Revisiting CLIP: Efficient Alignment of 3D MRI and Tabular Data using Domain-Specific Foundation Models
作者: Jakob Krogh Petersen, Valdemar Licht, Mads Nielsen, Asbjørn Munk
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-01-23
备注: 10 pages, 2 figures. To be published in ISBI 2025
💡 一句话要点
提出一种基于领域特定3D基础模型的MRI与表格数据高效对齐方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D MRI 多模态学习 CLIP 对比学习 医学图像分析 领域特定模型 零样本分类
📋 核心要点
- 现有CLIP方法在医学领域面临3D数据和表格数据处理的挑战,且需要大量样本。
- 论文提出训练领域特定的3D基础模型,并采用嵌入累积策略来稳定3D训练,实现模态对齐。
- 实验表明,该方法在少量MRI数据下,能有效对齐3D MRI与表格数据,并在零样本分类上取得进展。
📝 摘要(中文)
多模态模型需要对齐的、共享的嵌入空间。然而,常见的基于CLIP的方法需要大量的样本,并且本身不支持3D或表格数据,而这两者在医学领域至关重要。为了解决这些问题,我们重新审视了CLIP风格的对齐,通过训练一个领域特定的3D基础模型作为图像编码器,证明了仅用62个MRI扫描就可以实现模态对齐。我们的方法得益于一个简单的嵌入累积策略,该策略是3D训练所必需的,它可以扩展批次间的负样本对的数量,从而稳定训练。我们对各种设计选择进行了全面的评估,包括骨干网络和损失函数的选择,并在零样本分类和图像检索任务中评估了所提出的方法。虽然零样本图像检索仍然具有挑战性,但零样本分类结果表明,所提出的方法可以有意义地对齐3D MRI和表格数据的表示。
🔬 方法详解
问题定义:论文旨在解决医学领域中3D MRI图像数据和表格数据对齐的问题。现有基于CLIP的方法需要大量数据,且无法直接处理3D数据和表格数据,限制了其在医学图像分析中的应用。因此,如何利用少量数据实现3D MRI图像和表格数据的有效对齐是本研究要解决的核心问题。
核心思路:论文的核心思路是训练一个领域特定的3D基础模型作为图像编码器,并结合CLIP的对比学习框架,将3D MRI图像和表格数据映射到共享的嵌入空间。通过领域特定的预训练和嵌入累积策略,可以在少量数据下实现有效的模态对齐。
技术框架:整体框架包括三个主要部分:1) 3D MRI图像编码器:使用3D卷积神经网络(如3D ResNet)作为图像编码器,将3D MRI图像转换为嵌入向量。2) 表格数据编码器:使用多层感知机(MLP)或Transformer等模型将表格数据转换为嵌入向量。3) 对比学习:使用对比学习损失函数(如InfoNCE)来训练模型,使得来自同一患者的MRI图像和表格数据的嵌入向量在嵌入空间中更接近,而来自不同患者的嵌入向量更远离。嵌入累积策略用于稳定3D训练。
关键创新:论文的关键创新在于:1) 提出了一个领域特定的3D基础模型,专门用于处理3D MRI图像。2) 提出了嵌入累积策略,解决了3D训练中负样本不足的问题,稳定了训练过程。3) 证明了在少量数据下,通过领域特定的预训练和嵌入累积策略,可以实现有效的模态对齐。
关键设计:在网络结构方面,图像编码器可以选择不同的3D卷积神经网络,如3D ResNet或VNet。表格数据编码器可以选择MLP或Transformer。损失函数通常采用InfoNCE损失,用于最大化正样本对之间的相似性,最小化负样本对之间的相似性。嵌入累积策略通过在每个批次中累积多个负样本对,来增加负样本的数量,从而稳定训练。具体的参数设置需要根据数据集和任务进行调整。
🖼️ 关键图片
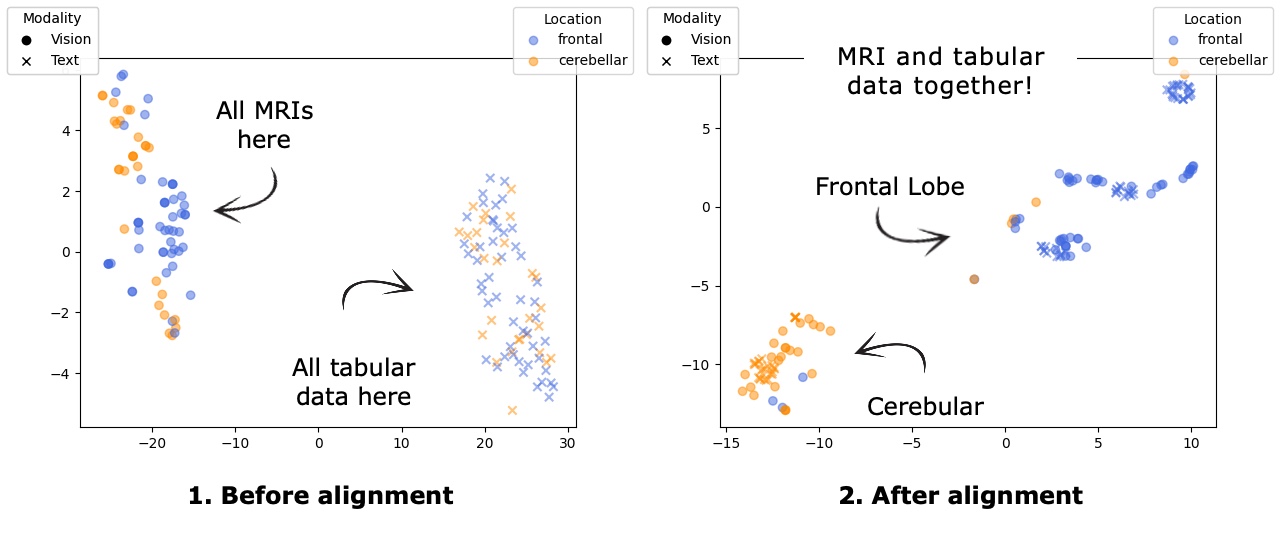

📊 实验亮点
实验结果表明,该方法在仅使用62个MRI扫描的情况下,实现了3D MRI图像和表格数据的有效对齐。在零样本分类任务中,该方法取得了有意义的结果,证明了其能够学习到有用的跨模态表示。虽然零样本图像检索仍然具有挑战性,但该研究为医学图像多模态学习提供了一个新的思路。
🎯 应用场景
该研究成果可应用于医学图像报告生成、疾病诊断和预测、以及个性化医疗等领域。通过将MRI图像和患者的临床信息对齐,可以辅助医生进行更准确的诊断,并为患者提供更个性化的治疗方案。未来,该方法可以扩展到其他医学影像模态和临床数据类型,构建更强大的多模态医学人工智能系统。
📄 摘要(原文)
Multi-modal models require aligned, shared embedding spaces. However, common CLIP-based approaches need large amounts of samples and do not natively support 3D or tabular data, both of which are crucial in the medical domain. To address these issues, we revisit CLIP-style alignment by training a domain-specific 3D foundation model as an image encoder and demonstrate that modality alignment is feasible with only 62 MRI scans. Our approach is enabled by a simple embedding accumulation strategy required for training in 3D, which scales the amount of negative pairs across batches in order to stabilize training. We perform a thorough evaluation of various design choices, including the choice of backbone and loss functions, and evaluate the proposed methodology on zero-shot classification and image-retrieval tasks. While zero-shot image-retrieval remains challenging, zero-shot classification results demonstrate that the proposed approach can meaningfully align the representations of 3D MRI with tabular data.