Measuring and Mitigating Hallucinations in Vision-Language Dataset Generation for Remote Sensing
作者: Madeline Anderson, Miriam Cha, William T. Freeman, J. Taylor Perron, Nathaniel Maidel, Kerri Cahoy
分类: cs.CV
发布日期: 2025-01-24
💡 一句话要点
提出融合地图信息的遥感图像-文本数据集生成方法,缓解幻觉问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 遥感图像 视觉语言模型 数据集生成 地图信息融合 幻觉缓解 自动目标识别 多模态学习
📋 核心要点
- 遥感领域缺乏图像-文本配对数据,现有方法(如基于规则的字幕生成)难以捕捉复杂场景。
- 该论文提出一种新方法,通过整合地图信息作为外部数据源,利用大型语言模型生成更详细、上下文丰富的遥感图像字幕。
- 论文构建了fMoW-mm多模态数据集,实验表明该数据集在少样本目标识别任务中优于其他遥感视觉语言数据集。
📝 摘要(中文)
视觉语言模型在各个领域都取得了显著成果。然而,由于缺乏配对的图像-文本数据,其在遥感领域的应用仍然有限。为了弥合这一差距,合成字幕生成越来越受到关注,传统上依赖于使用元数据或边界框的基于规则的方法。虽然这些方法提供了一些描述,但它们通常缺乏捕捉复杂广域场景所需的深度。大型语言模型(LLM)为生成更具描述性的字幕提供了一个有希望的替代方案,但它们可能会产生通用输出并且容易产生幻觉。在本文中,我们提出了一种新方法,通过整合地图作为外部数据源来增强遥感视觉语言数据集,从而能够生成详细的、上下文丰富的字幕。此外,我们还提出了测量和减轻LLM生成文本中幻觉的方法。我们介绍了fMoW-mm,一个包含卫星图像、地图、元数据和文本注释的多模态数据集。我们证明了它在少样本设置中自动目标识别方面的有效性,与其他视觉语言遥感数据集相比,实现了卓越的性能。
🔬 方法详解
问题定义:遥感领域缺乏高质量的图像-文本配对数据集,这限制了视觉语言模型在该领域的应用。现有的基于规则的方法或使用元数据/边界框的方法生成的字幕过于简单,无法充分描述复杂的遥感场景。直接使用大型语言模型(LLM)生成字幕容易产生幻觉,即生成与图像内容不符的信息。
核心思路:核心思路是利用地图信息作为外部知识源,为LLM提供更丰富的上下文信息,从而生成更准确、更详细的遥感图像字幕。通过融合地图信息,可以减少LLM的幻觉,并提高生成字幕的质量。
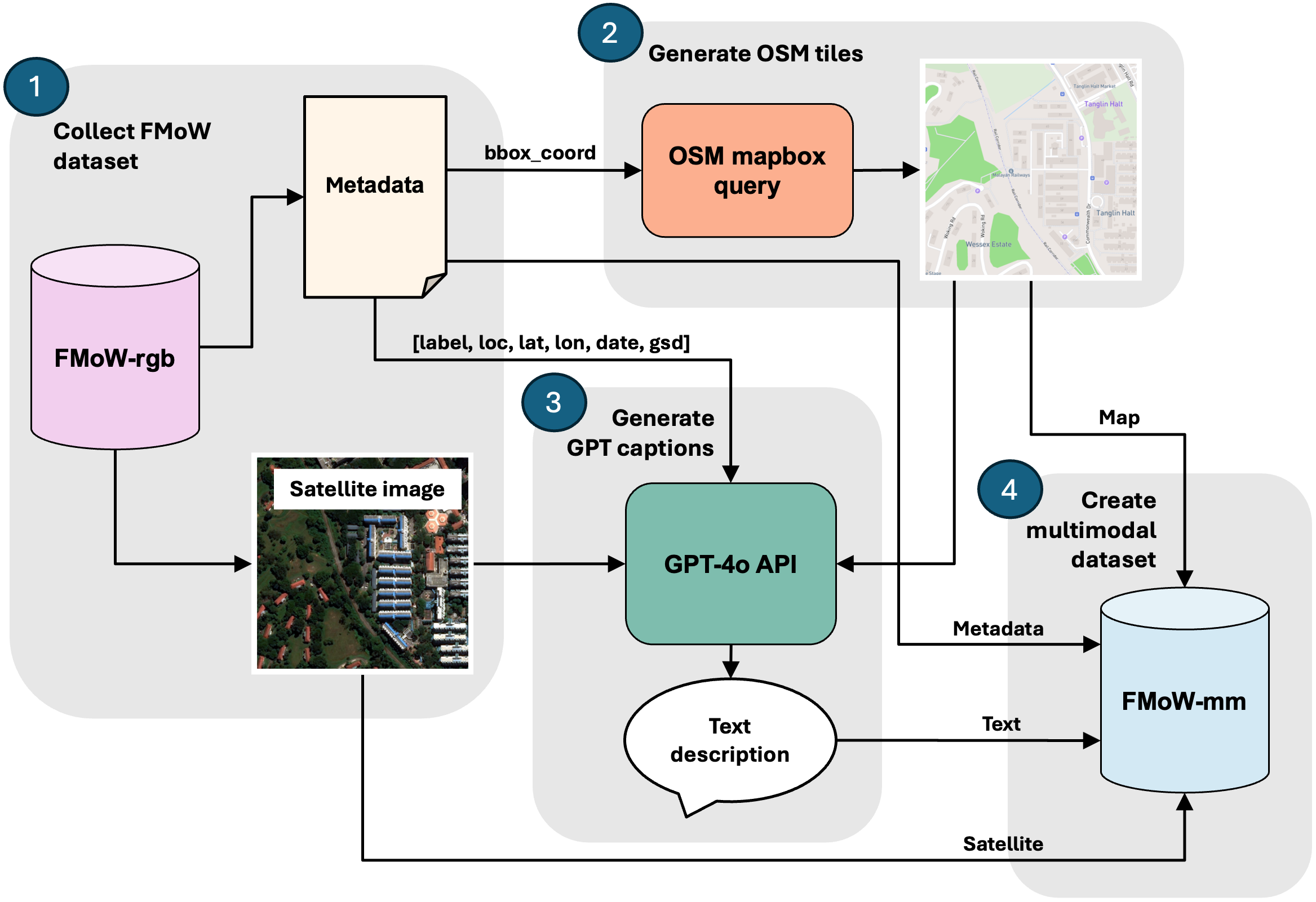
技术框架:该方法主要包含以下几个阶段:1) 数据收集:收集卫星图像、对应的地图数据(例如,土地利用类型、道路网络等)和元数据。2) 特征提取:从卫星图像和地图数据中提取视觉特征。3) 上下文融合:将图像特征、地图特征和元数据融合在一起,形成LLM的输入上下文。4) 字幕生成:使用LLM生成遥感图像的字幕。5) 幻觉缓解:采用特定的技术来测量和减轻LLM生成的文本中的幻觉。
关键创新:关键创新在于将地图信息作为外部知识源融入到遥感图像字幕生成过程中。这使得LLM能够利用地图提供的地理信息和上下文信息,生成更准确、更详细的字幕,从而缓解了LLM的幻觉问题。此外,论文还提出了测量和减轻幻觉的方法。
关键设计:论文构建了fMoW-mm数据集,该数据集包含卫星图像、地图、元数据和文本注释。具体的技术细节包括:如何从地图数据中提取有效的特征,如何将地图特征与图像特征进行融合,以及如何设计损失函数来鼓励LLM生成更准确的字幕。关于幻觉缓解,具体的技术细节未知。
