Dynamic Token Reduction during Generation for Vision Language Models
作者: Xiaoyu Liang, Chaofeng Guan, Jiaying Lu, Huiyao Chen, Huan Wang, Haoji Hu
分类: cs.CV, cs.AI
发布日期: 2025-01-24
💡 一句话要点
提出动态速率(DyRate)方法,解决视觉语言模型生成过程中视觉token冗余问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 动态剪枝 token压缩 注意力机制 自回归生成
📋 核心要点
- 现有VLM方法在减少视觉token冗余方面存在不足,主要集中在单次前向传播,缺乏对生成全程的系统分析。
- DyRate通过动态调整压缩率,更激进地剪枝不重要的视觉token,从而降低计算复杂度并保持生成质量。
- 实验结果表明,DyRate在降低计算需求的同时,能够维持甚至提升视觉语言模型的响应质量。
📝 摘要(中文)
视觉语言模型(VLMs)在多模态任务中取得了显著成功,但由于解码器注意力机制和自回归生成的二次复杂度,面临着实际的局限性。现有的方法如FASTV和VTW在减少冗余视觉token方面取得了显著成果,但这些方法侧重于在单个前向传递中修剪token,而没有系统地分析整个生成过程中视觉token的冗余性。本文提出了一种为VLMs量身定制的动态剪枝策略,名为动态速率(DyRate),它在生成过程中逐步调整压缩率。我们对注意力分布的分析表明,视觉token的重要性在整个生成过程中都在降低,这启发我们采用更激进的压缩率。通过集成一个基于注意力分布的轻量级预测器,我们的方法能够根据注意力分布灵活地调整剪枝率。实验结果表明,该方法不仅降低了计算需求,而且保持了响应的质量。
