Complementary Subspace Low-Rank Adaptation of Vision-Language Models for Few-Shot Classification
作者: Zhongqi Wang, Jia Dai, Kai Li, Xu Li, Yanmeng Guo, Maosheng Xiang
分类: cs.CV
发布日期: 2025-01-25
备注: Preprint version
💡 一句话要点
提出互补子空间低秩自适应Comp-LoRA,解决VLM少样本分类中的灾难性遗忘问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 少样本学习 低秩自适应 参数高效微调 灾难性遗忘
📋 核心要点
- 现有VLM的LoRA微调在少样本学习中存在灾难性遗忘问题,影响模型泛化能力。
- 提出Comp-LoRA方法,在互补子空间优化低秩矩阵,保留VLM的视觉语言对齐能力。
- 实验表明,Comp-LoRA在少样本分类中优于基线方法,并有效抑制了灾难性遗忘。
📝 摘要(中文)
视觉语言模型(VLM)已被设计用于大规模图像-文本对齐,作为预训练的基础模型。对于下游的少样本分类任务,参数高效微调(PEFT) VLM在计算机视觉领域越来越受欢迎。诸如prompt tuning和线性适配器等PEFT方法已被研究用于微调VLM,而低秩自适应(LoRA)算法很少被考虑用于少样本微调VLM。使用LoRA进行少样本微调的主要障碍是灾难性遗忘问题。由于视觉语言对齐知识对于少样本学习的泛化性非常重要,而低秩自适应会干扰预训练权重矩阵中最具信息量的方向。我们提出了互补子空间低秩自适应(Comp-LoRA)方法来抑制少样本VLM微调中的灾难性遗忘问题。具体来说,我们在互补子空间中优化低秩矩阵,从而在学习新的少样本信息时,保留VLM的通用视觉语言对齐能力。我们进行了比较实验,将提出的Comp-LoRA方法与其他PEFT方法在微调VLM用于少样本分类上进行了比较。并且,我们还展示了我们提出的方法相对于直接将LoRA应用于VLM,在抑制灾难性遗忘问题上的优势。结果表明,所提出的方法比基线方法提高了约+1.0%的Top-1准确率,并且比基线方法保留了VLM零样本性能约+1.3%的Top-1准确率。
🔬 方法详解
问题定义:论文旨在解决视觉语言模型(VLM)在少样本分类任务中使用低秩自适应(LoRA)进行微调时出现的灾难性遗忘问题。直接应用LoRA会干扰VLM预训练的视觉语言对齐知识,导致模型在学习新任务时忘记了原有的泛化能力,从而影响少样本学习的性能。
核心思路:论文的核心思路是在互补子空间中进行低秩矩阵的优化。这意味着在更新模型参数时,并非直接修改原始权重矩阵,而是在与原始权重矩阵信息量最大的方向正交的子空间中进行调整。这样可以在学习新任务知识的同时,尽可能保留VLM预训练的视觉语言对齐能力,从而减轻灾难性遗忘。
