video computer vision directly from raw sensor data.