🔬 方法详解
问题定义:视觉语言模型在生成过程中,解码器注意力机制的计算复杂度是平方级的,导致计算成本高昂。现有方法如FASTV和VTW虽然能减少视觉token的数量,但它们主要关注单次前向传播,忽略了视觉token在整个生成过程中的重要性变化,无法充分利用视觉token的冗余性。
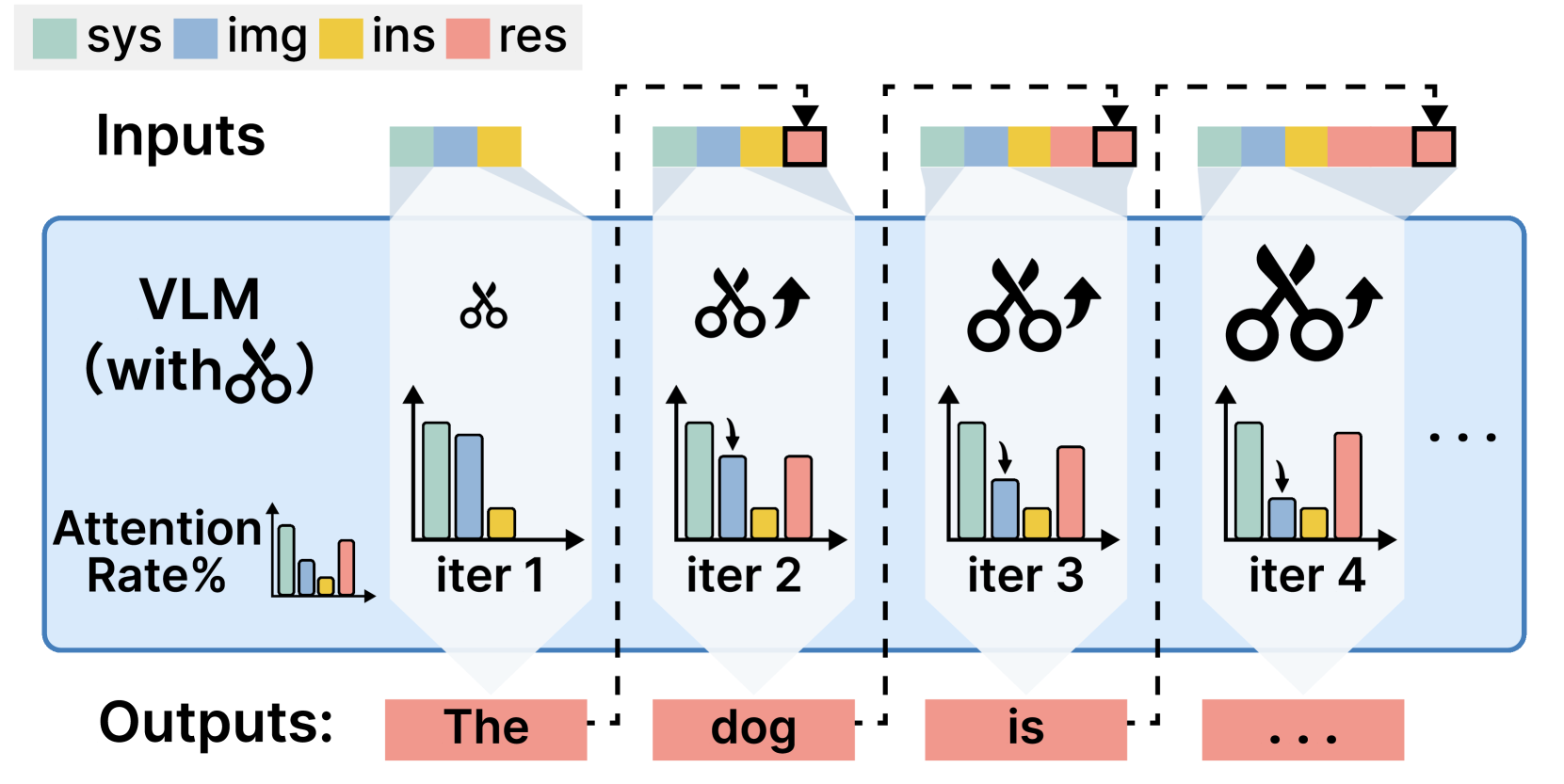
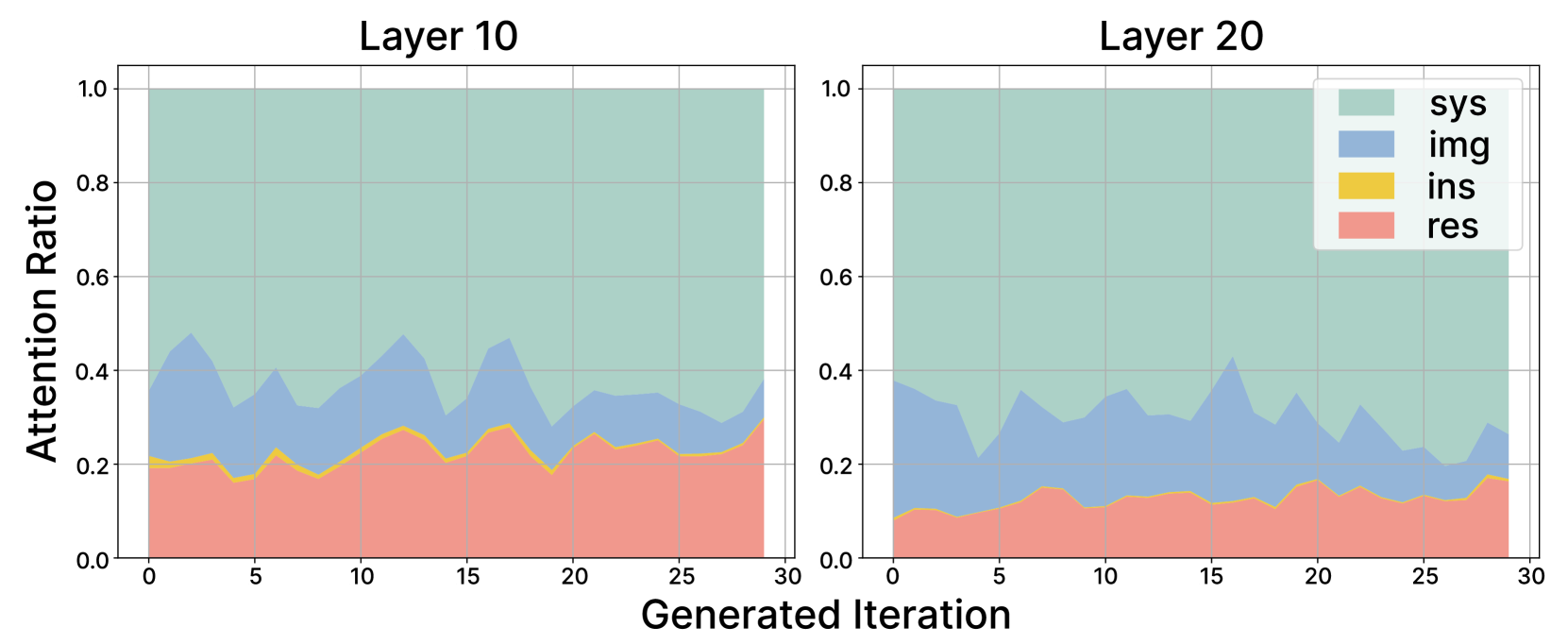
核心思路:论文的核心思路是,视觉token的重要性在生成过程中会逐渐降低。因此,可以动态地调整视觉token的压缩率,在生成初期保留更多信息,在生成后期更激进地剪枝不重要的token,从而在保证生成质量的前提下,降低计算复杂度。
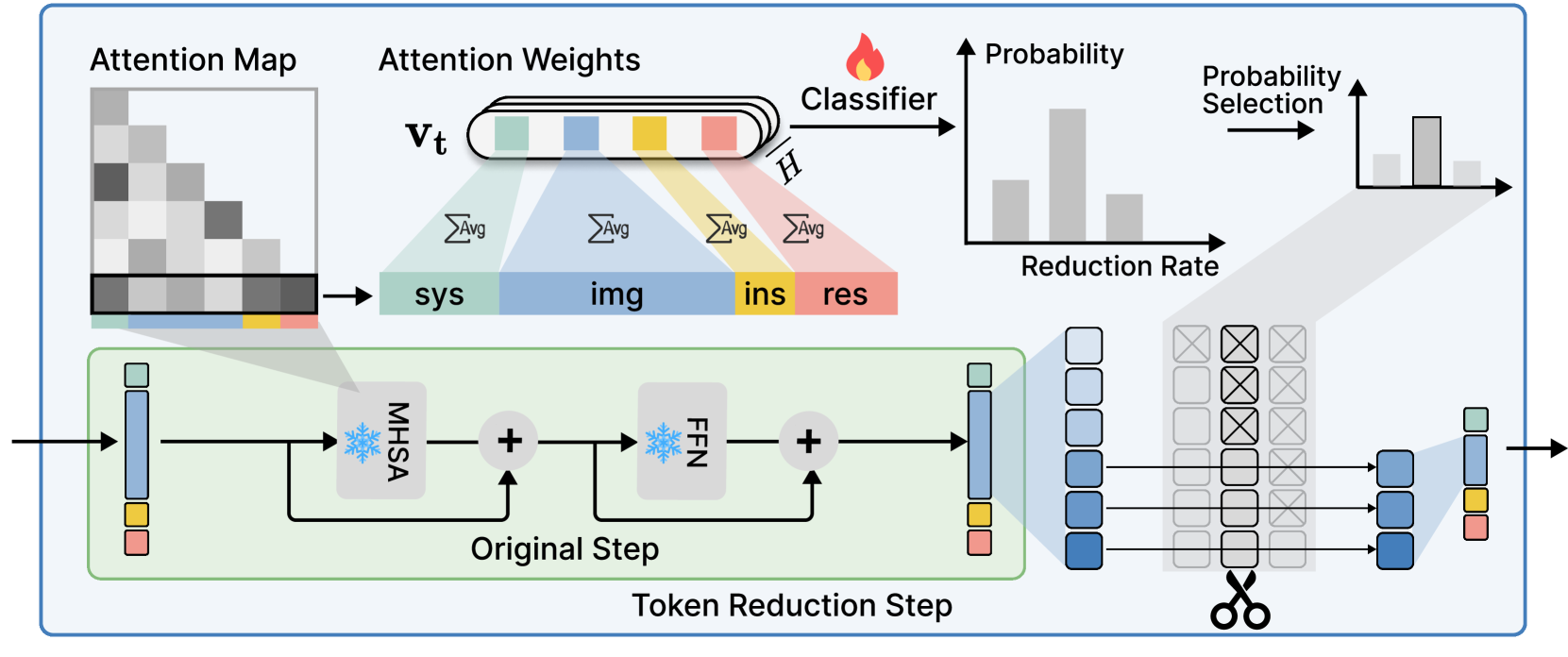
技术框架:DyRate方法主要包含一个轻量级的预测器,该预测器基于注意力分布来预测每个视觉token的重要性。在生成过程的每一步,预测器会根据当前的注意力分布,动态地调整视觉token的压缩率。压缩率越高,被剪枝的token就越多。整个框架与现有的VLM模型兼容,可以方便地集成到各种VLM架构中。
关键创新:DyRate的关键创新在于动态调整压缩率。与现有方法采用固定的压缩率不同,DyRate能够根据生成过程中的注意力分布,自适应地调整压缩率,从而更有效地利用视觉token的冗余性。这种动态调整的策略使得DyRate能够在降低计算复杂度的同时,保持甚至提升生成质量。