🖼️ 关键图片


📊 实验亮点
论文构建了fMoW-mm多模态数据集,并在少样本自动目标识别任务中进行了实验。实验结果表明,使用fMoW-mm数据集训练的模型性能优于其他遥感视觉语言数据集,验证了该方法在增强遥感图像-文本数据集方面的有效性。具体的性能提升数据未知。
🎯 应用场景
该研究成果可应用于遥感图像的自动解译、目标识别、变化检测等领域。高质量的遥感图像-文本数据集能够提升视觉语言模型在遥感领域的性能,为环境监测、灾害评估、城市规划等应用提供更强大的技术支持。未来,该方法可以扩展到其他类型的遥感数据,例如高光谱图像、LiDAR数据等。
📄 摘要(原文)
Vision language models have achieved impressive results across various fields. However, adoption in remote sensing remains limited, largely due to the scarcity of paired image-text data. To bridge this gap, synthetic caption generation has gained interest, traditionally relying on rule-based methods that use metadata or bounding boxes. While these approaches provide some description, they often lack the depth needed to capture complex wide-area scenes. Large language models (LLMs) offer a promising alternative for generating more descriptive captions, yet they can produce generic outputs and are prone to hallucination. In this paper, we propose a new method to enhance vision-language datasets for remote sensing by integrating maps as external data sources, enabling the generation of detailed, context-rich captions. Additionally, we present methods to measure and mitigate hallucinations in LLM-generated text. We introduce fMoW-mm, a multimodal dataset incorporating satellite imagery, maps, metadata, and text annotations. We demonstrate its effectiveness for automatic target recognition in few-shot settings, achieving superior performance compared to other vision-language remote sensing datasets.