技术框架:Comp-LoRA方法的技术框架主要包括以下几个步骤:1. 选择VLM模型作为基础模型。2. 在VLM模型的特定层(例如,Transformer层的权重矩阵)上应用LoRA。3. 关键在于,LoRA的低秩矩阵的优化被限制在与该层预训练权重矩阵的“重要”方向互补的子空间中。4. 使用少样本数据集对模型进行微调。5. 在测试集上评估模型性能。
关键创新:Comp-LoRA的关键创新在于其互补子空间优化策略。与直接应用LoRA不同,Comp-LoRA通过限制低秩矩阵的优化空间,避免了对VLM预训练知识的过度干扰。这种方法能够更好地平衡新任务学习和知识保留,从而提高少样本学习的性能。本质区别在于,传统LoRA直接修改预训练权重,而Comp-LoRA在不影响主要信息方向的前提下进行调整。
关键设计:Comp-LoRA的关键设计在于如何确定和利用互补子空间。论文可能采用某种方法来估计预训练权重矩阵的“重要”方向(例如,通过奇异值分解),然后将低秩矩阵的优化限制在与这些方向正交的子空间中。具体的损失函数可能包括一个标准的分类损失项,以及一个用于正则化低秩矩阵,使其保持在互补子空间中的正则化项。具体的参数设置(例如,低秩矩阵的秩、正则化系数)需要根据实验进行调整。
🖼️ 关键图片
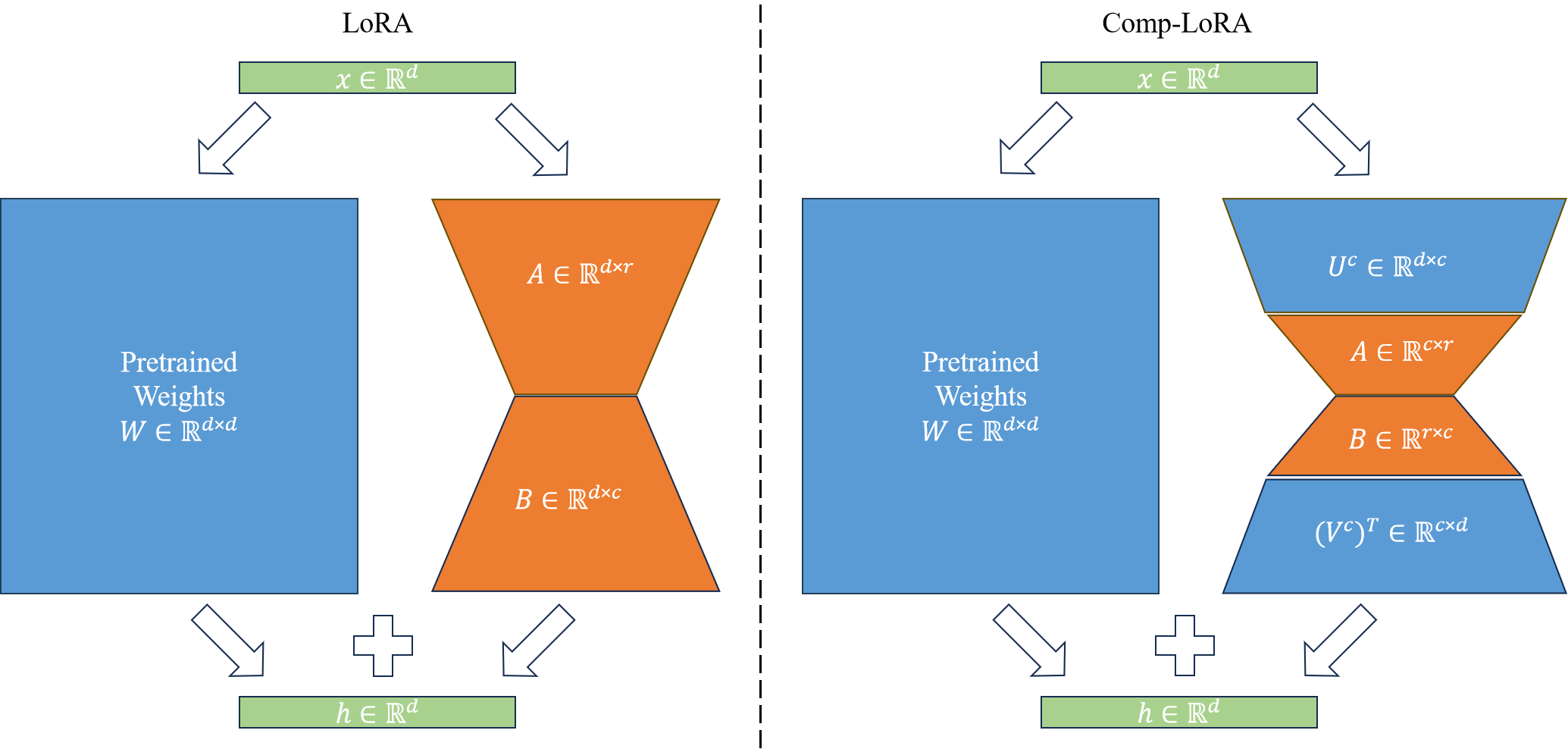
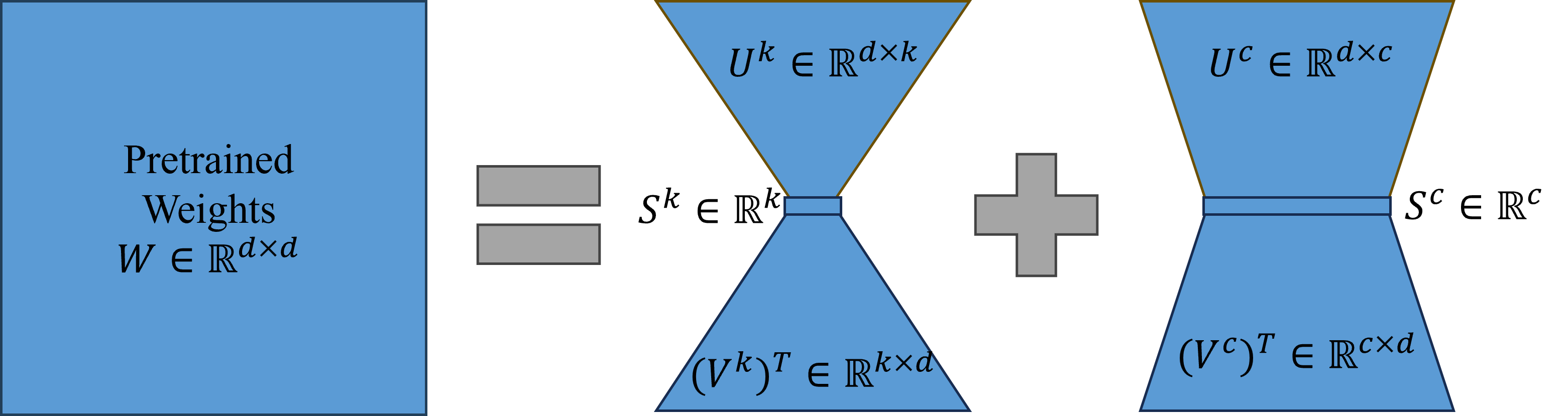

📊 实验亮点
实验结果表明,Comp-LoRA方法在少样本分类任务中取得了显著的性能提升,Top-1准确率比基线方法提高了约1.0%。更重要的是,Comp-LoRA能够更好地保留VLM的零样本性能,Top-1准确率比基线方法提高了约1.3%,这表明Comp-LoRA能够有效抑制灾难性遗忘问题。
🎯 应用场景
Comp-LoRA方法可应用于各种视觉语言模型的少样本分类任务,例如图像分类、目标检测和图像描述等。该方法能够提高模型在数据稀缺场景下的泛化能力,降低对大量标注数据的依赖,具有重要的实际应用价值。未来,该方法可以进一步扩展到其他类型的预训练模型和下游任务中。
📄 摘要(原文)
Vision language model (VLM) has been designed for large scale image-text alignment as a pretrained foundation model. For downstream few shot classification tasks, parameter efficient fine-tuning (PEFT) VLM has gained much popularity in the computer vision community. PEFT methods like prompt tuning and linear adapter have been studied for fine-tuning VLM while low rank adaptation (LoRA) algorithm has rarely been considered for few shot fine-tuning VLM. The main obstacle to use LoRA for few shot fine-tuning is the catastrophic forgetting problem. Because the visual language alignment knowledge is important for the generality in few shot learning, whereas low rank adaptation interferes with the most informative direction of the pretrained weight matrix. We propose the complementary subspace low rank adaptation (Comp-LoRA) method to regularize the catastrophic forgetting problem in few shot VLM finetuning. In detail, we optimize the low rank matrix in the complementary subspace, thus preserving the general vision language alignment ability of VLM when learning the novel few shot information. We conduct comparison experiments of the proposed Comp-LoRA method and other PEFT methods on fine-tuning VLM for few shot classification. And we also present the suppression on the catastrophic forgetting problem of our proposed method against directly applying LoRA to VLM. The results show that the proposed method surpasses the baseline method by about +1.0\% Top-1 accuracy and preserves the VLM zero-shot performance over the baseline method by about +1.3\% Top-1 accuracy.