关键设计:DyRate的关键设计包括:1) 基于注意力分布的轻量级预测器,用于预测视觉token的重要性;2) 动态压缩率调整策略,根据预测的重要性自适应地调整压缩率;3) 损失函数的设计,用于训练预测器,使其能够准确地预测视觉token的重要性。具体的网络结构和参数设置在论文中有详细描述,但摘要中未提供。
🖼️ 关键图片
📊 实验亮点
论文提出的DyRate方法在降低计算需求的同时,保持了响应的质量。具体实验数据未知,但摘要强调该方法通过动态调整压缩率,能够更有效地利用视觉token的冗余性,从而在降低计算复杂度的同时,维持甚至提升生成质量。与现有方法相比,DyRate在性能和效率之间取得了更好的平衡。
🎯 应用场景
该研究成果可广泛应用于各种视觉语言模型,尤其是在资源受限的场景下,如移动设备或边缘计算平台。通过降低计算复杂度,DyRate能够使VLM在这些平台上更高效地运行,从而拓展VLM的应用范围,例如智能助手、图像描述、视觉问答等。
📄 摘要(原文)
Vision-Language Models (VLMs) have achieved notable success in multimodal tasks but face practical limitations due to the quadratic complexity of decoder attention mechanisms and autoregressive generation. Existing methods like FASTV and VTW have achieved notable results in reducing redundant visual tokens, but these approaches focus on pruning tokens in a single forward pass without systematically analyzing the redundancy of visual tokens throughout the entire generation process. In this paper, we introduce a dynamic pruning strategy tailored for VLMs, namedDynamic Rate (DyRate), which progressively adjusts the compression rate during generation. Our analysis of the distribution of attention reveals that the importance of visual tokens decreases throughout the generation process, inspiring us to adopt a more aggressive compression rate. By integrating a lightweight predictor based on attention distribution, our approach enables flexible adjustment of pruning rates based on the attention distribution. Our experimental results demonstrate that our method not only reduces computational demands but also maintains the quality of responses.